SQLExceptonResultSetRowSet-objekter: typer og egenskaperCachedRowSetRowSet-hendelserRowSet i en JTable
executeUpdateJDBC er forkortelse for Java Database Connectivity. Det er et API
(grensesnitt) som gjĝr det mulig for et javaprogram ċ kommunisere med
en database. JDBC bestċr av mange klasser og
interface'er, samlet i pakken
java.sql.
Ved hjelp av disse
klassene sender javaprogrammet SQL-setninger til databasen og fċr respons
tilbake.
De forskjellige databasesystemene som finnes pċ markedet har alle sitt eget API (grensesnitt) mot omverdenen. Dette er vanligvis ikke skrevet i java, men for eksempel i C. Vi trenger derfor noe som kan ta imot vċre JDBC-kall og omforme dem til metodekall som passer med det databasesystemet vi skal bruke. En slik omformer kalles en databasedriver.
En tilsvarende problemstilling gjĝr seg gjeldende nċr det gjelder plattformen Microsoft Windows. Programvaren ODBC (Open Database Connectivity) gjĝr det mulig for Microsoft Windows ċ kommunisere med nĉr sagt et hvilket som helst databasesystem pċ markedet. Dersom vi kjĝrer java pċ Microsoft Windows, betyr dette at dersom vi fċr javaprogrammet vċrt til ċ kommunisere med ODBC, sċ vil veien vĉre ċpen til en stor mengde databasesystemer.
Databasedriverne er av to hovedtyper:
En driver av den fĝrste typen fĝlger med som en del av selve javaplattformen Java SE. Driveren krever at tilhĝrende ODBC-driver er installert pċ maskinen der javaprogrammet skal bli utfĝrt. Det er en grei lĝsning dersom man bare skal eksperimentere med JDBC. Men for profesjonell bruk bĝr man bruke andre drivere. Det finnes drivere som er tilpasset de aller fleste databasehċndteringssystemer som finnes pċ markedet. I JDBC-spesifikasjonen blir driverne klassifisert i fĝlgende fire typer:
De fleste databaseleverandĝrer tilbyr en driver av type 3 eller 4 sammen med sin database. I tillegg er det mange tredjepartsselskaper som har spesialisert seg i ċ utvikle drivere som har bedre tilpasning, har stĝtte for flere plattformer, og har bedre ytelse, eller, i noen tilfeller, kort og godt har bedre pċlitelighet enn driverne som blir tilbudt av databaseleverandĝren. En sĝkeside for opplysninger om tilgjengelige drivere finnes pċ nettadressen http://devapp.sun.com/product/jdbc/drivers. En del informasjon om JDBC og Javas databaseteknologi finnes pċ adressen http://www.oracle.com/technetwork/java/javase/tech/index-jsp-136101.html.
For databasetypen MySQL finnes driveren Connector/J. Det er en driver av Type 4.
Det som ĝnskes oppnċdd ved hjelp av JDBC kan vi kort summere opp pċ fĝlgende mċte:
En kan kanskje lure pċ hvorfor Sun, som var den opprinnelige javautvikleren, ikke valgte ċ bygge pċ ODBC-modellen, iallfall for programmer som skal kjĝres pċ Windows-plattform. Pċ JavaOne-konferansen i mai 1996 ble dette begrunnet med fĝlgende:
void-pekere
og andre C-teknikker som det ikke er naturlig ċ bruke i java.JDBC kan brukes i bċde applikasjoner og appleter. For appleter gjelder imidlertid de vanlige sikkerhetsbegrensningene. Det betyr i dette tilfelle at appleter som bruker JDBC bare kan ċpne en databaseforbindelse til serveren som de selv hentes fra. Det betyr at nettserveren og databaseserveren mċ vĉre pċ samme maskin, noe som ikke er et typisk oppsett. Applikasjoner derimot, har full frihet til ċ aksessere fjerne databaseservere. Dersom en skal lage et tradisjonelt klient/server-program, er det derfor mest aktuelt ċ bruke et program av type applikasjon for databaseaksess. Klienten kommuniserer da direkte med databasen via JDBC. Tendensen nċ til dags er imidlertid at en gċr bort fra klient/server-modellen og over til en modell som bestċr av tre eller flere lag. I en trelagsmodell vil ikke klienten gjĝre databasekall. Isteden gjĝr klienten kall pċ et lag i midten, som i sin tur foretar databasekallene. Dette gir et mer fleksibelt opplegg pċ den mċten at det midterste laget kan kontaktes pċ forskjellig mċte, uavhengig av kommunikasjonen som dette har med databasen. For denne kommunikasjonen kan en bruke JDBC. Den vanligste mċten ċ kommunisere pċ fra klient til det midterste laget, er ċ bruke http-protokollen via nettlesere. Dette kan derfor kombineres med bruk av appleter, siden slike kan inngċ i html-dokumenter. I det midterste laget kan det vĉre aktuelt ċ bruke en java-servlet.
I denne lille introduksjonen er det bruk av JDBC vi skal fokusere pċ. For enkelhets skyld skal vi derfor bare ta for oss et tradisjonelt tolags-program der en applikasjon kommuniserer direkte med en database via JDBC.
Grunnstrukturen til et JDBC-program bestċr av fĝlgende skritt:
Statement-objekt som kan sende SQL-setninger til
databasen.ResultSet-objekt som ble returnert fra
databasen.Disse skrittene, unntatt lukking av databaseforbindelsen, er skissert i den lille kodeskissen nedenfor.
public void opprettForbindelseOgSpĝrDatabase(String brukernavn, String passord) throws SQLException { Connection con = DriverManager.getConnection("jdbc:minDriver:minDatabase", brukernavn, passord) try (Statement stmt = con.createStatement()) { ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM Tabell1"); while (rs.next()) { int x = rs.getInt("a"); String s = rs.getString("b"); float f = rs.getFloat("c"); } } catch (SQLException sqle) { //behandle unntak } }
Vi bruker altsċ klassen
DriverManager
for ċ opprette forbindelse til databasen ved ċ gjĝre kall pċ dens
static-metode getConnection. Den vil automatisk prĝve ċ velge en passende
databasedriver blant dem som er installert pċ maskinen. For at det skal lykkes ċ opprette
forbindelse, er det selvsagt en forutsetning at databaseserveren er i drift.
Forbindelsen er representert av
Connection-objektet
som blir returnert fra metoden.
For ċ utfĝre databasespĝrringer bruker vi et
Statement-objekt.
Det oppretter vi
ved hjelp av Connection-objektet som representerer forbindelsen:
Statement stmt = con.createStatement();
For ċ utfĝre spĝrringen mot databasen, bruker vi Statement-objektet til ċ gjĝre
kall pċ en av dets execute-metoder med ĝnsket SQL-setning som parameter.
Resultatet av spĝrringen fċr vi tilbake i form av et
ResultSet-objekt.
Dette gjennomlĝper vi rad for rad ved hjelp av en
while-lĝkke for ċ hente ut enkeltdata
fra radene.
Ett og samme Statement-objekt kan brukes til ċ utfĝre gjentatte spĝrringer
og kommandoer. Nċr vi er ferdige med ċ bruke et objekt av type ResultSet,
Statement eller Connection, sċ bĝr vi lukke det umiddelbart
for ċ frigjĝre ressurser. I kodeskissen ovenfor er lukking av Statement-objektet
sikret ved at det er brukt kodetypen
'try med ressurer' for ċ opprette det.
Nċr et Statement-objekt blir lukket, sċ vil ogsċ et tilhĝrende
ResultSet-objekt automatisk bli lukket. For ĝvrig sċ har alle de tre nevnte
objekttypene sin close-metode. For ċ sikre at den blir utfĝrt,
nċr vi ikke bruker 'try med ressurer',
kan det vĉre
lurt ċ plassere kallet pċ den i en finally-blokk.
Kall pċ close-metoden til et Connection-objekt vil automatisk
sĝrge for kall pċ tilsvarende metode for alle Statement-objekter som er
knyttet til forbindelsen.
Vi skal etter tur se nĉrmere pċ de enkelte skrittene som er listet opp ovenfor. Framstillingen er dels basert pċ det som er skrevet om dette i The Java Tutorials, dels pċ framstillingen i boka Core Java, Volume II, Eighth Edition, av Cay S. Horstmann og Gary Cornell. De konkrete eksemplene som blir brukt er ogsċ hentet fra disse to kildene, med mindre noe annet er nevnt. De er til en viss grad tilpasset. Vi skal ikke ta for oss detaljer omkring oppbygging av databasene som er nevnt i eksemplene, men begrense oss til nĝdvendig omtale av tabellene som blir brukt i eksemplene for ċ kunne illustrere hvordan JDBC kan brukes til ċ kommunisere og manipulere med databasen.
Det finnes i Javas klassebibliotek fĝlgende to typer klasser som kan brukes til ċ opprette forbindelse:
DriverManager:
Dette er en fullt implementert klasse som nċr den blir brukt, automatisk vil laste inn
eventuelle drivere som den finner pċ installasjonens class path.DataSource:
Klasser som implementerer dette interface
anbefales brukt i profesjonelle sammenhenger. For bruken av det vises det til
beskrivelsen i The Java Tutorials.
Applikasjonsutvikling med denne typen forbindelse er beskrevet i
Tutorial for Java Enterpise Edition.I eksemplene vi skal ta for oss vil det bli brukt typen DriverManager
fordi den er enklest ċ bruke og fordi det i eksemplene ikke er bruk for den
utvidete funksjonaliteten som tilbys av typen DataSource.
DriverManagerMetoden DriverManager.getConnection krever som parameter
en database-URL. Hvordan denne ser ut, avhenger av hvilket databasehċndteringssystem
som blir brukt. Dersom det brukes MySQL, kan den for eksempel se ut slik:
"jdbc:mysql://localhost:3306/",
der localhost
er navnet pċ databaseserveren og 3306 er portnummeret.
Det vanligste er vel imidlertid ċ opprette forbindelse til en navngitt database
som allerede eksisterer. Dersom den heter minsql, sċ mċ dette
tilfĝyes i URL-en, slik at den kan bli seende ut slik:
"jdbc:mysql://localhost:3306/minsql"
Dersom det brukes Javas innebygde databasehċndteringssystem, Java DB, kan
URL-en se ut for eksempel slik:
jdbc:derby:testdb;create=true", der
testdb er navnet pċ databasen som det skal opprettes forbindelse til og
create=true instruerer databasehċndteringssystemet om ċ opprette databasen.
Generelt sċ er en database-URL en streng som JDBC-driveren bruker for ċ opprette forbindelse med databasen. Den kan inneholde informasjon om hvor det skal letes etter databasen, navnet pċ den, og konfigurasjonsegenskaper. Den eksakte syntaksen for database-URL-en vil vĉre spesifisert i dokumentasjonen for vedkommende databasehċndteringssystem.
Syntaksen for database-URL-en for driveren Connector/J for MySQL ser ut som fĝlger:
jdbc:mysql://[host][,failoverhost...]
[:port]/[database]
[?propertyName1][=propertyValue1]
[&propertyName2][=propertyValue2]...
host:port er vertsnavnet og portnummeret for
datamaskinen som databasen ligger pċ.
Dersom de ikke er spesifiserte, sċ er default-verdi for host
lik 127.0.0.1 og for port lik 3306.database er navnet pċ databasen det skal opprettes forbindelse til.
Dersom det ikke er spesifisert, vil det ikke bli opprettet forbindelse til noen
default-database.failover er navnet pċ en standby-database
(MySQL Connector/J har support for failover).propertyName=propertyValue representerer
en frivillig, ampersand-separert liste av egenskaper.
