Innholdsoversikt for programutvikling
interface Collection<E>interface List<E>Vector-klassen versus ArrayListHashMap-klassen versus HashtableSortedMapDet som i datasammenheng menes med det engelske ordet 'collection', er en
samling av elementer. Java-biblioteket har et
interface Collection som skal representere
dette begrepet. Dette interface sier ikke noe spesielt om hva slags objekter
samlingen skal bestĺ av eller hvordan den skal vćre organisert. (Samlingen kan
imidlertid ikke inneholde verdier av primitive datatyper, den kan bare inneholde
objekter.) I interface Collection blir det bare listet
opp noen metoder som skal kunne brukes pĺ alle samlinger av den typen interfacet beskriver. Det er i
hovedsak metoder for ĺ sette inn og fjerne objekter, sjekke om objekter
finnes, og for ĺ gjennomlřpe samlingen.
Det skilles mellom fire hovedtyper av samlinger, avhengig av om duplikater er tillatt eller ikke, og om det er noen form for ordning eller ikke av elementene. Typene er som fřlger:
| Ordnet | Ikke ordnet | |
|---|---|---|
| Duplikater tillatt | Liste | Multimengde |
| Duplikater ikke tillatt | Hashtabell | Mengde |
Fra fřr av er vi kjent med samlinger av type array og liste.
Array-typen er en av standard-datatypene i java, det vil si innebygget i selve sprĺket.
Lister har vi programmert
selv. Pĺ bĺde arrayer og lister har vi utfřrt diverse typer operasjoner.
Det kan vćre andre typer operasjoner som ogsĺ kan vćre řnskelige ĺ utfřre
i enkelte situasjoner. Bibliotek-klassen
java.util.Arrays
inneholder et stort antall
static-metoder for utfřring av
standardoperasjoner pĺ arrayer. Arrayene som operasjonene skal utfřres pĺ,
settes inn som parametre i metodekallene.
Alle klasser og interface som har med samlinger (collections) ĺ gjřre,
befinner seg i pakken java.util.
Det blir brukt interface for ĺ beskrive begrepene som definerer
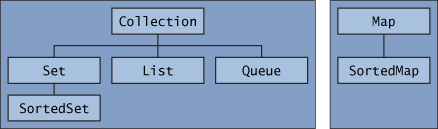
de forskjellige typene samlinger. Fřlgende figur viser en oversikt over de
interface'ene i java.util som vi skal se nćrmere pĺ.
Av figuren gĺr det fram at Set, List og Queue er
subinterface til Collection, som betyr at de definerer spesielle typer
collection. SortedSet er i sin tur subinterface til Set
og definerer en spesiell type mengde, nemlig ordnet (sortert) mengde. De to
interfacene Map og SortedMap definerer strukturer som
svarer til det matematiske begrepet avbildning eller tilordning,
som gir en relasjon mellom (nřkkel)verdier (funksjonsargumenter) og tilhřrende
(funksjons)verdier, for eksempel mellom personer og deres bostedsadresse.
(Matematisk sett gir dette en mange-til-en-relasjon: For hver nřkkelverdi er
det tilordnet bare én bestemt verdi, men denne verdien kan bli tilordnet
av flere forskjellige nřkkelverdier. Eksempler: hver person har bare én
bestemt bostedsadresse, men pĺ denne adressen kan det bo flere personer.
En funksjon har bare én bestemt funksjonsverdi for hver argumentverdi,
men det kan vćre flere forskjellige argumentverdier (x-verdier) som gir samme
funksjonsverdi.)
I pakken java.util finnes det ogsĺ klasser som gir en implementasjon
av de interface som er vist pĺ figuren ovenfor. For noen av dem
finnes det flere forskjellige implementasjoner. For eksempel finnes klassene
ArrayList og
LinkedList som gir to forskjellige
implementasjoner av listebegrepet. Disse kan vi altsĺ bruke som alternativ
til de listeklassene vi selv har implementert. Vĺr egen implementasjon var
altsĺ i og for seg unřdvendig, men pĺ den andre side er det svćrt nyttig
ĺ vite hva som egentlig foregĺr 'bak kulissene' nĺr en bruker den ene
eller den andre av en ferdigprogrammert implementasjon. Det er ogsĺ slik at
de nevnte implementasjonene, siden de ikke er tilpasset en bestemt datatype,
inneholder en del operasjoner som vi ikke alltid trenger. Derfor kan det
i mange situasjoner vćre vel sĺ greit selv ĺ programmere en liste som er
'skreddersydd' for den datatypen den skal inneholde.
Alle klasser i java.util som implementerer noen av de nevnte
interface, implementer ogsĺ interface Serializable, slik at
objektene kan lagres pĺ fil, forutsatt at de objektene vi setter inn i dem
ogsĺ implementerer dette interface.
interface List definerer en liste som en
ordnet samling (sekvens) av elementer. Ordnet betyr her at hvert element er
tilordnet en indeksposisjon (fra 0 og oppover). En liste kan inneholde
duplikater.
List er et subinterface til
Collection og har derfor alle metoder i dette.
I tillegg definerer det noen metoder som er spesifikke for lister. Det er
blant annet metoder for
Klassebiblioteket inneholder to klasser som implementerer listebegrepet:
ArrayList gir en array-implementasjon.
Den underliggende array som inneholder elementene blir automatisk utvidet ved behov.LinkedList gir en sammenkjedet
implementasjon. Denne har i tillegg egne metoder for ĺ hente ut, sette inn,
eller fjerne element i den ene eller den andre enden, slik at lista kan
brukes som stakk eller kř.I mange tilfeller vil bruk av ArrayList
vćre mest effektivt. Ut fra kjennskap til arrayer vet vi at det er tilfelle
dersom vi gjřr mye bruk av referanse til objekter ved hjelp av indekser.