Disse attributtene kan brukes til ċ instruere MySQL Connector/J til ċ utfĝre diverse oppgaver.Se MySQL Reference Manual for mer informasjon.
En metode som oppretter forbindelse med en MySQL-database og returnerer et
Connection-objekt som representerer forbindelsen kan dermed se ut
for eksempel pċ denne mċten:
public Connection getConnection(String userName, String password) throws SQLException { Connection conn = null; Properties connectionProps = new Properties(); connectionProps.setProperty("user", userName); connectionProps.setProperty("password", password); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/minsql", connectionProps); return conn; }
SQLExceptonNċr et javaprogram skal jobbe mot en database, er det selvsagt mange
kilder til at unntakssituasjoner kan oppstċ. Det vil da bli kastet ut
unntaksobjekt av type
SQLException.
I mange tilfeller vil det da vĉre snakk om en hel kjede av unntaksobjekter.
For ċ fċ forstċelse for hvordan dette virker og hvordan vi skal behandle denne
typen unntaksobjekter, mċ vi derfor fĝrst se nĉrmere pċ hvordan unntaksobjekter
kan kjedes sammen. Dette temaet ble ikke behandlet i notatet
Unntakshċndtering (exceptions).
For ċ fange opp unntaksobjekter bruker vi
try-blokker. I noen tilfeller
kan det vĉre aktuelt i en try-blokk
ċ kaste ut et nytt unntaksobjekt av en annen type. Det kan for eksempel vĉre
tilfelle dersom vi programmerer et undersystem til et annet system og feilen skyldes
at noe gikk galt i undersystemet. Det er da fornuftig ċ kunne informere om at
det var i undersystemet feilen oppsto. Men dersom vi bare kaster ut et nytt
unntaksobjekt som i fĝlgende skisse, sċ vil den informasjonen som lċ i det
opprinnelige unntaksobjektet gċ tapt:
try { < gjĝr aksess pċ database > } catch (SQLException e) { throw new AnnenExceptiontype("..."); }
Det er ĝnskelig bċde ċ kunne viderefĝre informasjonen som lċ i det opprinnelige unntaksobjektet og kunne informere om at det var dette som var ċrsaken til at det nye unntaksobjektet ble kastet ut. Det oppnċr vi ved ċ modifisere skissen ovenfor til fĝlgende variant:
try { < gjĝr aksess pċ database > } catch (SQLException e) { Throwable se = new AnnenExceptiontype("..."); se.initCause(e); throw se; }
Nċr det nye unntaksobjektet blir fanget opp, kan vi nċ ogsċ fċ tak i det opprinnelige:
Throwable e = se.getCause();
Istedenfor ċ bruke metoden initCause for ċ angi ċrsak, kan vi
bruke unntaksobjektet som er ċrsak som en konstruktĝrparameter for det nye
unntaksobjektet:
Throwable se = new AnnenExceptiontype("...", e);
SQLExceptionSammenkjeding av unntaksobjekter som er ċrsak til hverandre slik det er beskrevet
ovenfor er mulig ċ gjĝre for alle typer unntaksobjekter. Det er funksjonalitet som
er bygget inn i klassen
Throwable
som alle typer unntaksobjekter arver fra. Unntaksobjektene som kan bli
kastet ut fra JDBC-metoder er altsċ av typen SQLException.
Et slikt objekt er utstyrt med en kjede av andre SQLException-objekter
som vi suksessivt kan fċ tak i ved bruk av objektenes getNextException-metode.
Hvert objekt kan ogsċ ha en "ċrsakskjede" som beskrevet ovenfor. Vi fċr dermed
en dobbelt kjede. Fĝr vi tar for oss kode for ċ gjennomlĝpe dobbeltkjeden, skal
vi se nĉrmere pċ hva slags informasjon et SQLException-objekt inneholder
og som dermed kan vĉre til nytte for ċ avgjĝre hva en unntakssituasjon skyldes.
Et SQLException-objekt inneholder fĝlgende informasjon:
getMessage-metode.DatabaseMetaData.getSQLStateType.
Returverdien fra denne vil vĉre en av
int-konstantene
sqlStateXOpen eller sqlStateSQL.) SQL-statuskoden bestċr
av fem alfanumeriske tegn som vi kan fċ tak i ved ċ gjĝre kall pċ
SQLException-objektets getSQLState-metode.int-verdi
som skal identifisere feilen
som var ċrsak til den SQLException som oppsto. Den er bestemt av
leverandĝren for driveren. Vi kan fċ tak i den ved ċ gjĝre kall pċ
SQLException-objektets metode getErrorCode.SQLException-objekt
vĉre knyttet en ċrsakskjede bestċende av ett eller flere Throwable-objekter
som suksessivt var ċrsak til at SQLException-objektet ble kastet ut. Objektene
i denne kjeden kan vi fċ tak i ved rekursivt ċ gjĝre kall pċ metoden
getCause inntil denne returnerer
null, som altsċ
mċ brukes som test for ċ avgjĝre om rekursjonen skal fortsette.SQLException i kjeden av slike, se ovenfor.
Siden SQLException implementerer
interface Iterable<Throwable>,
kan vi gjennomlĝpe kjeden ved ċ bruke en utvidet
for-lĝkke, som skissert
i eksemplet nedenfor.Her er eksempel pċ en metode som gjennomlĝper og skriver ut
innholdet av et SQLException-objekt og kjeden av
andre slike objekter knyttet til dette, samt ċrsakskjeden for hvert objekt:
public static void printSQLException(SQLException ex) { for (Throwable e : ex) { e.printStackTrace(System.err); System.err.println("SQL-status: " + e.getSQLState()); System.err.println("Feilkode: " + e.getErrorCode()); System.err.println("Melding: " + e.getMessage()); Throwable t = ex.getCause(); while (t != null) { System.out.println("Ċrsak: " + t); t = t.getCause(); } } }
En feil av type SQLException er sċ alvorlig at
det ikke er mulig ċ fortsette med videre kjĝring av programmet.
I tillegg til ċ rapportere om slike feil, sċ kan databasedriveren
rapportere unormale tilstander som ikke er sċ alvorlige
at de hindrer videre kjĝring av programmet, dette i form av advarsler. Slike advarsler er objekter av type
SQLWarning.
Denne klassen er subklasse til SQLException, men typen regnes ikke
til ċ vĉre noen unntakstype. Slike advarsler kan hentes ut av objekter av type
Connection, Statement og ResultSet ved bruk av deres metode
getWarning. I likhet med SQLException-objekter, sċ er
SQLWarning-objekter sammenkjedet. Dersom vi for eksempel har
et Statement-objekt stat, sċ kan vi fċ hentet ut
alle advarsler fra dette ved ċ bruke en slik lĝkke:
SQLWarning w = stat.getWarning(); while (w != null) { < gjĝr et eller annet med w > w = w.nextWarning(); }
Den vanligste typen advarsel skjer nċr det foregċr en trunkering av data,
det vil si at det ikke lykkes ċ overfĝre mellom databasen og klientprogrammet
alle de data som det var hensikten ċ overfĝre i en operasjon mot databasen.
Det blir da gitt en advarsel av typen
DataTruncation,
som er en subklassetype til SQLWarning.
DataTruncation-objekter har SQL-status lik 01004, som
indikerer at det var et problem med enten lesing eller skriving av data.
DataTruncation-klassen har metoder som kan brukes til ċ finne ut
om de data som ble trunkert var en parameterverdi eller en kolonneverdi, og
i hvilken kolonne det eventuelt var. Man kan ogsċ finne ut om trunkeringen
skjedde i en skrive- eller en leseoperasjon, hvor mange byte som skulle vĉrt
overfĝrt og hvor mange byte som virkelig ble overfĝrt.
Vi skal ta for oss en oversikt over de objekter og metoder som kan brukes for ċ fċ utfĝrt SQL-setininger.
For ċ fċ utfĝrt en SQL-setning, oppretter vi fĝrst et
Statement-objekt. Til det bruker vi det Connection-objektet
som representerer forbindelsen med databasen, se
foran:
Statement stat = conn.createStatement();
Dernest skriver vi ĝnsket SQL-setning i form av en streng:
String kommando = "< SQL-setning >";
Nċr vi sċ videre ĝnsker ċ fċ utfĝrt vedkommende SQL-setning pċ databasen, mċ vi skille mellom to hovedgrupper av SQL-setninger:
SELECT-setninger for ċ sĝke i databasen,SELECT-setninger sender vi til databasen ved kall pċ
Statement-objektets metode executeQuery. Alle andre
typer SQL-setninger sender vi til databasen ved kall pċ
Statement-objektets metode executeUpdate.
Det kan vĉre SQL-setninger av type
INSERT, UPDATE og DELETE, samt setninger for ċ definere
tabeller, slik som CREATE TABLE og DROP TABLE.
Det finnes ogsċ en execute-metode som
kan brukes til ċ utfĝre alle typer SQL-setninger, men denne blir som regel bare
brukt for spĝrringer som blir tilfĝrt interaktivt under kjĝring.
Er det executeUpdate som er den relevante metoden,
vil dette bli instruksjonen som skal utfĝres mot databasen:
stat.executeUpdate(kommando);
Returverdien fra executeUpdate er en
int-verdi som enten er det
antall rader som ble endret som fĝlge av SQL-setningen, eller 0 dersom
det var en SQL-setning som ikke returnerer noe, slik som for eksempel
setninger for tabelldefinisjon.
Nċr en spĝrring er utfĝrt, er vi interessert i resultatet. Metoden
executeQuery returnerer et objekt av type
ResultSet
som vi kan fange opp, slik som for eksempel i spĝrringen
ResultSet rs = stat.executeQuery("SELECT * FROM Tabellnavn");
Innholdet i et ResultSet-objekt bestċr som regel av flere
rader fra en tabell.
Objektet inneholder ogsċ det vi kan forestille oss som en
markĝr (cursor). Denne kan vi bruke til ċ bevege oss fra rad til rad. For ċ
flytte markĝren til neste rad bruker vi metoden next. I
utgangspunktet stċr markĝren foran fĝrste rad. Men ogsċ for ċ
komme til fĝrste rad mċ vi gjĝre kall pċ metoden next.
Nċr det ikke er flere rader ċ gjennomlĝpe, vel next-metoden
returnere false.
En standardlĝkke for gjennomlĝping av resultatene fra spĝrringen vil dermed se ut slik:
while (rs.next()) { < se pċ en tabellrad returnert av spĝrringen > }
Merk deg at den iteratoren som gjennomlĝper et ResultSet, slik
den er brukt i lĝkka ovenfor, er litt forskjellig fra den som
brukes for gjennomlĝping av en Collection, se
Iteratorer.
Iteratoren for et ResultSet blir initialisert til en posisjon som er
foran fĝrste raden i settet. Vi mċ derfor gjĝre et kall pċ
next-metoden for ċ bevege iteratoren til fĝrste rad, slik det er
gjort i lĝkka ovenfor. Vi fortsetter med ċ gjĝre kall pċ next-metoden
inntil den returnerer false.
For ResultSet-iteratoren finnes det heller ingen
hasNext-metode.
---
Rekkefĝlgen for radene i et ResultSet er helt vilkċrlig.
Med mindre du har spesifisert rekkefĝlgen ved ċ bruke et ORDER BY-direktiv,
er det ingen grunn til ċ legge noen som helst betydning i den rekkefĝlgen som radene har.
Nċr vi gjennomlĝper de enkelte radene, er vi som regel interessert i ċ hente
ut enkeltverdier fra radene. Til dette bruk finnes det i
ResultSet-klassen et stort antall get-metoder for de
forskjellige datatypene, slik som getString og getDouble.