I en array kan en da gĺ rett inn pĺ vedkommende indeksposisjon, mens man
i en sammenkjedet liste mĺ sřke linećrt forover eller bakover for ĺ finne
en gitt indeksposisjon. Men dersom vi har en liste der det er mye innsetting
eller fjerning, er en sammenkjedet liste mer effektiv. Sćrlig vil dette vćre
tilfelle dersom innsetting eller fjerning skjer i fřrste halvdel av lista.
I tilfelle array-implementasjon vil det da bli mye flytting av objekter.
(Egentlig er det flytting av referanser til objekter det er snakk om.)
I notat Introduksjon til programmering, kapittel 10
Objektorientert programmering: polymorfisme,
ble det gitt et eksempel pĺ
klassehierarki for utlĺnsobjekter.
Koden for dette finnes i fila
Utlaansobjekt.java.
Til den abstrakte klassen Utlaansobjekt ble det definert flere
subklasser, blant annet den ikke-abstrakte klassen Bok.
Vi tenker oss nĺ at vi skal opprette en liste av slike utlĺnsobjekter og
velger ĺ lage den i form av en LinkedList. For enkelhets skyld
skal vi i dette eksemplet bare lage metoder for ĺ sette inn et nytt objekt
bakerst i lista, samt ĺ hente ut objektet som er bakerst i lista. Ved bruk
av metoder spesifisert i interface List kunne vi ha skrevet en
klasse for dette pĺ fřlgende mĺte:
import java.util.*; class Mediatek { private List register = new LinkedList(); public void settInnUtlaansobjekt( Utlaansobjekt obj ) { register.add( obj ) ; } public Utlaansobjekt hentSiste() { int antall = register.size(); if ( antall > 0 ) return (Utlaansobjekt) register.get( antall - 1 ); else return null; } }
Vi legger her merke til at ved bruk av List-metoden
get, mĺ vi foreta typekonvertering til den typen som vĺr metode
skal returnere. Grunnen til dette er at returverdien fra get-metoden
er av type Object. For řvrig ville det her ha lřnt seg ĺ deklarere
lista register til ĺ vćre av type LinkedList istedenfor
av den generelle typen List, for da kunne vi gjort bruk av metoden
getLast som i dette tilfelle ville vćrt mer effektiv, siden den
gjřr bruk av siste-pekeren til den sammenkjedete lista.
Vi tenker oss nĺ videre at vi vil lage et program der det er en samling utlĺnsobjekter som utelukkende bestĺr av břker. I et slikt program kunne vi hatt fřlgende instruksjoner:
//Et Mediatek som bare skal inneholde břker Mediatek boksamling = new Mediatek(); ... //Skal hente ut siste bok fra boklista: Bok siste = (Bok) boksamling.hentSiste(); ...
Vi merker oss igjen at vi er nřdt til ĺ foreta den brysomme typekonverteringen.
Selv om vi vet at det bare er Bok-objekter vi har satt inn, kan
ikke kompilatoren vite det. For řvrig ville kompilatoren tillate at det ogsĺ
ble satt inn objekter av de andre subklassetypene til Utlaansobjekt,
og dersom det hadde skjedd, ville vi under kjřring fĺtt en ClassCastException
i tilfelle vi prřvde ĺ konvertere disse til type Bok.
Blant annet for at vi skal slippe slik brysom typekonvertering som vi har eksempler pĺ ovenfor, og ogsĺ slippe uforutsette kjřrefeil pĺ grunn av forsřk pĺ typekonvertering mellom typer som ikke er kompatible, er det fra og med javaversjon 1.5 (ogsĺ kalt 5.0) innfřrt sĺkalte generiske eller parametriserte typer. Det gĺr ut pĺ at vi ved hjelp av en sĺkalt typeparameter spesifiserer hvilken datatype en samling objekter kan inneholde. I tillegg til at vi slipper den brysomme typekonverteringen, oppnĺr vi at det er typesjekking allerede nĺr programmet blir kompilert, slik at det ikke blir mulig ĺ sette inn i samlingen andre typer objekter enn den typen den er bestemt til ĺ inneholde.
Hensikten med generisk programmering, er ĺ skrive kode som kan brukes om igjen
for mange forskjellige typer objekter.
Nedenfor er vĺr Mediatek-klasse skrevet om slik at den blir en generisk datatype. Den har da
en typeparameter E for datatypen til de objektene den skal inneholde. Den blir
dermed en generisk datatype med én enkelt formell
typeparameter E.
1 import java.util.*; 2 3 4 class Mediatek<E> 5 { 6 private List<E> register = new LinkedList<E>(); 7 8 public void settInnUtlaansobjekt( E obj ) 9 { 10 register.add( obj ) ; 11 } 12 13 public E hentSiste() 14 { 15 int antall = register.size(); 16 if ( antall > 0 ) 17 return register.get( antall - 1 ); 18 else 19 return null; 20 } 21 }
I et tenkt program der vi skal bruke den generiske datatypen, mĺ vi istedenfor
den formelle typeparameteren skrive klassenavnet for den klassen som definerer objektene
som vi vil bruke i det aktuelle tilfellet. Dersom vi for eksempel har til hensikt
ĺ sette inn
Bok-objekter i mediateket vĺrt, kan vi nĺ skrive fřlgende instruksjoner:
//Et Mediatek som bare skal inneholde břker Mediatek<Bok> boksamling = new Mediatek<Bok>(); ... //Skal hente ut siste bok fra boklista: Bok siste = boksamling.hentSiste(); ... //Det er ikke nřdvendig ĺ foreta noen endringer i Bok-klassen //eller de andre klassene i hierarkiet som den tilhřrer.
Nĺr vi oppretter Mediatek-objektet boksamling,
mĺ vi spesifisere ved hjelp av en aktuell typeparameter hvilken type
objekter klassen skal inneholde.