Hver get-metode finnes dessuten i to former: én som har en
kolonneindeks som parameter, og én som har et kolonnenavn i form av en streng som parameter.
Her er et par kodeeksempler pċ ċ hente ut verdier fra en tabellrad fra
ResultSet-objektet rs:
String isbn = rs.getString(1); //returner verdien i fĝrste kolonne i aktuell rad double pris = rs.getDouble("Pris");
Pass pċ at dersom du bruker kolonneindekser for ċ referere til tabellkolonnene,
sċ starter disse pċ 1, til motsetning fra arrayindekser i Java som starter pċ 0.
Merk deg dessuten at indeksnumrene referer seg til kolonnenumrene i
ResultSet-objektet, ikke til kolonnenumrene i
vedkommende tabell i databasen.
---
Den siste instruksjonen i eksemplet ovenfor henter ut verdien fra kolonnen
med navn Pris i den raden i resultatsettet som behandles for ĝyeblikket.
I strengparametre blir det ikke gjort noe skille mellom bruk av store eller smċ bokstaver.
Nċr det gjelder effektivitet av kode,
sċ er det litt mer effektivt ċ bruke kolonneindekser enn kolonnenavn nċr resultater
skal hentes ut, men bruk av navn gir kode som er mer lesbar og lettere ċ vedlikeholde.
De forskjellige get-metodene utfĝrer automatisk rimelig grad av typekonvertering
dersom returtypen fra metoden ikke passer med datatypen som er i vedkommende tabellkolonne.
For eksempel sċ vil kallet rs.getString("Pris")
konvertere desimaltallsverdien som er i priskolonnen til en streng.
Metoden getString, som primĉrt er anbefalt for ċ hente ut SQL-typene
CHAR og VARCHAR, kan brukes til ċ hente ut alle de
grunnleggende SQL-typene, noe som jo kan vĉre nyttig, men som ogsċ har sine begrensninger.
For dersom den blir brukt til ċ hente ut en numerisk type og denne etterpċ skal brukes
i en numerisk beregning, sċ mċ String-verdien som ble returnert fra
getString fĝrst konverteres tilbake til en numerisk type. Men skal verdien
som hentes ut likevel behandles som en streng, er det ingen ulempe med ċ bruke
getString.
Fĝlgende metode fra The Java Tutorials henter ut og gjennomlĝper et resultatsett fra en tabell i den databasen som der brukes som eksempel. Det blir brukt indekser for ċ referere til kolonnene.
public static void alternateViewTable(Connection con) throws SQLException { Statement stmt = null; String query = "select COF_NAME, SUP_ID, PRICE, SALES, " + "TOTAL from COFFEES"; try { stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(query); while (rs.next()) { String coffeeName = rs.getString(1); int supplierID = rs.getInt(2); float price = rs.getFloat(3); int sales = rs.getInt(4); int total = rs.getInt(5); System.out.println(coffeeName + ", " + supplierID + ", " + price + ", " + sales + ", " + total); } } catch (SQLException e) { JDBCTutorialUtilities.printSQLException(e); //skriver ut feilmelding } finally { if (stmt != null) { stmt.close(); } } }
Som nevnt ovenfor, er det mulig ċ la en bruker skrive
inn SQL-setninger direkte og fċ disse utfĝrt. Siden det for programmereren da
ikke vil vĉre mulig ċ vite om det er riktig ċ bruke executeQuery eller
executeUpdate for ċ fċ utfĝrt den SQL-setningen som blir lest inn,
finnes det en generell metode execute til dette bruk. Den returnerer
en logisk verdi som forteller hva slags spĝrring som ble utfĝrt,
true dersom det var en utvalgsspĝrring,
false dersom
det var en oppdateringsspĝrring. Pċ grunnlag av denne returverdien kan vi
avgjĝre om vi videre skal bruke metoden
getResultSet eller getUpdateCount for vedkommende
Statement-objekt for ċ fċ tak i henholdsvis returnert
ResultSet-objekt eller antall berĝrte rader.
En SQL-setning mċ kompileres av databasesystemet fĝr den kan kjĝres. Databasesystemet setter ogsċ opp en plan slik at et sĝk kan gjĝres pċ en mest mulig effektiv mċte. Dersom den samme setningen blir sendt mange ganger, vil databasesystemet spare tid ved ċ gjĝre disse forberedelsene bare én gang. Parameterverdier kan endres i en setning uten at den behĝver ċ bli kompilert pċ nytt.
Vi kan lage et ferdig kompilert setningsobjekt ved ċ bruke setninger av typen
PreparedStatement.
Objekt av type PreparedStatement
blir, slik som Statement-objekt, opprettet ved hjelp av
Connection-objektet som representerer den ċpne forbindelsen med
databasen. Men et PreparedStatement-objekt blir, i motsetning til
et Statement-objekt, gitt en SQL-setning som
konstruktĝrparameter nċr det blir opprettet. Fordelen med dette er at i de
fleste tilfeller blir da SQL-setningen med det samme sendt til databasen der
den blir kompilert. Kompilert setning blir mottatt i retur og lagret i
PreparedStatement-objektet. Dette betyr at nċr objektet skal
foreta en aksess pċ databasen, kan den ferdigkompilerte SQL-setningen
utfĝres med det samme, det er ikke nĝdvendig ċ kompilere den fĝrst.
PreparedStatement-objekter kan brukes pċ SQL-setninger uten
parametre. Men mest brukt er de for SQL-setninger som tar parametre.
Fordelen med ċ bruke SQL-setninger med parametre er at en kan bruke samme
setningen supplert med forskjellige parameterverdier hver gang den blir
utfĝrt, uten ċ mċtte kompilere setningen pċ nytt hver gang. Hver parameter
i et PreparedStatement blir indikert med et ?-tegn.
Dersom det er flere av dem, mċ vi, nċr vi skal tilordne dem verdi, passe pċ
hvilken posisjon de har i rekkefĝlgen, indikert med tallverdier fra
1 og oppover.
Vi tenker oss at vi har en bokdatabase der det er en tabell
forfattere med kolonnner forfatterID, fornavn og
etternavn. Vi skal foreta gjentatte sĝk i tabellen etter fornavn og
etternavn lik de navn som blir lest inn fra brukeren. Vi kan da bruke fĝlgende
SQL-setning med parametre for fornavn og etternavn:
String sql = "SELECT * FROM forfattere " + "WHERE fornavn LIKE ? AND etternavn LIKE ?";
Vi antar at Connection-objektet forbindelse
representerer en ċpen forbindelse til databasen og oppretter en kompilert
SQL-setning:
PreparedStatement setning = forbindelse.prepareStatement(sql);
Fĝr vi kan fċ utfĝrt et PreparedStatement pċ databasen,
mċ vi tilordne verdi til parametrene ved ċ bruke passende set-metoder
pċ PreparedStatement-objektet. Som det er tilfelle med
get-metoder for et ResultSet-objekt, er det
forskjellige set-metoder for de forskjellige datatypene.
I vċrt tilfelle skal vi tilordne strengverdier til fornavn og etternavn.
Vi tenker oss da at String-variablene fornavn og
etternavn er blitt tilordnet verdi pċ en eller annen mċte.
For ċ overfĝre disse til PreparedStatement-objektet kan
vi da skrive:
setning.setString(1, fornavn); // setter parameterverdi setning.setString(2, etternavn); // setter parameterverdi
En sĝkelĝkke etter forfattere med gitt for- og etternavn kan vi skrive etter fĝlgende mal:
do { String fornavn = < les inn fornavn >; String etternavn = < les inn etternavn >; setning.setString( 1, fornavn ); // setter parameterverdi setning.setString( 2, etternavn ); // setter parameterverdi ResultSet res = setning.executeQuery(); // Obs: ingen parameter! < vis resultat > } while ( < flere sĝk > );
Ovenfor ble setningobjektets metode setString brukt til ċ
gi String-verdi til de to parametrene i SQL-setningen.
PreparedStatement-klassen inneholder tilsvarende
set-metoder for alle standard datatyper i java
(setInt, setDouble etc.). Fĝrste parameter i metodene angir hvilken
SQL-parameter som skal fċ verdi. Andre parameter angir verdien. Denne mċ
selvsagt ha en datatype som er kompatibel med hvilken set-metode
det dreier seg om.
Nċr det er satt en verdi pċ en parameter, vil den beholde denne verdien
inntil den fċr satt en annen verdi eller metoden
clearParameters blir kalt. Dette betyr at du fra spĝrring til spĝrring
bare trenger ċ gjĝre kall pċ set-metode for de parametrene som trenger
oppdatering. Kall pċ clearParameters kan det vĉre aktuelt ċ gjĝre
dersom en for eksempel ĝnsker ċ frigjĝre ressurser som er bundet opp av
parameterverdiene.
Det blir anbefalt ċ bruke PreparedStatement alltid nċr en har
en SQL-setning som inneholder én eller flere variable.
Et PreparedStatement-objekt blir ugyldig etter at det tilhĝrende
Connection-objektet er lukket. Men det er imidlertid slik at mange
databasedrivere automatisk vil "cache" PreparedStatement-objekter.
Dersom samme spĝrring blir forberedt om igjen, vil databasen kort og godt bruke
om igjen samme spĝrrestrategi. En trenger derfor ikke ċ bekymre seg om den ekstra
"overhead" som bruk av prepareStatement medfĝrer.
I tillegg til ċ kunne lagre tall, tekst og datoer, er det mange databaser
som kan lagre det som kalles store objekter, pċ engelsk forkortet
til LOBs (large objects), slik som bilder eller andre data. I SQL
blir binĉre, store objekter kalt BLOB'er, og store tegnobjekter kalt
CLOB'er.
For ċ hċndtere slike store objekter i JDBC, utfĝrer vi fĝrst passende
SELECT-setning og gjĝr sċ kall pċ getBlob- eller
getClob-metoden for det ResultSet-objektet vi fċr
i retur. Da vil vi fċ returnert et objekt av type
Blob
eller
Clob.
For ċ fċ hentet ut de binĉre data fra en Blob, kan vi gjĝre kall pċ
objektets getBytes- eller getInputStream-metode.
Vi tenker oss at vi har en tabell bokforsider som inneholder
bilder av bĝkers forsider i en kolonne forside, samt en kolonne for
ISBN-numre for identifikasjon av bĝkene.
For ċ fċ tak i et slikt bilde, kan vi da skrive
kode etter dette mĝnster, der forbindelse representerer forbindelsen
og isbn er blitt tilordnet et ISBN-nummer:
PreparedStatement stat = forbindelse.prepareStatement(
"SELECT forside FROM bokforsider WHERE ISBN=?");
stat.set(1, isbn);
ResultSet resultat = stat.executeQuery();
if (resultat.next())
{
Blob forsideblob = resultat.getBlob(1);
Image forsidebilde = ImageIO.read(forsideblob.getInputStream());
}
Pċ tilsvarende mċte kan vi, dersom vi henter ut et Clob-objekt,
fċ tak i tegndata ved ċ gjĝre kall pċ
getSubString- eller
getCharacterStream-metoden.
For ċ plassere et LOB i en database, bruker vi fĝrst
Connection-objektet for ċ gjĝre kall pċ dets
createBlob- eller createClob-metode. Fċr sċ tak i en
OutputStream eller en Writer pċ det objektet som er opprettet,
skriver dataene, og lagrer til slutt objektet i databasen.
Vi tenker oss at vi har den samme tabellen med bokforsider som er omtalt
ovenfor. Vi skal lagre Image-objektet
forsidebilde som en ny forside i denne tabellen:
Blob forsideblob = forbindelse.createBlob(); int startpos = 1; OutputStream ut = forsideblob.setBinaryStream(startpos); ImageIO.write(forsidebilde, "PNG", ut); PreparedStatement stat = forbindelse.prepareStatement("INSERT INTO bokforsider VALUES (?, ?)"); stat.set(1, isbn); stat.set(2, forsideblob); stat.executeUpdate();
ResultSetEt ResultSet bestċr vanligvis av flere rader med tabelldata.
Ovenfor er det beskrevet hvordan
next-metoden kan brukes til ċ gjennomlĝpe radene.
Denne funksjonaliteten er tilstrekkelig dersom vi bare har behov for
ċ gċ gjennom radene for ċ analysere data. Men i mange sammenhenger
er det aktuelt ċ vise resultatene av en spĝrring mot databasen pċ skjermen i form av en tabell, og da
ĝnsker vi vanligvis at brukeren skal kunne bevege seg forover og bakover
i tabellen, om nĝdvendig ogsċ ved ċ bruke skrolling. Denne funksjonaliteten
kan vi fċ til ved ċ opprette et ResultSet som er skrollbart.
I et slikt er det mulig ċ fċ posisjonsmarkĝren til ċ bevege seg bċde forover
og bakover, og dessuten til ċ hoppe til en hvilken som helst posisjon.
I en tabellvisning av sĝkeresultater pċ skjermen kan det ogsċ tenkes at
vi ĝnsker at brukeren skal ha adgang til ċ redigere og oppdatere de dataene
som vises, slik at det pċ grunnlag av dette ogsċ foretas en oppdatering av
databasen. Det kan vi fċ til ved ċ opprette et ResultSet som er
oppdaterbart.
Default-funksjonaliteten er at et ResultSet verken er
skrollbart eller oppdaterbart. For ċ fċ det, mċ vi bruke to ekstra parametre
nċr vi oppretter Statement-objektet, som i fĝlgende eksempel:
Statement stat;
stat = forbindelse.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY);
Begge parametrene til createStatement-metoden er navngitte
int-konstanter.
Det er derfor viktig ċ fċ dem i riktig rekkefĝlge! Den fĝrste parameteren
kan ha en av disse verdiene:
ResultSet.TYPE_FORWARD_ONLY ResultSet.TYPE_SCROLL_INSENSITIVE ResultSet.TYPE_SCROLL_SENSITIVE
Et skrollbart ResultSet-objekt fċr vi bare dersom
fĝrste parameter har en av de to verdiene
ResultSet.TYPE_SCROLL_INSENSITIVE eller
ResultSet.TYPE_SCROLL_SENSITIVE. Forskjellen mellom de to har ċ
gjĝre med om eventuelle endringer som gjĝres i
ResultSet-objektet mens det er ċpent skal reflektere seg
umiddelbart pċ skjermen i form av oppdaterte verdier eller ikke. For alle
de tre mulige verdiene av den fĝrste parameteren vil det vĉre slik at dersom
ResultSet-objektet lukkes, og sċ ċpnes igjen, sċ vil endringene
vĉre synlige.
Den andre parameteren kan
alternativt ha verdien ResultSet.CONCUR_UPDATABLE. Parameteren
spesifiserer om ResultSet-objektet bare skal vĉre lesbart eller
om det skal kunne brukes til ċ oppdatere databasen. Det en mċ huske pċ, er at
dersom en spesifiserer skrollbarhet (med den fĝrste parameteren), sċ mċ en ogsċ
spesifisere om det skal vĉre bare lesbart eller oppdaterbart. Og siden
begge parametrene er av type int,
vil kompilatoren ikke protestere dersom en bytter om rekkefĝlgen!
Dersom en som fĝrste parameter bruker
ResultSet.TYPE_FORWARD_ONLY, vil ResultSet-objektet
ikke vĉre skrollbart, det vil si at markĝren bare kan flytte seg forover.
Dersom vi ikke bruker parametre i det hele tatt, slik vi har gjort tidligere, vil vi automatisk
fċ et ResultSet-objekt som er
ResultSet.TYPE_FORWARD_ONLY og
ResultSet.CONCUR_READ_ONLY. For ĝvrig mċ en vĉre klar over at
databasesystemet og driveren for dette kan sette begrensninger pċ hva som
er mulig ċ gjĝre.
ResultSetFor ċ kunne flytte markĝren pċ annen mċte enn bare forover, ved hjelp
av next-metoden, mċ vi altsċ ha et skrollbart ResultSet,
se ovenfor.
For ċ flytte markĝren én rad bakover i det skrollbare ResultSet-objektet
rs, bruker vi koden
if (rs.previous())
...
Metoden previous returnerer true
dersom markĝren nċ er plassert pċ en rad, false
dersom den nċ er plassert foran fĝrste rad.
Det er ogsċ mulig ċ flytte markĝren bakover eller forover et ĝnsket antall rader med metodekallet
rs.relative(n);
Dersom n er positiv, vil markĝren bli flyttet forover. Er n
negativ, blir markĝren flyttet bakover, og er n lik 0, har
instruksjonen ingen effekt. Dersom vi prĝver ċ flytte markĝren utenfor det aktuelle
settet med rader, blir den satt til ċ peke enten til etter den siste raden, eller
foran den fĝrste, avhengig av fortegnet til n. Metoden returnerer dessuten
false. Metoden returnerer
true dersom markĝren er blitt plassert
pċ en eksisterende rad.
Vi har ogsċ muligheten til ċ plassere markĝren pċ et ĝnsket radnummer ved ċ bruke instruksjonen
rs.absolute(n);
Aktuelt radnummer fċr vi ved hjelp av metodekallet
int aktuellRad = rs.getRow();
Fĝrste rad i et ResultSet har radnummer 1. Dersom returverdien fra
metoden er 0, er ikke markĝren pċ en eksisterende rad, men enten foran den
fĝrste eller etter den siste raden.
Vi kan for ĝvrig plassere markĝren ved bruk av metodene first, last, beforeFirst og
afterLast. Navnene pċ metodene indikerer hvor markĝren da blir plassert.
For ċ teste om markĝren er i noen av disse spesielle posisjonene, har vi dessuten
metodene isFirst, isLast, isBeforeFirst og isAfterLast.
ResultSetDersom vi ĝnsker ċ redigere dataene i et ResultSet slik at
databasen samtidig blir oppdatert med endringene som foretas, sċ mċ vi altsċ
bruke et ResultSet av den typen som er oppdaterbart. Det trenger
ikke samtidig ċ vĉre skrollbart, men dersom dataene samtidig blir presentert
for en bruker for editering, ĝnsker vi vanligvis det.
For ċ fċ et oppdaterbart ResultSet som samtidig er skrollbart, kan
vi opprette Statement-objektet pċ fĝlgende mċte:
Statement stat = forbindelse.createStatement(
ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
Det ResultSet vi nċ fċr returnert ved kall pċ
executeQuery vil vĉre oppdaterbart, og skrollbart.
Vi tenker oss at vi har en database for bĝker med en Boktabell og
en kolonne Pris i denne. Vi ĝnsker ċ oppdatere prisen pċ noen av
bĝkene, men har ikke noe enkelt kriterium ċ bruke i en UPDATE-setning
for ċ fċ oppdatert akkurat de bĝker vi ĝnsker og med de prisene vi ĝnsker.
En lĝsning kan da vĉre ċ gjennomlĝpe alle bĝkene for oppdatering av priser
ved at en operatĝr oppdaterer de prisene som skal oppdateres etter hvert som
boktabellen blir vist pċ skjermen. En skisse for dette kan se ut som fĝlger:
Statement stat = forbindelse.createStatement(
ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
String spĝrring = "SELECT * FROM Boktabell";
ResultSet rs = stat.executeQuery(spĝrring);
while (rs.next())
{
if (...)
{
double ĝkning = ...;
double pris = rs.getDouble("Pris");
rs.updateDouble("Pris", pris + ĝkning);
rs.updateRow(); //pass pċ ċ oppdatere rad etter oppdatering av kolonner!
}
}
Det finnes updateXxx-metoder for alle datatyper som svarer til
SQL-typer, slik som updateDouble, updateString, etc. Tilsvarende
som for getXxx-metoder, mċ vi spesifisere enten kolonnenavn
eller kolonnenummer, og i tillegg spesifisere den nye verdien som skal inn. Men
pass pċ at dersom du bruker kolonnenummer, sċ vil det vĉre kolonnenummer i
ResultSet-objektet, og dette kan godt vĉre forskjellig fra kolonnenummeret
i databasen.
Vĉr oppmerksom pċ at update-metodene for kolonneverdier bare
endrer kolonneverdier i ResultSet-objektet, de endrer ikke databasen! Nċr du er
ferdig med ċ oppdatere kolonneverdiene i en rad, mċ du gjĝre kall pċ
updateRow-metoden. Den sender alle oppdateringene i aktuell rad
til databasen. Dersom du flytter markĝren til en annen rad uten ċ ha kalt
updateRow, vil alle endringene bli kansellert og aldri bli
kommunisert til databasen. Det finnes for ĝvrig ogsċ en
cancelRowUpdates-metode som kan brukes til ċ kansellere de
oppdateringene som er foretatt av kolonneverdier i en rad, men denne mċ vi
i sċ fall gjĝre kall pċ fĝr vi har gjort kall pċ updateRow.
Eksemplet ovenfor skisserer hvordan du kan modifisere en eksisterende rad.
Dersom du ĝnsker ċ tilfĝye en ny rad til databasen, er det nĝdvendig ċ gċ fram pċ en litt
annen mċte. For ResultSet-objektet mċ du da fĝrst bruke metoden
moveToInsertRow for ċ flytte markĝren til en spesiell posisjon
kalt innsettingsraden. I denne posisjonen kan du bygge opp den nye
raden ved ċ bruke passende update-metoder for kolonneverdiene,
slik det er forklart ovenfor.
Til slutt, nċr alle ĝnskede verdier er satt inn i den nye raden, gjĝr du kall
pċ insertRow-metoden for ċ fċ lagt den nye raden inn i databasen.
Nċr dette er gjort, gjĝr du kall pċ metoden moveToCurrentRow for
ċ fċ flyttet markĝren tilbake til den posisjonen den hadde fĝr kallet pċ
moveToInsertRow ble foretatt.
Vi tenker oss at vi har en Boktabell med kolonner for
Tittel, ISBN, ForlagsId og Pris. Fra denne
tabellen har vi hentet ut et ResultSet-objekt rs
og ĝnsker ċ sette inn en ny rad i tabellen. Vi tenker oss at variablene
tittel, isbn, forlag og pris skal brukes til ċ
tilfĝre data til de kolonnene som navnene deres indikerer, og at variablene
er blitt tilordnet verdier pċ en eller annen mċte. Instruksjonene som behĝves
for selve innsettingen kan da bli noe slikt som dette:
rs.moveToInsertRow(); rs.updateString("Tittel", tittel); rs.updateString("ISBN", isbn); rs.updateString("ForlagsId", forlag); rs.updateDouble("Pris", pris); rs.insertRow(); rs.moveToCurrentRow();
Merk deg at du har ikke noen mulighet til ċ bestemme hvor den nye raden
blir satt inn i ResultSet-objektet eller i databasen.
Dersom det ikke blir spesifisert noen kolonneverdi i en rad som skal settes inn,
sċ vil denne kolonnen fċ SQL-verdi NULL. Men dersom kolonnen har et
NOT NULL-krav, sċ vil det isteden bli kastet ut et unntaksobjekt og raden
blir ikke satt inn.