Fra og med javaversjon 7 er kompilatoren gitt střrre muligheter for ĺ kunne finne ut hva datatypen er ut fra sammenhengen nĺr det blir opprettet objekter av parametriserte typer. Istedenfor instruksjonen
Mediatek<Bok> boksamling = new Mediatek<Bok>();
som er brukt ovenfor, er det i Java 7 tillatt ĺ forenkle til
Mediatek<Bok> boksamling = new Mediatek<>();
Paret <> av spissparenteser blir uformelt kalt for
diamantoperatoren.
Selv om java 1.5 og seinere versjoner definerer de forskjellige
komponentene som inngĺr i Collections-rammeverket til ĺ vćre generiske datatyper,
er det fortsatt anledning til ĺ bruke det pĺ den gamle mĺten, slik det ble gjort
i det fřrste eksemplet ovenfor. Objektene som samlingene inneholder blir da tolket
til ĺ vćre av type Object. Vi blir da nřdt til ĺ foreta slike
typekonverteringer som ble gjort i det nevnte eksemplet. Ved ĺ bruke generiske
datatyper pĺ samlinger (collections), oppnĺr vi fřlgende fordeler:
Pĺ grunn av de nevnte fordelene blir det anbefalt at klassene i Collections-rammeverket brukes som generiske datatyper. Det blir gjort i beskrivelsene og eksemplene i det fřlgende.
Det anbefales at det som navn pĺ en formell typeparameter brukes én enkelt stor bokstav. Dette řker lesbarheten av programmer ved ĺ lage et klart skille mellom klassenavn og navn pĺ typeparametre. Fřlgende bokstaver er de vanligste ĺ bruke som formelle typeparametre:
T> — for TypeS> — for Type, nĺr T allerede er i brukE> — for Element (mye brukt i Collections-rammeverket)K> — for Key (nřkkel)V> — for ValueN> — for NumberSom aktuell typeparameter nĺr vi oppretter et objekt av en generisk
datatype, kan vi bruke en hvilken som helst klasse, men vi kan ikke bruke
primitive datatyper som for eksempel int.
Ordet 'boksing' har her ikke noe med boksesporten ĺ gjřre, men med det ĺ pakke noe inn i eller ut av en boks!
I Introduksjon til programmering, kapittel 5, ble det skrevet
litt om Innpakningsklasser.
Som nevnt ovenfor, er det i en samling definert av Collection-rammeverket
bare tillatt ĺ sette inn objekter, ikke verdier av primitive datatyper.
Ogsĺ i noen andre javasammenhenger er det bare tillatt ĺ bruke objekter. Blant
annet pĺ grunn av dette er det for alle de primitive datatypene definert
en tilsvarende klasse. Et objekt av klassen representerer den tilsvarende
verdien av primitiv datatype, og denne, eller eventuelt en
String-representasjon av den, mĺ brukes som konstruktřrparameter nĺr vi oppretter objektet.
Innpakningsklassene har navn som klart indikerer hvilken primitiv datatype de
representerer. Det er klassene
Integer,
Long
Float,
Double,
Short,
Byte,
Character
og
Boolean.
Innpakningsklassene er immutable, det vil si at nĺr et objekt fřrst er opprettet, sĺ er
det ikke mulig ĺ endre det. (Tilsvarende er for řvrig tilfelle med String-objekter.)
Innpakningsklassene er ogsĺ final, det
vil si at det er ikke mulig ĺ definere subklasser av dem.
Vi kan altsĺ ikke ha noen Collection bestĺende av primitive verdier.
Dersom vi for eksempel řnsker ĺ ha en liste med
int-verdier, sĺ mĺ vi definere den som
en List<Integer>, for eksempel ved
List<Integer> heltallsliste = new ArrayList<>();
Jeg minner dessuten om at bruk av diamantoperatoren forutsetter at vi bruker javaversjon 7
eller nyere. Fřr javaversjon 5 var det slik at nĺr vi skulle sette inn en verdi,
for eksempel 3, i en slik liste, sĺ mĺtte vi selv skrive kode for ĺ opprette
det nřdvendige Integer-objektet:
heltallsliste.add(new Integer(3));
Men fra og med javaversjon 5 er det i kompilatoren lagt inn automatikk for ĺ opprette objekter av innpakningsklasser, slik at vi kan skrive
heltallsliste.add(3);
Kompilatoren vil da oversette dette til koden som er skrevet ovenfor. Denne konverteringen kalles autoboksing.
Det motsatte er det ogsĺ lagt inn automatikk for, pĺ den mĺten at vi
kan tilordne en Integer-verdi til en
int-variabel:
int n = heltallsliste.get(i);
Dette blir av kompilatoren automatisk oversatt til
int n = heltallsliste.get(i).intValue();
Slik autoboksing og -utpakking virker til og med pĺ aritmetiske uttrykk. Det er for eksempel tillatt ĺ skrive slik som
Integer i = 3; i++;
Vi kan nesten fĺ inntrykk av at det er likegyldig om vi bruker primitiv
datatype eller den tilsvarende innpakningstypen. Men det er en viktig forskjell
iallfall nĺr det gjelder testing pĺ likhet. For ĺ teste pĺ likhet mellom
verdier av primitiv type bruker vi likhetsoperatoren ==. Den
kan vi ogsĺ bruke for objekter. Men det som det da testes pĺ, er om det blir
referert til samme objektet, altsĺ om pekerverdiene eller referansene er lik hverandre,
det vil si om det blir referert til samme sted i maskinens memory. For eksempel
ville fřlgende kode neppe gi det resultatet vi řnsket:
Integer m = 100;
Integer n = 100;
.
.
if (m == n)
...
Det er imidlertid tillatt for en javakompilator ĺ pakke inn like verdier i
det samme objektet, slik at sammenlikningen ovenfor faktisk kunne gi riktig
resultat. Men dette er noe vi ikke kan vćre sikre pĺ. Lřsningen er ĺ konsekvent
bruke equals-metoden dersom det er test pĺ likhet av innhold vi
řnsker ĺ utfřre. En svćrt vanlig feil er for řvrig ĺ glemme dette nĺr
String-verdier skal sammenliknes for likhet (av innhold).
interface Collection<E>Fřlgende kodelisting viser noe av innholdet i
interface Collection<E>:
public interface Collection<E> extends Iterable<E> { //Basic operations int size(); boolean isEmpty(); boolean contains(Object element); boolean add(E element); //optional boolean remove(Object element); //optional Iterator<E> iterator(); //Bulk operations boolean containsAll(Collection<?> c); boolean addAll(Collection<? extends E> c); //optional boolean removeAll(Collection<?> c); //optional boolean retainAll(Collection<?> c); //optional void clear(); //optional //Array operations Object[] toArray(); <T> T[] toArray(T[] a); }
Noe av symbolikken for de formelle typeparametrene som er brukt her har vi forelřpig ikke
vćrt borti. Den blir forklart seinere, nĺr vi fĺr bruk for den. Metoder som
det stĺr
//optional bak, er det ikke nřdvendig ĺ implementere for
klasser som implementerer interface Collection. Dersom vi prřver
ĺ gjřre kall pĺ en slik metode og den ikke er implementert av vedkommende
Collection-objekt, vil det bli kastet ut en
UnsupportedOperationException. Alle klassene i javas klassebibliotek
som implementerer interface Collection,
implementerer alle metodene.
interface List<E>Fřlgende kodelisting viser metoder
interface List<E>
har i tillegg til de som blir arvet fra interface Collection<E>.
public interface List<E> extends Collection<E> { //Positional access E get(int index); E set(int index, E element); //optional boolean add(E element); //optional void add(int index, E element); //optional E remove(int index); //optional abstract boolean addAll(int index, Collection<? extends E> c); //optional //Search int indexOf(Object o); int lastIndexOf(Object o); //Iteration ListIterator<E> listIterator(); ListIterator<E> listIterator(int index); //Range-view List<E> subList(int from, int to); }
List<E> blir implementert av klassene
LinkedList<E>
og
ArrayList<E>.
En iterator blir brukt til gjennomlřping av elementene i en samling.
interface Iterator<E>
spesifiserer fřlgende tre metoder:
E next() boolean hasNext() void remove()
Vi kan tenke oss en iterator som en markřr som er mellom
elementer i samlingen. Nĺr vi gjřr kall pĺ
next, vil iteratoren hoppe over
det neste elementet og returnere en peker til dette.
Kall pĺ remove vil fjerne elementet som sist
ble returnert av next.
List-metoden
iterator, som er
spesifisert i interface Collection<E>, returnerer et
Iterator-objekt av den beskrevne typen.
I tillegg finnes det for List-objekter
en iteratortype med tilleggsegenskaper. Denne er spesifisert av
interface ListIterator<E>
som er subinterface til Iterator<E>. Et slikt objekt
blir returnert av List-metoden
listIterator. En
ListIterator tillater, i tillegg til det
som blir arvet fra Iterator, gjennomlřping
i baklengs retning, samt ĺ sette inn eller erstatte elementer under
gjennomlřpingen, uavhengig av i hvilken retning gjennomlřpingen blir utfřrt.
(Siden baklengs gjennomlřping er mulig, skjřnner vi at den sammenkjedete
lista definert av klassen LinkedList er en toveis-liste: objektene
inneholder pekere til bĺde neste og til foregĺende objekt.)
Her fřlger en nćrmere beskrivelse av disse tilleggsegenskapene til en
ListIterator:
Bruker previous og
hasPrevious (istedenfor
next og
hasNext). Ved listeslutt (uavhengig av
gjennomlřpsretning):
NoSuchElementException.
add( <objekt> ) setter inn det nye
objektet pĺ et sted slik at neste kall pĺ
next vil bli uberřrt av innsettingen.
Neste kall pĺ previous ville ha returnert
det nye objektet.
remove fjerner siste element som ble
returnert av next eller
previous. Ikke tillatt ĺ utfřre dersom
add er blitt kalt etter siste kall pĺ
next eller
previous. (Forsřk pĺ dette resulterer i
IllegalStateException.)
set( <objekt> ) erstatter siste
element returnert av next eller
previous med det objekt som er parameter.
(Ikke tillatt ĺ utfřre dersom remove i
mellomtida er blitt kalt.)
I programmet
Listetest som er gjengitt nedenfor, blir det
opprettet to lister a og b av type
LinkedList<String>. I begge blir det lagt inn noen
navn ved bruk av add-metoden. Deretter skjer fřlgende:
- Navnene i b blir flettet inn blant navnene i
a, uten at b endres. Deretter skrives
a ut.
- Annet hvert navn i b blir fjernet. Deretter skrives b ut.
- Alle (gjenvćrende) navn som forekommer i b blir fjernet fra
a. Deretter skrives a ut.
I programmet legger vi spesielt merke til hvordan iteratorer blir brukt til ĺ gjennomlřpe listene. Ved kjřring viser programmet dialogboksen som er gjengitt pĺ fřlgende bilde.