Vi har mulighet til ċ fjerne den raden som markĝren stċr pċ for ĝyeblikket ved ċ bruke instruksjonen
rs.deleteRow();
der rs er ResultSet-objektet. Instruksjonen har som
virkning at vedkommende rad ĝyeblikkelig blir fjernet fra bċde
ResultSet-objektet og fra databasen.
Vi ser at ResultSet-klassens metoder updateRow, insertRow
og deleteRow gir samme muligheter som SQL-instruksjonene
UPDATE, INSERT og DELETE. Vi kan derfor velge hva
vi vil bruke. Java-programmerere vil kanskje finne det mer naturlig ċ manipulere
databaseinnhold ved ċ gċ veien om ResultSet-objekter enn ċ
konstruere SQL-setninger. Men samtidig bĝr en vĉre klar over at effektiviteten
av koden kan vĉre ganske forskjellig. Det er mye mer effektivt ċ utfĝre
en UPDATE-setning enn det er ċ utfĝre enn spĝrring, for sċ ċ
iterere gjennom resultatene og oppdatere data underveis. Oppdatering via
ResultSet er det fornuftig ċ bruke i interaktive programmer der
brukeren skal kunne gjĝre tilfeldige dataendringer, mens det for de fleste
programmatiske endringer vil vĉre best ċ bruke en SQL-setning av type
UPDATE.
RowSet-objekter: typer og egenskaperForan har vi sett at skrollbare ResultSet-objekter gir store
muligheter for ċ manipulere med databasen. Men de har den ulempen at databaseforbindelsen
mċ holdes kontinuerlig ċpen mens vi bruker dem. Siden databaseforbindelser er
knapphetsressurser, er dette uheldig for brukere som skal jobbe interaktivt
mot en database dagen lang. Men heldigvis finnes det for slike situasjoner
en spesialtype resultatsett definert av
interface RowSet,
som er subinterface til ResultSet. Et RowSet
kan vĉre knyttet med en ċpen forbindelse til en database mens det
eksisterer og kalles da et tilknyttet RowSet, men det
trenger ikke ċ ha en slik ċpen forbindelse, og kalles da et
fraknyttet RowSet.
RowSet-objekter passer det ogsċ ċ bruke i tilfeller der vi
trenger ċ flytte et spĝrreresultat til et annet lag i en kompleks applikasjon
bestċende av flere lag, eller ċ flytte det til en annen komponent, slik som for eksempel en
mobiltelefon. Det er aldri aktuelt ċ flytte et ResultSet-objekt,
det kan inneholde en stor datastruktur, og det er fastbundet til en
databaseforbindelse.
I pakken
javax.sql.rowset
finnes det fĝlgende subinterface til RowSet for spesialiserte oppgaver:
CachedRowSet:
Dette er et fraknyttet RowSet, der operasjoner kan utfĝres
uten at det er en ċpen tilknytning til databasen. Bruken av det blir
nĉrmere omtalt i det fĝlgende.WebRowSet:
Et CachedRowSet som kan lagres som en XML-fil. Fila kan flyttes til
et annet lag i applikasjonen der den kan ċpnes med et annet
WebRowSet-objekt.FilteredRowSet og
JoinRowSet:
Disse typene stĝtter operasjoner pċ RowSet-objekter som svarer til
SQL-operasjonene SELECT og JOIN, uten at det er nĝdvendig ċ
ha en databaseforbindelse.JdbcRowSet:
Et tilknyttet RowSet-objekt. Kan oppfattes som en innpakning rundt et
ResultSet-objekt som gjĝr det skrollbart og oppdaterbart, og
utstyrer det med get- og set-metoder slik at det kan brukes som en
JavaBeans-komponent.Oracle har utviklet referanseimplementasjoner av de
interface
som er listet opp ovenfor. De er inneholdt i pakken
com.sun.rowset.
Men det er fritt fram for programmerere til ċ lage
sine egne implementasjoner.
CachedRowSetEt CachedRowSet inneholder rader av data fra en datakilde og
lagrer disse i maskinens memory, slik at man kan operere pċ dataene uten
kontinuerlig forbindelse med datakilden.
Objektet er dessuten skrollbart, oppdaterbart
og serialiserbart, og det kan brukes som en JavaBeans-komponent.
Det typiske er at et CachedRowSet inneholder rader fra et
ResultSet fra en databasespĝrring, men det kan ogsċ
inneholde rader fra en hvilken som
helst fil med et tabellformat, slik som for eksempel et regneark.
Siden CachedRowSet er subinterface til ResultSet,
kan du bruke det pċ akkurat samme mċte som du bruker et ResultSet.
I tillegg har det den fordelen at du kan lukke forbindelsen med databasen og
likevel fortsette ċ bruke CachedRowSet-objektet. Dette gjĝr det
mulig ċ implementere interaktive applikasjoner pċ en mye enklere mċte ved at
man for hver brukerkommando kort og godt kan ċpne databaseforbindelsen, foreta
en spĝrring, putte spĝrreresultatet i et CachedRowSet, og sċ
lukke forbindelsen med databasen.
Det er altsċ ogsċ tillatt ċ foreta endringer i de dataene som et
CachedRowSet inneholder. Det gjĝr vi pċ samme mċte som for
et ResultSet, ved kall pċ metoden updateRow,
deleteRow eller
insertRow. Men siden et CachedRowSet ikke er knyttet
til sin datakilde mens det blir oppdatert, er det nĝdvendig ċ utfĝre en
tilleggsoperasjon. Det er kall pċ en av variantene av dets metode
acceptChanges. CachedRowSet-objektet vil da igjen bli satt i
forbindelse med databasen og utfĝre nĝdvendige SQL-setninger for ċ fċ skrevet
endringene til databasen.
Et CachedRowSet er altsċ bare kortvarig knyttet med en forbindelse til datakilden,
nċr det leser inn data i forbindelse med at det blir opprettet, og til slutt nċr
det skal oppdatere datakilden med de endringene som er blitt foretatt underveis.
Resten av tida er det fraknyttet datakilden, ogsċ mens endringer av data blir foretatt.
Siden objektet dessuten er "slankt" og serialiserbart, kan det lett sendes til
andre, tynne komponenter som for eksempel mobiltelefoner.
CachedRowSet-objektDet finnes flere muligheter for ċ opprette et CachedRowSet-objekt
og fylle det med data. For ċ opprette objektet, kan vi bruke default-konstruktĝren
til Oracle's referanseimplementasjon CachedRowSetImpl:
import com.sun.rowset.CachedRowSetImpl; ... CachedRowSet crs = new CachedRowSetImpl();
Videre er det flere muligheter for ċ fylle objektet med ĝnskede data.
Én mulighet er ċ fylle det med data fra et eksisterende
ResultSet:
ResultSet resultat = ...;
crs.populate(resultat);
forbindelse.close(); //kan nċ lukke forbindelsen til databasen
En annen mulighet er ċ la CachedRowSet-objektet knytte seg
til databasen automatisk. Men det forutsetter at vi pċ forhċnd har satt opp
nĝdvendige databaseparametre for objektet:
crs.setURL(<database-URL>);
crs.setUsername(brukernavn);
crs.setPassword(passord);
Videre mċ vi ha satt ĝnsket SQL-setning for spĝrringen og
eventuelle parametre. Dersom vi for eksempel ĝnsker ċ hente ut bĝker
utgitt pċ et bestemt forlag fra en boktabell, og vi har lagt inn vedkommende
forlagsnavn i String-variabelen forlagsnavn,
kan det vĉre noe slikt som
crs.setCommand("SELECT * FROM Boktabell WHERE Forlag=?");
crs.setString(1, forlagsnavn);
Nċ kan vi fylle CachedRowSet-objektet med data ved ċ skrive
crs.execute();
Dette metodekallet vil opprette databaseforbindelse, foreta spĝrringen
mot databasen, fylle CachedRowSet-objektet med data, og sċ
lukke forbindelsen. Vi trenger altsċ ikke egne instruksjoner verken for ċ ċpne
eller lukke forbindelsen med databasen.
Siden et CachedRowSet-objekt lagrer sine data i maskinens
memory, vil det vĉre stĝrrelsen pċ tilgjengelig lagerplass som til enhver tid
vil avgjĝre hvor mye data det kan inneholde. For at dette ikke skal bli noe
problem i tilfeller der vi vet at et resultatsett kan bli ganske stort, har vi
mulighet for ċ splitte opp resultatsettet i passe store enheter kalt sider.
For uansett sċ vet vi at en interaktiv bruker sannsynligvis bare vil ċ se pċ et
begrenset antall rader om gangen. Vi kan da spesifisere en sidestĝrrelse pċ denne mċten:
CachedRowSet crs = ...; crs.setCommand(kommando); crs.setPageSize(20); ... crs.execute();
I dette tilfelle vil bare 20 rader om gangen vĉre tilgjengelige for inspeksjon
og eventuelle endringer. For ċ fċ hvert knippe med rader, gjĝr vi kall pċ
metoden nextPage. Den vil opprette et nytt CachedRowSet-objekt
og fylle det med neste side med data. Dersom for eksempel resultatsettet fra
execute-kallet ovenfor inneholdt 100 rader med data og sidestĝrrelsen er satt
til 20, sċ vil fĝrste kallet pċ nextPage opprette et CachedRowSet
som inneholder de fĝrste 20 radene. Etter at vi har gjort det vi ĝnsker med disse,
gjĝr vi et nytt kall pċ nextPage for ċ fċ et nytt
CachedRowSet-objekt som inneholder de neste 20 radene. Dataene fra det
fĝrste CachedRowSet-objektet vil da ikke lenger befinne seg i memory,
siden de er blitt erstattet av dataene fra det andre objektet, og slik fortsetter det.
Metoden nextPage returnerer true
sċ lenge som det er mer data ċ hente. En lĝkke for gjennomlĝping av alle data kan derfor
lages etter dette mĝnster:
while (crs.nextPage()) { while (crs.next()) { <behandler rad pċ denne side> } ... //eventuelt kall pċ crs.acceptChanges(forbindelse) eller //crs.acceptChanges() for oppdatering av database }
Kallet crs.acceptChanges() uten parameter kan vi bare
utfĝre dersom CachedRowSet-objektet er tilfĝrt informasjon om
database-URL, brukernavn og passord som behĝves for tilknytning til databasen,
slik det ble skissert ovenfor.
Vĉr dessuten oppmerksom pċ at dersom CachedRowSet-objektet ble
fylt med data fra et ResultSet ved hjelp av populate-metoden,
sċ vil det ikke ha kjennskap til navnet pċ den tabellen det skal oppdatere.
I sċ fall mċ vi gjĝre kall pċ dets setTable-metode for ċ fċ satt
tabellnavn.
Det er klart at dersom innholdet i databasen har endret seg etter at vi
hentet inn data til vċrt resultatsett, og vi ĝnsker ċ oppdatere databasen
med de endringene vi har foretatt i resultatsettet, sċ kan det bli trĝbbel
ved at dataene i databasen ikke lenger vil bli konsistente. Dette mċ derfor
hindres. I den referanseimplementasjonen som er nevnt ovenfor
blir dette taklet ved at det blir sjekket om de opprinnelige radverdiene i
resultatsettet, det vil si verdiene fĝr eventuell redigering, er
identiske med de nċvĉrende verdiene i databasen. Dersom dette er tilfelle, sċ
vil databasen bli oppdatert med de redigerte dataene. I motsatt fall vil det bli kastet ut
en SyncProviderException og ingen endringer blir foretatt.
Nċr det gjelder bruk av WebRowSet, FilteredRowSet,
JoinRowSet og JdbcRowSet henvises det til
The Java Tutorials.