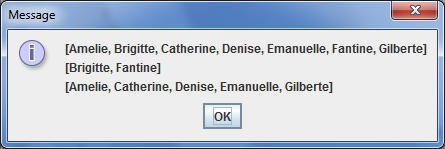
1 import javax.swing.*; 2 import java.util.*; 3 4 public class Listetest 5 { 6 public static void main(String[] args) 7 { 8 String output = ""; 9 List<String> a = new LinkedList<>(); 10 a.add("Amelie"); 11 a.add("Catherine"); 12 a.add("Emanuelle"); 13 14 List<String> b = new LinkedList<>(); 15 b.add("Brigitte"); 16 b.add("Denise"); 17 b.add("Fantine"); 18 b.add("Gilberte"); 19 20 // fletter ordene fra b inn i a 21 ListIterator<String> aIter = a.listIterator(); 22 Iterator<String> bIter = b.iterator(); 23 24 while (bIter.hasNext()) //sĺ lenge som b har flere elementer 25 { 26 if (aIter.hasNext()) //gĺ til neste i a, 27 aIter.next(); //i tilfelle den har flere 28 aIter.add(bIter.next()); //gĺr til neste element i b og 29 //setter det inn foran neste element i a. (Neste kall pĺ 30 //aIter.next() vil vćre upĺvirket av innsettingen.) 31 } 32 33 output += a.toString() + "\n"; 34 35 // fjerner hvert annet ord fra b 36 bIter = b.iterator(); 37 while (bIter.hasNext()) 38 { 39 bIter.next(); // hopper over et element 40 if (bIter.hasNext()) 41 { 42 bIter.next(); // hopper til neste element 43 bIter.remove(); // fjerner elementet (Fjerner fra lista 44 //det siste elementet som ble returnert ved 45 //kall pĺ next-metoden.) 46 } 47 } 48 49 output += b.toString() + "\n"; 50 51 // fjerner alle ordene i b fra a 52 a.removeAll(b); 53 output += a.toString(); 54 JOptionPane.showMessageDialog( null, output ); 55 } 56 }
Vector<E>-klassen versus
ArrayList<E>Klassen
Vector<E>
implementerer en array av objekter. Arrayen
utvider seg selv etter behov. Vector<E>-klassen implementerer
interface List<E>.
Den har derfor samme funksjonalitet som en
ArrayList<E>.
Det er imidlertid en viktig forskjell: Alle metodene
i Vector<E>-klassen er sĺkalt synkroniserte. Det innebćrer
at et Vector-objekt uten risiko kan vćre en fellesressurs for
flere forskjellige programtrĺder. Men dersom Vector-objektet
bare brukes av én programtrĺd — noe som er det langt vanligste
— betyr dette at programmet vil gjřre mye unřdvendig arbeid ved ĺ
synkronisere. Metodene i ArrayList<E>-klassen er i motsetning til
dette ikke synkroniserte. Det blir derfor anbefalt alltid ĺ bruke
ArrayList<E> istedenfor Vector<E> i alle
tilfeller der synkronisering ikke behřves. (Det vil blant annet si alle
tilfeller der du selv ikke programmerer egne programtrĺder.)
for-lřkkeI notatet om arrayer er det forklart hvordan arrayer kan gjennomlřpes ved
bruk av sĺkalt utvidet for-lřkke,
forutsatt at vi bruker javaversjon 1.5 eller nyere. Tilsvarende type lřkke er definert for
alle typer collection. Det er for slike at den kanskje er mest aktuell ĺ bruke.
Generelt kan den for et Collection-objekt
liste skrives slik:
for ( Object o : liste )
...
Dersom vi kjenner datatypen til objektene i samlingen, kan vi selvsagt
bruke den som datatype i lřkka. Dersom vi for eksempel har en
Collection<String> navneliste, kan vi skrive tilsvarende
lřkke slik:
for ( String navn : navneliste )
...
Som for arrayer, har vi imidlertid den begrensning at denne typen lřkke bare kan brukes dersom hele samlingen skal gjennomlřpes.
Som tidligere nevnt, er elementene i en liste tilordnet en indeksposisjon. Dette gjelder
enten lista er implementert i form av en array, eller som en sammenkjedet liste. Derfor
spesifiserer interface List<E> en metode
E get(int index);
for aksess av element pĺ grunnlag av indeksposisjon. Men for en sammenkjedet liste er denne metoden svćrt ineffektiv! Den vil ved hjelp av en iterator foreta et sřk fra starten av lista og telle seg utover til den angitte indeksposisjon.
Pĺ grunn av dette břr du derfor heller aldri skrive kode pĺ fřlgende form for ĺ gjennomlřpe en sammenkjedet liste:
for ( int i = 0; i < liste.size(); i++ ) <gjřr et eller annet med> liste.get(i);
Denne koden er svćrt ineffektiv! Hvert kall pĺ get vil nemlig
starte et nytt sřk fra starten av den sammenkjedete lista og sřke seg utover til den
angitte indeksposisjon. Eneste optimiseringen er at dersom indeksposisjonen er etter midten
av lista, sĺ vil sřket bli foretatt bakfra istedenfor forfra.
Alt i alt břr du for sammenkjedete lister ikke bruke metoder som bruker indekser
for angivelse av posisjon i lista. Dersom du har behov for ĺ gĺ inn i en liste pĺ grunnlag av
indeksposisjon, sĺ bruk heller en array eller en ArrayList, ikke en sammenkjedet liste.
For String-objekter er vi kjent med
metoden compareTo for sammenlikning med
hensyn pĺ leksikografisk (alfabetisk) rekkefřlge. Den virker pĺ den mĺten at
for String-objekter
s1 og s2 sĺ gir
s1.compareTo(s2) et negativt heltall nĺr
s1 er foran s2,
0 nĺr s1 og s2
er like, et positivt heltall nĺr s1 er etter
s2.
Metoden
int compareTo(T o)
er spesifisert, som den
eneste metoden, i
interface Comparable<T>.
String-klassen implementerer
interface Comparable<String> og definerer derfor
compareTo med String-parameter. Metoden virker
imidlertid ikke riktig nĺr det gjelder rekkefřlgen av ord som begynner med
liten eller stor forbokstav. Den virker heller ikke riktig for de norske
bokstavene ć, ř, ĺ og deres store varianter. Vi skal seinere se pĺ hvordan
dette kan hĺndteres.
Nĺr en klasse implementerer Comparable,
og dermed definerer compareTo for vedkommende type objekter,
medfřrer det at alle objekter av denne klassen vil fĺ en total ordning, det
vil si kan ordnes i en bestemt rekkefřlge. Denne kalles klassens
naturlige ordning. Klassens compareTo-
metode kalles dens naturlige sammenlikningsmetode. Det blir for
řvrig sterkt anbefalt at en klasse som implementerer
Comparable ogsĺ implementerer metoden
equals pĺ en slik mĺte at
(x.compareTo(y) == 0) == (x.equals(y)).
En annen klasse som implementerer Comparable,
er Date-klassen for representasjon av
tidspunkter. Den naturlige ordning for denne (bestemt av
compareTo) er det samme som kronologisk
rekkefřlge. (En kort beskrivelse av Date-klassen og hvordan den kan
brukes finner du i notatet
Dato og tid.)
Dersom objektene i en liste er av en klassetype som implementerer
Comparable, kan lista sorteres.
Klassen
Collections
(som er noe annet enn interface Collection!) inneholder en del
static-metoder som opererer pĺ samlinger,
blant annet pĺ lister. I denne finnes ogsĺ en sorteringsmetode.
Nesten alle metodene i Collections har som
fřrste parameter den samlingen de skal operere pĺ. De aller fleste av metodene
opererer pĺ listeobjekter, det vil si samlinger som implementerer
interface List. Metodene
min og max
opererer pĺ vilkĺrlige Collection-objekter.
Sorteringsmetoden til Collections-klassen
heter sort og finnes i to versjoner. Den
enkleste har som eneste parameter den lista den skal sortere. Metoden
sorterer lista i naturlig rekkefřlge, det vil si rekkefřlgen bestemt av
elementenes compareTo-metode. Sorteringsmetoden
har to viktige egenskaper:
Som nevnt ovenfor, finnes Collections-klassens
sort-metode i to versjoner, der den enkleste
sorterer lista (som er den eneste parameteren til metoden) i objektenes
naturlige rekkefřlge, det vil si rekkefřlgen bestemt av deres
compareTo-metode. Men hva om vi řnsker ĺ
sortere objektene i en annen rekkefřlge? Eller hva om vi řnsker ĺ sortere
objekter som ikke implementerer
interface Comparable, det vil si som det ikke
er definert compareTo-metode for?
I begge de nevnte tilfellene kan den andre versjonen av
Collections-klassens
sort-metode brukes. Den har, i tillegg til
den lista som skal sorteres, en parameter av type
Comparator.
Comparator<T>
er et interface som spesifiserer metoden
int compare(T o1, T o2);
Denne skal sammenlikne sine to argumenter for rekkefřlge og returnere et
negativt heltall, 0, eller et positivt heltall avhengig av om det fřrste
argumentet kommer foran, likt med eller etter det andre argumentet i den
ordningen (rekkefřlgen) vi řnsker ĺ definere. (Dersom et av argumentene
ikke har riktig type i forhold til
Comparator-objektet, kaster metoden ut en
ClassCastException.)
Dette betyr at vi fřrst mĺ definere en klasse som implementerer
interface Comparator pĺ en slik mĺte at
den definerte compare-metoden kan brukes pĺ
objektene vĺre. Ved kall pĺ sort-metoden
mĺ vi bruke et objekt av denne klassen som parameter i tillegg til den lista
som skal sorteres. Som eksempel pĺ denne framgangsmĺten skal vi seinere
definere en rekkefřlge for Person-objekter.
Vi legger merke til at det ĺ definere
compare-metoden er nesten det samme som ĺ
definere compareTo-metoden. Forskjellen er
at compare mottar som argumenter begge objektene
som skal sammenliknes. Ogsĺ for compare-metoden
blir det anbefalt at den blir implementert slik at
(compare(x, y) == 0) == (x.equals(y))
Det blir derfor anbefalt at nĺr man implementerer compare-metoden
for en type objekter, sĺ redefinerer man ogsĺ equals-metoden (som
for řvrig arves fra Object) pĺ en slik mĺte at den nevnte betingelsen
er oppfylt.
Det blir videre anbefalt at klasser som implementerer
interface Comparator ogsĺ implementerer
interface Serializable. Grunnen til dette er at de kan bli brukt
ved sortering av datastrukturer som er serialiserte. Dersom serialisering da
skal virke riktig pĺ vedkommende datastruktur, er det nřdvendig at eventuell
komparator som brukes ogsĺ er serialisert.
Det mest interessante for oss er kanskje sortering av strenger.
String-klassens
compareTo-metode som bestemmer den naturlige
rekkefřlgen virker imidlertid pĺ den mĺten at alle ord som begynner med stor
forbokstav vil komme foran ordene som begynner med liten forbokstav. For
eksempel vil "Java" komme foran
"applet". Dessuten virker
compareTo ikke riktig for ć, ř, ĺ og de
store variantene av disse. compareTo
baserer seg pĺ rekkefřlgen til Unicode-kodene for de forskjellige bokstavene.
I denne rekkefřlgen kommer for eksempel bĺde stor og liten ĺ foran ć og ř.
Lřsningen er ĺ bruke et Collator-objekt.
Klassen
Collator
implementerer
interface Comparator<Object>,
det vil si definerer en compare-metode. For ĺ fĺ et
Collator-objekt med en
compare-metode som foretar riktig
String-sammenlikning pĺ den lokaliteten vi
befinner oss (det vil si i Norge for oss), skal vi skrive
Collator kollator = Collator.getInstance();
Det viser seg imidlertid at heller ikke dette objektet definerer en rekkefřlge som er helt i samsvar med det som ser ut til ĺ vćre riktig etter norske forhold. Det har den feil at smĺ bokstaver settes foran tilsvarende store bokstaver i den rekkefřlgen som blir definert. I indekser til norske břker og i rekkefřlgen for oppslagsord i norske leksika vil en finne at stor bokstav er plassert foran tilsvarende liten bokstav, altsĺ omvendt av det som blir definert av det nevnte kollatorobjektet.
Det returnerte Collator-objektet er av
subklassetypen
RuleBasedCollator.