JDBC kan brukes til ċ hente opplysninger om strukturen til en database og dens tabeller. Slik informasjon er av stor nytte nċr man skal programmere verktĝy som skal jobbe mot en database.
Data som beskriver en database eller en av dens deler blir
i SQL kalt meta-data, for ċ skille dem fra data som lagres i databasen.
Vi kan hente ut tre typer av meta-data: om en database, om et
ResultSet-objekt, og om parametrene til en kompilert SQL-setning
(et PreparedStatement).
Til bruk for uthenting av meta-data har JDBC definert
interface
DatabaseMetaData.
Dette mċ utviklere av databasedrivere implementere slik at dets metoder returnerer
informasjon om driveren og databasehċndteringssystemet som den er driver for.
Det finnes for eksempel et stort antall metoder som forteller om driveren gir stĝtte
for en bestemt funksjonalitet.
For ċ kunne fċ tak i meta-data, mċ vi fĝrst bruke databaseforbindelsen
til ċ fċ tak i et objekt av type DatabaseMetaData, slik at
vi kan bruke det til ċ gjĝre kall pċ dets metoder:
DatabaseMetaData meta = forbindelse.getMetaData();
Vi ĝnsker opplysninger om alle tabellene i databasen. Da kan vi bruke fĝlgende metodekall:
String[] typer = {"TABLE"};
ResultSet mrs = meta.getTables(null, null, null, typer);
Hver rad i resultatsettet som blir returnert vil inneholde informasjon om en tabell i databasen. Tredje kolonne i raden inneholder tabellens navn. En lĝkke som henter ut alle tabellnavnene kan vi derfor skrive slik:
while (mrs.next())
{
String tabellnavn = mrs.getString(3);
...
}
ResultSetEt objekt av type DatabaseMetaData som ble brukt i eksemplet ovenfor
gir opplysninger om selve databasen. Dersom vi ĝnsker opplysninger om et
ResultSet, mċ vi isteden bruke et objekt av type
ResultSetMetaData.
Nċr vi har et ResultSet fra en spĝrring mot databasen, kan vi
for eksempel fċ tak i opplysninger om antall kolonner i det og hver kolonnes navn,
type og feltbredde. Som eksempel skal vi gjĝre bruk av meta-data for ċ
lage en label for hvert kolonnenavn
og et tekstfelt av passe bredde for hver verdi. Vi gjĝr bruk av
Statement-objektet setning som er opprettet pċ
forhċnd.
ResultSet res = setning.executeQuery("SELECT * FROM " + tabellnavn ); ResultSetMetaData meta = res.getMetaData(); for (int i = 1; i <= meta.getColumnCount(); i++) { String kolonnenavn = meta.getColumnLabel(i); int kolonnebredde = meta.getColumnDisplaySize(i); JLabel label = new JLabel(kolonnenavn); JTextField tf = new JTextField(kolonnebredde); ... }
For indekseringen i for-lĝkka ovenfor
mċ du passe pċ at kolonneindeksene i et ResultSetMetaData gċr fra 1 og
oppover til og med antall kolonner, til forskjell fra en array i java,
der de gċr fra 0 og oppover til, men ikke til og med antall plasser
i arrayen.
En transaksjon er en samling av en eller flere setninger som skal utfĝres som en enhet, slik at enten blir alle setningene utfĝrt, eller ingen av dem blir utfĝrt.
Dersom penger skal overfĝres fra én konto til en annen, er det viktig at begge kontoene endrer saldo. Dersom feil inntreffer under utfĝrelsen, kan vi ikke risikere at bare én av kontoene har endret saldo.
***
Nċr en forbindelse til en database blir opprettet, er den i
auto-commit-modus. Det betyr at hver enkelt SQL-setning blir behandlet som
en transaksjon og vil bli automatisk stadfestet (committed) rett etter at
den er blitt utfĝrt. For ċ kunne gruppere to eller flere SQL-setninger sammen
til en transaksjon, mċ vi gċ ut av auto-commit-modus. Dersom
Connection-objektet forbindelse representerer en
ċpen forbindelse med databasen, gjĝr vi det slik:
forbindelse.setAutoCommit(false);
Nċr vi er ute av auto-commit-modus, vil ikke noen SQL-setninger bli
stadfestet fĝr vi eksplisitt gjĝr kall pċ commit-metoden:
forbindelse.commit();
Alle setninger som er utfĝrt siden forrige kall pċ commit
vil bli inkludert i innevĉrende transaksjon og vil bli stadfestet sammen som
en enhet.
rollbackMetoden rollback (i klasse Connection) har som
virkning at en transaksjon blir abortert og eventuelle verdier som er blitt
endret i lĝpet av transaksjonen blir tilbakefĝrt til sine tidligere
verdier. Dersom en prĝver ċ utfĝre én eller flere setninger i en transaksjon
og fċr en SQLException, sċ bĝr en gjĝre kall pċ rollback
for ċ abortere transaksjonen og starte transaksjonen pċ nytt. Det er eneste
mċten ċ vĉre sikker pċ hva som er stadfestet (committed) og hva som ikke er det.
Oppfanging av en SQLException forteller oss at noe er galt, men
det forteller ikke hva som er stadfestet og hva som ikke er det. Siden vi ikke
kan stole pċ at ikke noe er blitt stadfestet, er et kall pċ
rollback eneste mċten ċ sikre seg pċ.
***
Gangen i ċ fċ utfĝrt en transaksjon blir dermed som fĝlger, etter at vi har gċtt ut av auto-commit-modus som forklart ovenfor:
Opprett et Statement-objekt pċ vanlig mċte:
Statement stat = forbindelse.createStatement();
Gjĝr kall pċ executeUpdate sċ mange ganger som behĝves
for ċ fċ utfĝrt de SQL-setningene som skal tilhĝre transaksjonen:
stat.executeUpdate(kommando1); stat.executeUpdate(kommando2); stat.executeUpdate(kommando3); ...
Dersom alle setningene er blitt utfĝrt uten at det har oppstċtt noe feil,
det vil si uten at det er kastet ut noen SQLException,
sċ gjĝr du kall pċ commit-metoden:
forbindelse.commit();
Dersom det i motsatt tilfelle oppsto en feil under utfĝrelsen av
SQL-setningene (kalt kommandoer ovenfor) ved at det er kastet ut en
SQLException, sċ gjĝr du isteden kall pċ
rollback:
forbindelse.rollback();
Da vil alle kommandoene som er blitt utfĝrt siden forrige commit
bli reversert, det vil skje bċde for setninger som er utfĝrt
automatisk og for setninger som er utfĝrt ved kall.
Instruksjonen
forbindelse.setAutoCommit(true);
setter databaseforbindelsen tilbake til auto-commit-modus, slik at hver
kommando igjen blir automatisk stadfestet (commited) nċr den er blitt fullfĝrt,
slik at vi ikke trenger ċ gjĝre egne kall pċ commit-metoden.
Du bĝr bare gċ ut av auto-commit-modus nċr transaksjoner skal utfĝres.
Dermed unngċr du ċ sette lċs pċ databasen for utfĝrelse av multiple
SQL-setninger, noe som minsker risikoen for at du kommer i konflikt med
andre brukere av den samme databasen.
Det er vanskelig ċ lage et fornuftig eksempel ut fra en database
som lagrer bare statiske opplysninger, slik som bokdatabasen
som vi har referert til i eksemplene hittil. Vi tenker oss derfor isteden at vi har en database
kaffesalg som skal brukes til ċ registrere salg av forskjellige
kaffemerker. En av tabellene i denne databasen heter salg og har
fĝlgende kolonner:
| kaffenavn | levId | pris | ukesalg | totalsalg |
|---|---|---|---|---|
| (tekst, nĝkkel) | (heltall, leverandĝr) | (desimaltall) | (heltall, ant kg) | (heltall, ant kg) |
Denne skal oppdateres for ukesalg og totalsalg i slutten av hver uke. Det er da viktig at disse to blir oppdatert samlet, ellers vil ikke databasen inneholde konsistente data. En transaksjon for dette, tilpasset fra The Java Tutorials, kan se ut slik:
Connection forbindelse = < oppretter ċpen forbindelse til databasen >; PreparedStatement oppdaterSalg = null; PreparedStatement oppdaterTotal = null; String kommando1 = "UPDATE salg SET ukesalg = ? WHERE kaffenavn LIKE ?"; String kommando2 = "UPDATE salg SET totalsalg = totalsalg + ? " + "WHERE kaffenavn LIKE ?"; try { forbindelse.setAutoCommit(false); oppdaterSalg = forbindelse.prepareStatement(kommando1); oppdaterTotal = forbindelse.prepareStatement(kommando2); for (<alle kaffemerker>) { int ukesalg = ...; oppdaterSalg.setInt(1, ukesalg); String kaffemerke = ...; oppdeterSalg.setString(2, kaffemerke); oppdaterSalg.executeUpdate(); int totalsalg = ...; oppdaterTotal.setInt(1, totalsalg); String kaffemerke = ...; oppdaterTotal.setString(2, kaffemerke); oppdaterTotal.executeUpdate(); forbindelse.commit(); } } catch (SQLException e) { <skriv ut feilmelding> if (forbindelse != null) { try { <meld fra om tilbakefĝring av transaksjon> forbindelse.rollback(); } catch (SQLException ex) { <skriv feilmelding> } } } finally { if (oppdaterSalg != null) { oppdaterSalg.close(); } if (oppdaterTotal != null) { oppdaterTotal.close(); } forbindelse.setAutoCommit(true); }
I dette eksemplet vil de to kompilerte SQL-setningene
oppdaterSalg og oppdaterTotal bli bekreftet samlet
og dermed utgjĝre en transaksjon. Hver gang commit-metoden blir
kalt (enten automatisk nċr vi er i auto-commit-modus eller eksplisitt ellers),
sċ vil alle endringer som fĝlge av setninger i transaksjonen bli gjort
permanente.
Generelt bĝr en bare gċ ut av auto-commit-modus nċr en ĝnsker ċ utfĝre transaksjoner. I eksemplet blir derfor forbindelsen satt tilbake igjen til auto-commit-modus nċr transaksjonen er fullfĝrt. Det er nemlig slik at en transaksjon medfĝrer at en del av databasen blir lċst inntil transaksjonen er avsluttet. En oppdatering fĝrer til at andre databaseforbindelser ikke fċr tilgang til de berĝrte dataene i det hele tatt. Dersom dette skjer i stor utstrekning, kan det fĝre til konflikter med andre brukere av databasen.
RowSet-hendelserJeg minner om at i utgangspunktet er et ResultSet verken
skrollbart eller oppdaterbart, se ovenfor,
mens et RowSet derimot er begge deler.
Hver gang det skjer en endring i et RowSet-objekt ved at
markĝren til RowSet-objektet flytter seg, en rad har endret seg, eller hele objektet har
endret seg, vil det skje en hendelse av type
RowSetEvent.
Denne hendelsen er det mulig ċ lytte pċ ved hjelp av et lytteobjekt av type
RowSetListener.
Det vil vĉre aktuelt ċ la et slikt lytteobjekt kommunisere med
den grafiske skjermkomponenten som viser innholdet av
RowSet-objektet pċ skjermen, slik at lytteobjektet kan
sette i gang relevant oppdatering
av skjermvisningen. Et opplegg for dette blir skissert lenger ute i dette notatet,
der innholdet av et RowSet-objekt er tenkt vist i en JTable.