Ved ĺ skrive
( (RuleBasedCollator) Collator.getInstance() ).getRules();
fĺr vi returnert den tekststrengen som definerer rekkefřlgen. For ĺ fĺ
den rekkefřlgen vi řnsker, kan vi definere vĺr egen rekkefřlge i form av en
String og bruke denne som konstruktřrparameter
nĺr vi oppretter et RuleBasedCollator-objekt:
String rekkefřlge = "<A,a<B,b<..."; //mĺ ta med alle aktuelle tegn Collator kollator = null; try { kollator = new RuleBasedCollator( rekkefřlge ); } catch ( ParseException pe ) { ... // gal syntaks i definisjon av rekkefřlge }
Alle tegn som ikke tas med i rekkefřlge-strengen blir oppfattet ĺ komme pĺ slutten av ordningen.
Det er mulig ĺ bestemme i hvilken grad et
Collator-objekt skal skille pĺ likhet ved
sammenlikninger, for eksempel om det skal gjřres forskjell pĺ stor og liten
bokstav. Dette setter vi ved instruksjonen
kollator.setStrength( grad );
der grad kan ha verdiene
Collator.PRIMARY Collator.SECONDARY Collator.TERTIARY Collator.IDENTICAL
Forskjellene er som fřlger:
PRIMARY:SECONDARY:TERTIARY:IDENTICAL:Dersom vi řnsker ĺ sortere List-objektet
liste med en rekkefřlge vi selv har definert,
mĺ vi altsĺ fřrst definere rekkefřlge og opprette et
Collator-objekt
kollator som forklart ovenfor.
Deretter kan vi skrive
Collections.sort( liste, kollator );
Som et eksempel pĺ dette skal vi ta for oss en liste av personer. Vi řnsker lista sortert med hensyn pĺ personenes etter- og fornavn.
Som eksempel pĺ ĺ bruke comparatorer til ĺ definere rekkefřlge
for objekter og fĺ sortert objektene med hensyn pĺ den definerte rekkefřlgen,
skal vi ta for oss fřlgende
problemstilling: Vi skal definere Person-objekter som blant annet skal
inneholde fornavn og etternavn for personene. Vi řnsker ĺ bruke
Collections-klassens sort-metode for
ĺ fĺ sortert en liste av
Person-objekter med hensyn pĺ etternavn og fornavn. Sorteringen skal virke
riktig for store og smĺ bokstaver, og for de norske bokstavene ć, ř, ĺ (og
deres store varianter), slik at vi kan fĺ skrevet ut en personliste
tilsvarende som denne:
Abel, Amalie Abel, Niels Henrik Abel, Ĺgot Brĺten, Řyvind Brĺten, Ĺse Řsterud, Per Řsterud, Řystein Řsterud, Ĺsta Ćrdal, Anne Ĺrset, Liv Ĺrset, Ĺge Ĺrset, Ĺsmumd
For enkelhets skyld skal vi i Person-objektene bare legge inn fornavn
og etternavn. Objektene kan selvsagt i tillegg inneholde hva som helst annet av data.
Poenget her er bare ĺ vise hvordan vi kan fĺ definert rekkefřlge og fĺ
sortert objektene med hensyn pĺ den definerte rekkefřlgen. Person-klassen
definerer vi rett fram som fřlger:
1 public class Person 2 { 3 private String fornavn, etternavn; 4 5 public Person(String f, String n) 6 { 7 fornavn = f; 8 etternavn = n; 9 } 10 11 public String getEtternavn() 12 { 13 return etternavn; 14 } 15 16 public String getFornavn() 17 { 18 return fornavn; 19 } 20 21 public String toString() 22 { 23 return etternavn + ", " + fornavn; 24 } 25 26 public boolean equals(Person p) 27 { 28 return ( p.getEtternavn().equals( etternavn ) && 29 p.getFornavn().equals( fornavn ) ); 30 } 31 }
Neste skritt er ĺ definere et Comparator<Person>-objekt som
definerer rekkefřlge for Person-objektene. Rekkefřlgen skal
vćre bestemt av rekkefřlgen for etternavn og fornavn. Siden denne rekkefřlgen
ogsĺ skal virke riktig for store og smĺ bokstaver, samt for ć, ř og ĺ, mĺ
vi for String-sammenlikning bruke et Collator-objekt
som gir riktig rekkefřlge for disse. Dette objektet oppretter vi inni
Comparator-klassen vĺr, slik at vi kan bruke dets
compare-metode for ĺ avgjřre String-rekkefřlge.
Comparator-klassen vĺr kan dermed defineres pĺ fřlgende mĺte:
1 import java.util.*; 2 import java.text.*; 3 import javax.swing.JOptionPane; 4 import java.io.Serializable; 5 6 //Gir rekkefřlge for Person-objekter, alfabetisk 7 //pĺ etternavn og fornavn. 8 class Personsammenlikner implements Comparator<Person>, Serializable 9 { 10 private String rekkefřlge = "<\0<0<1<2<3<4<5<6<7<8<9" + 11 "<A,a<B,b<C,c<D,d<E,e<F,f<G,g<H,h<I,i<J,j" + 12 "<K,k<L,l<M,m<N,n<O,o<P,p<Q,q<R,r<S,s<T,t" + 13 "<U,u<V,v<W,w<X,x<Y,y<Z,z<Ć,ć<Ř,ř<Ĺ=AA,ĺ=aa;AA,aa"; 14 15 private RuleBasedCollator kollator; 16 17 public Personsammenlikner() 18 { 19 try 20 { 21 kollator = new RuleBasedCollator(rekkefřlge); 22 } 23 catch ( ParseException pe ) 24 { 25 JOptionPane.showMessageDialog( null, 26 "Feil i rekkefřlgestring for kollator!" ); 27 System.exit( 0 ); 28 } 29 30 } 31 32 public int compare(Person p1, Person p2) 33 { 34 String n1 = p1.getEtternavn(); 35 String n2 = p2.getEtternavn(); 36 String f1 = p1.getFornavn(); 37 String f2 = p2.getFornavn(); 38 int d = kollator.compare(n1, n2); 39 if (d != 0) 40 return d; 41 else 42 return kollator.compare(f1, f2); 43 } 44 }
De to klassene ovenfor er definert i filene
Person.java og
Personsammenlikner.java.