For ċ definere en RowSetListener mċ vi
implementere de tre metodene som er listet opp i fĝlgende skisse:
import javax.sql.*; class Radsettlytter implements RowSetListener { public void cursorMoved(RowSetEvent e) { //Markĝren til RowSet-objektet har flyttet seg. //Kan vĉre aktuelt ċ melde fra om dette til brukeren. } public void rowChanged(RowSetEvent e) { //En rad har endret innhold, eller er blitt fjernet. //Oppdatering av skjermbildet er aktuelt, eventuelt ogsċ en //melding til brukeren. } public void rowSetChanged(RowSetEvent e) { //Hele radsettet har endret seg, f.eks. fordi en rad er fjernet //eller lagt til. Oppdatering av skjermbildet er aktuelt, //eventuelt ogsċ en melding til brukeren. } }
Metoden rowSetChanged vil bli aktivert blant annet av
RowSet-metoden execute (som er aktuell i interaktive sammenhenger),
cursorMoved blir aktivert av alle metodene for flytting av markĝren i et
RowSet, mens rowChanged blir aktivert av blant annet
RowSet-metoden updateRow.
Vi registerer en RowSetListener for et RowSet-objekt ved
ċ gjĝre kall pċ dets metode addRowSetListener.
RowSet i en JTableSiden et RowSet inneholder rader av tabelldata, vil det
i et javaprogram vĉre naturlig ċ vise dataene i en JTable. Den
kan vi ogsċ programmere slik at den kan brukes interaktivt til oppdatering av
databasen, i kombinasjon med andre grafiske brukerkomponenter som
vi kjenner fra javaprogrammer. Bruken av de vanligste grafiske skjermkomponentene er omtalt
i notatet
Grafiske brukergrensesnitt, grunnleggende komponenter,
mens bruk av mer avanserte komponenter er omtalt i
Grafiske brukergrensesnitt, spesialiserte komponenter.
Bruk av JTable er forklart i
Hvordan programmere tabeller av type JTable.
Som der forklart,
vil det i de fleste tilfelle vĉre nĝdvendig ċ definere en egen tabellmodell
for tabellen vċr. Jeg minner om at en tabellmodell fċr vi enklest definert ved ċ definere
en subklasse til AbstractTableModel. I den subklassen mċ vi minst redefinere
de tre metodene getRowCount, getColumnCount og getValueAt.
Som regel er det ogsċ ĝnskelig ċ redefinere metoden getColumnName.
Dersom tabellen skal kunne brukes til oppdatering av RowSet-objektet,
og dermed til oppdatering av databasen, mċ vi dessuten angi hvilke tabellkolonner
som skal vĉre editerbare, ved at vi implementerer tabellmodellens metode
isCellEditable, og for at oppdatering skal skje, mċ vi implementere
tabellmodellens metode setValueAt. Denne siste mċ da sĝrge for
at bċde tabellcellen og RowSet-objektet blir oppdatert.
Nċr tabellmodellen skal brukes av en tabell som skal vise data fra et RowSet,
mċ den ha tilgang til dette i form av et datafelt.
Nedenfor er det skissert en slik tabellmodell. I modellen er det lagt inn
noen testverdier til bruk for det tilfellet at den for ĝyeblikket blir brukt uten ċ vĉre
knyttet til en database. I modellen er det ikke implementert oppdatering av
tabellceller og databaseverdier, bare visning av eksisterende databaseinnhold.
1 import java.sql.*; 2 import javax.sql.*; 3 import javax.swing.table.AbstractTableModel; 4 5 public class RowSetTabellmodell extends AbstractTableModel 6 { 7 // RowSet-objektet som skal vises i tabellen 8 private RowSet rowSet = null; 9 10 public RowSet getRowSet() 11 { 12 return rowSet; 13 } 14 15 public void setRowSet(RowSet radsett) 16 { 17 if (radsett != null) 18 { 19 rowSet = radsett; 20 fireTableStructureChanged(); //se forklaring nedenfor 21 } 22 } 23 24 //Setter antall rader i tabellen lik antall rader i radsettet 25 public int getRowCount() 26 { 27 try 28 { 29 if (rowSet != null) 30 { 31 rowSet.last(); 32 return rowSet.getRow(); //Returnerer aktuelt radnummer 33 } 34 } 35 catch (Exception ex) 36 { 37 ex.printStackTrace(); 38 } 39 40 return 5; //Testverdi til ċ bruke nċr ingen database finnes. 41 } 42 43 //Setter antall kolonner i tabellen lik antall kolonner i radsettet 44 public int getColumnCount() 45 { 46 try 47 { 48 if (rowSet != null) 49 { 50 return rowSet.getMetaData().getColumnCount(); 51 } 52 } 53 catch (SQLException ex) 54 { 55 ex.printStackTrace(); 56 } 57 58 return 5; //Testverdi til ċ bruke nċr ingen database finnes. 59 } 60 61 //Bestemmer verdi for tabellcelle lik den verdi som er pċ samme 62 //rad og kolonne i radsettet. 63 public Object getValueAt(int rad, int kolonne) 64 { 65 try 66 { 67 if (rowSet != null) 68 { 69 rowSet.absolute(rad + 1); //husk at i JTable starter rad- og 70 //kolonnenummerering pċ 0 71 //mens den i radsettet starter pċ 1. 72 return rowSet.getObject(kolonne + 1); 73 } 74 } 75 catch (SQLException sqlex) 76 { 77 sqlex.printStackTrace(); 78 } 79 80 return "Testverdi"; //Til bruk nċr det ikke finnes noen database. 81 } 82 83 //Setter kolonnenavn i tabell lik tilsvarende kolonnenavn i radsettet 84 public String getColumnName(int kolonne) 85 { 86 try 87 { 88 if (rowSet != null) 89 return rowSet.getMetaData().getColumnLabel(kolonne + 1); 90 } 91 catch (SQLException ex) 92 { 93 ex.printStackTrace(); 94 } 95 96 return super.getColumnName(kolonne); //Nċr det ikke finnes 97 //noen database. 98 } 99 100 /* 101 * Dersom tabellen skal kunne brukes til oppdatering av databasen, 102 * mċ vi i tillegg implementere metoden isCellEditable for ċ 103 * angi hvilke celler som skal vĉre editerbare, og vi mċ 104 * implementere metoden setValueAt for at oppdatering skal 105 * finne sted. Det kan ogsċ vĉre aktuelt ċ definere egen 106 * celleeditor for enkelte av de editerbare tabellcellene. 107 */ 108 }
Pċ linje 20 i klassen ovenfor blir det gjort kall pċ metoden
fireTableDataChanged. Dette er en metode som klassen arver fra
AbstractTableModel. Metoden varsler alle lyttere om at tabellstrukturen
har endret seg. I dette tilfelle vil det blant annet medfĝre at tabellmodellen vil
bli fylt pċ ny med data hentet fra RowSet-objektet og den oppdaterte
tabellmodellen vil bli satt som tabellmodell for tabellen, slik at skjermvisningen
av dens innhold ogsċ vil bli oppdatert. Legg for ĝvrig merke til hvordan vi
bruker RowSet-objektet til ċ bestemme antall rader i tabellen,
kolonnenavnene, og hvilken verdi som skal vises i hver tabellcelle.
For ċ fċ tak i antall kolonner trenger vi radsettets metadata.
Nċr vi bestemmer verdi for tabellcellene, er det viktig ċ huske pċ at
indekseringen for rader og kolonner starter pċ 0 i tabellen, mens
den starter pċ 1 i radsettet.
Dersom vi bare skal vise de dataene som et RowSet inneholder,
trenger vi ikke noe annet enn en JTable for ċ gjĝre det, bortsett
fra at vi selvsagt trenger tilleggsfunksjonalitet for blant annet innlesing av
av brukernavn og passord, og for ċ opprette forbindelse med databasen. Men dersom
vi i tillegg ĝnsker ċ kunne redigere databaseinnholdet, trenger vi noe mer.
Rett nok sċ vet vi at det er mulig ċ redigere tabellceller i en JTable,
men da kan vi bare oppnċ ċ endre innhold av det RowSet som tabellen
henter sine data ifra. Som nevnt ovenfor, vil et
CachedRowSet ikke ha kontinuerlig forbindelse med databasen.
Det er nĝdvendig ċ gjĝre kall pċ metoden acceptChanges for ċ fċ
overfĝrt endringene til databasen. Og for ċ fċ gjort dette kallet, trenger vi
for eksempel en knapp til ċ klikke pċ. Det samme er tilfelle dersom vi ĝnsker ċ
fjerne eller sette inn en ny rad i radsettet. For ċ navigere mellom radene i radsettet
kan vi velge tabellrader i tabellen, men i tillegg kan det kanskje vĉre greit ċ
ha knapper for dette, slik at vi gjĝr et lite skille mellom navigasjon i radsettet
og navigasjon i tabellen. Uansett sċ mċ vi iallfall sĝrge for at navigasjon i
tabell og radsett blir synkronisert, det vil si at radene i tabellen svarer til
radene i radsettet. Her er det viktig ċ huske pċ at den interne indekseringen er
forskjellig: I tabellen starter indekseringen pċ 0, mens den i
radsettet starter pċ 1.
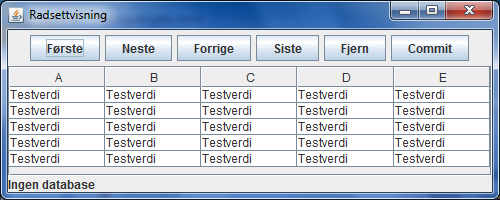
Vi skal definere et panel som kan danne grunnlag for en radsetteditor. Det skal, pċ grunnlag av tabellmodellen som er skissert ovenfor, inneholde en tabell som kan vise radsettdata, og knapper for navigasjon i radsettet, samt for fjerning av rad og overfĝring av endringer til database. Oppdatering av celleverdier og innsetting av ny rad er ikke programmert, men det er lett ċ supplere med det. Panelet inneholder ogsċ en statuslinje som kan informere brukeren om hva som skjer eller har skjedd. Panelet er tenkt ċ kunne inngċ i et vindu der redigering av en database kan foretas. I tillegg til panelet mċ dette vinduet inneholde funksjonalitet for innlesing av brukernavn og passord, samt annet som behĝves for ċ knytte seg til en eksisterende database. Fĝlgende bilde viser selve panelet der tabellen er fylt med de testdata som er bestemt av tabellmodellen ovenfor.
Koden for panelet er gjengitt nedenfor. Vi merker oss her fĝlgende:
DefaultListSelectionModel
for tabellen, og den blir pċ linje 44 satt som valgmodell for tabellen.
Dette er noe vi vanligvis ikke behĝver ċ gjĝre, men i dette tilfelle trenger vi
ċ referere til valgmodellen for ċ kunne synkronisere tabellradene med radene
i radsettobjektet, slik at fĝrste rad i tabellen svarer til fĝrste rad i
radsettobjektet, og tilsvarende videre utover. Slik synkronisering blir utfĝrt av metoden
setTabellmarkĝr, definert pċ linje 72 til 77. Metoden blir kalt opp
av metoden flyttMarkĝr, definert pċ linje 80 til 103, som utfĝrer
flytting av radsettets markĝr. Metoden blir kalt opp nċr vi klikker pċ knappene
for navigering i radsettet. Synkroniseringsmetoden blir ogsċ kalt opp av metoden
velgRadsettrad, definert pċ linje 132 til 147.
Denne metoden blir kalt opp nċr brukeren velger en
tabellrad ved ċ klikke pċ den. Synkroniseringsmetoden sĝrger da for at
radsettmarkĝren blir flyttet til tilsvarende rad i radsettet. Synkronisering er
ogsċ nĝdvendig i det tilfellet at en rad blir fjernet fra tabell og radsett.
Det skjer nċr metoden fjernRad, definert pċ linje 108 til 128 blir kalt opp
som fĝlge av at det blir klikket pċ Fjern-knappen.acceptChanges. Kall pċ denne blir foretatt
pċ linje 174 av lytteobjektet for Commit-knappen.1 import javax.swing.*; 2 import javax.swing.table.*; 3 import javax.swing.event.*; 4 import java.awt.*; 5 import java.awt.event.*; 6 import java.sql.*; 7 import javax.sql.*; 8 import com.sun.rowset.CachedRowSetImpl; 9 import java.sql.SQLException; 10 11 public class Tabelleditor extends JPanel 12 { 13 private JButton fĝrste = new JButton("Fĝrste"); 14 private JButton neste = new JButton("Neste"); 15 private JButton forrige = new JButton("Forrige"); 16 private JButton siste = new JButton("Siste"); 17 private JButton fjern = new JButton("Fjern"); 18 private JButton commit = new JButton("Commit"); 19 private JLabel statuslabel = new JLabel(); 20 21 private RowSetTabellmodell tabellmodell = new RowSetTabellmodell(); 22 private DefaultListSelectionModel listevalgmodell = 23 new DefaultListSelectionModel(); 24 private JTable tabell = new JTable(); 25 private RowSet radsett = null; 26 27 public Tabelleditor() 28 { 29 JPanel knappepanel = new JPanel(); 30 knappepanel.add(fĝrste); 31 knappepanel.add(neste); 32 knappepanel.add(forrige); 33 knappepanel.add(siste); 34 knappepanel.add(fjern); 35 knappepanel.add(commit); 36 37 setLayout(new BorderLayout()); 38 add(knappepanel, BorderLayout.PAGE_START); 39 add(new JScrollPane(tabell), BorderLayout.CENTER); 40 add(statuslabel, BorderLayout.PAGE_END); 41 42 //Setter valgmodell for tabellen. Behĝves for ċ fċ synkronisert 43 //dens markĝr med markĝren for radsettet. 44 tabell.setSelectionModel(listevalgmodell); 45 46 Knappelytter knappelytter = new Knappelytter(); 47 fĝrste.addActionListener(knappelytter); 48 neste.addActionListener(knappelytter); 49 forrige.addActionListener(knappelytter); 50 siste.addActionListener(knappelytter); 51 fjern.addActionListener(knappelytter); 52 commit.addActionListener(knappelytter); 53 54 listevalgmodell.addListSelectionListener(new Listevalgslytter()); 55 } 56 57 public void setRowSet(RowSet r) 58 { 59 radsett = r; 60 if (radsett != null) 61 radsett.addRowSetListener(new Radsettlytter()); 62 tabellmodell.setRowSet(radsett); 63 tabell.setModel(tabellmodell); 64 tabellmodell.fireTableStructureChanged(); 65 66 TableRowSorter<RowSetTabellmodell> sorterer = 67 new TableRowSorter<>(tabellmodell); 68 tabell.setRowSorter(sorterer); 69 } 70 71 //Synkroniserer tabellmarkĝren med markĝren for radsettet. 72 private void setTabellmarkĝr() throws SQLException 73 { 74 int rad = radsett.getRow(); 75 listevalgmodell.setSelectionInterval(rad - 1, rad - 1); 76 statuslabel.setText("Aktuelt radnummer: " + rad); 77 } 78 79 //Flytter radsettmarkĝren til valgt posisjon. 80 private void flyttMarkĝr(String posisjon) 81 { 82 try 83 { 84 if (posisjon.equals("fĝrste")) 85 radsett.first(); 86 else if (posisjon.equals("neste") && !radsett.isLast()) 87 radsett.next(); 88 else if (posisjon.equals("forrige") && !radsett.isFirst()) 89 radsett.previous(); 90 else if (posisjon.equals("siste")) 91 radsett.last(); 92 setTabellmarkĝr(); //synkroniserer tabellmarkĝren med 93 //radsettmarkĝren 94 } 95 catch (NullPointerException e) 96 { 97 statuslabel.setText("Ingen database"); 98 } 99 catch (SQLException ex) 100 { 101 statuslabel.setText(ex.toString()); 102 } 103 } 104 105 //Fjerner en rad fra radsettet, oppdaterer radsettmarkĝr 106 //og synkroniserer tabellmarkĝr med denne. 107 //Radsettlytterern vil sĝrge for oppdatering av tabellvisning. 108 private void fjernRad() 109 { 110 try 111 { 112 int aktuellRad = radsett.getRow(); 113 radsett.deleteRow(); 114 if (radsett.isAfterLast()) 115 radsett.last(); 116 else if (radsett.getRow() >= aktuellRad) 117 radsett.absolute(aktuellRad); 118 setTabellmarkĝr(); 119 } 120 catch (NullPointerException e) 121 { 122 statuslabel.setText("Ingen database"); 123 } 124 catch (SQLException ex) 125 { 126 statuslabel.setText(ex.toString()); 127 } 128 } 129 130 //Synkroniserer radsettmarkĝr med tabellmarkĝren 131 //nċr brukeren velger en tabellrad. 132 private void velgRadsettrad() 133 { 134 int valgtTabellrad = tabell.getSelectedRow(); 135 try 136 { 137 if (valgtTabellrad != -1 && radsett != null) 138 { 139 radsett.absolute(valgtTabellrad + 1); 140 setTabellmarkĝr(); 141 } 142 } 143 catch (SQLException ex) 144 { 145 statuslabel.setText(ex.toString()); 146 } 147 } 148 149 private void visMelding(String melding) 150 { 151 JOptionPane.showMessageDialog(null, melding); 152 } 153 154 private class Knappelytter implements ActionListener 155 { 156 public void actionPerformed(ActionEvent e) 157 { 158 Object kilde = e.getSource(); 159 if (kilde.equals(fĝrste)) 160 flyttMarkĝr("fĝrste"); 161 else if (kilde.equals(neste)) 162 flyttMarkĝr("neste"); 163 else if (kilde.equals(forrige)) 164 flyttMarkĝr("forrige"); 165 else if (kilde.equals(siste)) 166 flyttMarkĝr("siste"); 167 else if (kilde.equals(fjern)) 168 fjernRad(); 169 else if (kilde.equals(commit)) 170 { 171 try 172 { 173 //Oppdaterer databasen med endringene i radsettet: 174 ((CachedRowSetImpl) radsett).acceptChanges(); 175 } 176 catch (NullPointerException npe) 177 { 178 statuslabel.setText("Ingen database"); 179 } 180 catch (SQLException ex) 181 { 182 ex.printStackTrace(); 183 } 184 } 185 } 186 } 187 188 private class Listevalgslytter implements ListSelectionListener 189 { 190 public void valueChanged(ListSelectionEvent e) 191 { 192 velgRadsettrad(); 193 } 194 } 195 196 private class Radsettlytter implements RowSetListener 197 { 198 public void cursorMoved(RowSetEvent e) 199 { 200 //Markĝren til RowSet-objektet har flyttet seg. 201 visMelding("Markĝr for radsett har flyttet seg."); 202 } 203 204 public void rowChanged(RowSetEvent e) 205 { 206 //En rad har endret innhold, eller er blitt fjernet. 207 tabellmodell.fireTableStructureChanged(); 208 visMelding("En rad er endret."); 209 } 210 211 public void rowSetChanged(RowSetEvent e) 212 { 213 //Hele radsettet har endret seg, f.eks. fordi en rad er fjernet 214 //eller lagt til. 215 tabellmodell.fireTableStructureChanged(); 216 visMelding("Radsettet er endret."); 217 } 218 } 219 }
For lettere ċ kunne spore opp feil etc., kan det vĉre lurt ċ fċ skrevet en logg over det som er blitt gjort med databasen. For ċ opprette logg-fil kan vi skrive fĝlgende instruksjoner:
PrintWriter loggfil = new PrintWriter(new FileWriter(filnavn)); DriverManager.setLogWriter(loggfil);
Dette blir nċ en tekstfil som kan leses av en hvilken som helst editor, for eksempel NetBeans-editoren eller TextPad. For ċ fċ hentet inn fila til et program, kan vi skrive
PrintWriter logg = DriverManager.getLogWriter();
Dersom en database allerede eksisterer, kan vi bruke JDBC til ċ opprette tabeller i den.
Vi tenker oss at vi har en bokdatabase der vi skal opprette en tabell
forfattere der hver rad har en heltallsverdi for forfatterID
og to strenger for fornavn og etternavn.
For ċ opprette denne tabellen, kunne vi brukt fĝlgende
SQL-setning:
String lagForfattertabell = "CREATE TABLE forfattere " + "(forfatterID INTEGER, fornavn VARCHAR(50), " + "etternavn VARCHAR(50))";
Vi tenker oss videre at vi har opprettet forbindelse med bokdatabasen som tidligere beskrevet:
Connection forbindelse = ...;
og opprettet Statement-objekt:
Statement setning = forbindelse.createStatement();
For ċ opprette tabellen forfattere i bokdatabasen
kan vi nċ skrive fĝlgende instruksjon:
setning.executeUpdate(lagForfattertabell);
Instruksjonene som ble beskrevet ovenfor vil bare opprette strukturen til
tabellen forfattere. Tabellen vil forelĝpig ikke inneholde noe data.
Vi skal nċ se pċ hvordan vi radvis kan legge inn data i tabellen.
Vi mċ da passe pċ ċ liste opp kolonnedataene i samme rekkefĝlge som
kolonnene ble deklarert da tabellen ble opprettet.
Et Statement-objekt kan brukes om igjen flere ganger. For ċ
legge inn en rad med data der forfatterID er lik 1,
fornavn er lik Donald E. og etternavn
er lik Knuth, kan vi derfor bruke Statement-objektet
som ble opprettet foran og skrive fĝlgende:
setning.executeUpdate("INSERT INTO forfattere " + "VALUES (1, 'Donald E.', 'Knuth')");
Merk at det er nĝdvendig med et
mellomrom mellom forfattere og VALUES. Merk ogsċ at
tekststrengene for verdiene som skal settes inn er avgrenset av enkle
apostrofer. Dette er fordi de befinner seg mellom de doble sitattegnene som
avgrenser tekststrengen som er parameter til executeUpdate.
For de fleste databasesystemer sċ brukes regelen om ċ alternere mellom doble
og enkle sitattegn for ċ indikere at ting ligger inni hverandre.
INSERT-setningen finnes i flere varianter. Som parameter til
executeUpdate kan vi selvsagt bruke en hvilken som helst
variant.
Som eksempel tenker vi oss at det i tabellen forfattere er blitt
registrert galt fornavn pċ forfatteren med forfatterID lik 3 og at
riktig fornavn er Tom. For ċ rette opp dette, kunne vi med et
Statement-objekt setning, opprettet som tidligere
forklart, skrevet instruksjonen
setning.executeUpdate("UPDATE forfattere " +
"SET fornavn = 'Tom' WHERE forfatterID LIKE 3");
Det er ingen ting i veien for at vi foretar oppdatering av flere kolonner samtidig pċ en rad. Vi skiller da de forskjellige SET-delene av UPDATE-setningen med komma.
executeUpdateMetoden executeUpdate returnerer en int-verdi
som angir hvor mange rader i tabellen som ble oppdatert. Dersom setningen
som ble utfĝrt gikk ut pċ ċ definere tabellstruktur, for eksempel opprette
en tabell, vil tallet 0 bli returnert.
Copyright © Kjetil Grĝnning og Eva Hadler Vihovde 2012