Java-fila Personliste.java definerer personliste og sorteringsmetode for denne, slik det er gjengitt nedenfor:
1 import java.util.*; 2 import java.io.*; 3 import javax.swing.JOptionPane; 4 5 public class Personliste 6 { 7 private List<Person> liste = new LinkedList<>(); 8 9 //Setter inn nytt Person-objekt bakerst i lista 10 public void settInn(Person p) 11 { 12 liste.add( p ); 13 } 14 15 //Sorterer Person-objektene alfabetisk pĺ etternavn og fornavn 16 public void sorter() 17 { 18 Collections.sort(liste, new Personsammenlikner()); 19 } 20 21 //Returnerer liste over alle personnavn, 22 //sortert pĺ etternavn og fornavn. 23 public String toString() 24 { 25 sorter(); 26 String personer = ""; 27 Iterator<Person> iterator = liste.iterator(); 28 while (iterator.hasNext()) 29 { 30 personer += iterator.next().toString() + "\n"; 31 } 32 return personer; 33 } 34 35 public void skrivFil(String filnavn) 36 { 37 Collections.shuffle(liste); //stokker i vilkĺrlig rekkefřlge 38 39 try (PrintWriter utfil = new PrintWriter(filnavn)) 40 { 41 Iterator<Person> iterator = liste.iterator(); 42 String navn = null; 43 while (iterator.hasNext()) 44 { 45 navn = iterator.next().toString(); 46 utfil.println(navn); 47 } 48 } 49 catch (IOException ioe) 50 { 51 JOptionPane.showMessageDialog(null, "Filproblem", 52 "Problem med ĺ skrive fil " + filnavn, 53 JOptionPane.WARNING_MESSAGE); 54 } 55 } 56 }
Listeklassens toString-metode gjřr kall pĺ sorteringsmetoden
fřr lista blir gjennomlřpt, slik at navnene blir returnert i sortert
rekkefřlge. Metoden skrivFil, som lagrer navnelista pĺ fil fřr
programavslutning, stokker rekkefřlgen fřr lagring, slik at ved ny programstart
blir det lest inn en usortert navneliste. Lagringen skjer i form av en tekstfil
med samme struktur som er vist ovenfor, altsĺ pĺ hver linje et etternavn og et fornavn,
med komma bak etternavnet.
Fila Persontester.java definerer et enkelt vindu som kan brukes til ĺ teste ut den definerte personlista. Ved oppstart blir det lest inn en liste med navn (i tilfelle en slik eksisterer og blir funnet av programmet). Nĺ er det imidlertid slik at de sćrnorske bokstavene ć, ř, ĺ og deres store varianter har forskjellige koder avhengig av hvilket tegnsett som blir brukt. I Vest-Europa og USA er det for generelle brukerprogrammer vanlig ĺ bruke tegnsettet ISO-8859-1, ogsĺ kalt Western, eller Latin 1. Dette brukes av bl.a. TextPad. Det er ogsĺ dette som er brukt i tekst og eksempler i denne notatserien. Det er et tegnsett som koder i én byte de 256 fřrste unicodetegnene.
Et annet tegnsett som koder Unicode, er UTF-8.
Det bruker et varierende antall byte pĺ de forskjellige tegnene.
Det har den fordelen at det er
bakoverkompatibelt med ASCII-tegnsettet. Det brukes bl.a. som default-tegnsett av
NetBeans. Men det er mulig ĺ stille inn NetBeans til ĺ bruke for eksempel
ISO-8859-1. Det fřrer til minst trřbbel med bruk av filer som inneholder ć, ř og ĺ.
Lista med navn som skal leses inn av dette programmet er laget i begge
de nevnte tegnsettene. Navnelistene finnes i de to filene
navneliste.txt
(som bruker ISO-8859-1) og
navneliste_UTF-8.txt.
For at programmet skal virke riktig, mĺ man velge den fila som samsvarer med det
tegnsettet som blir brukt ved kjřring av programmet. Filnavnet er i programmet
hardkodet som et datafelt i vindusklassen Persontester.
Ved oppstart blir
fřlgende metode blir kalt opp for ĺ lese navnefila:
48 public void lesFil() 49 { 50 try (BufferedReader innfil = new BufferedReader( 51 new FileReader(filnavn))) 52 { 53 String navn = null; 54 do 55 { 56 navn = innfil.readLine(); 57 if (navn != null) 58 { 59 try (Scanner leser = new Scanner(navn)) 60 { 61 leser.useDelimiter("[,\\s]+"); 62 String etternavn = null; 63 if (leser.hasNext()) 64 etternavn = leser.next(); 65 String fornavn = null; 66 if (leser.hasNext()) 67 fornavn = leser.next(); 68 if (etternavn != null && fornavn != null) 69 liste.settInn(new Person(fornavn, etternavn)); 70 } 71 } 72 } while (navn != null); 73 } 74 catch (FileNotFoundException fnf) 75 { 76 JOptionPane.showMessageDialog(this, "Manglende fil", 77 "Finner ikke fil " + filnavn, 78 JOptionPane.WARNING_MESSAGE); 79 } 80 catch (IOException ioe) 81 { 82 JOptionPane.showMessageDialog(this,"Filproblem", 83 "Problem med ĺ lese fra fil " + filnavn, 84 JOptionPane.WARNING_MESSAGE); 85 } 86 }
Driver for programmet er definert i klassen Personapplikasjon.java.
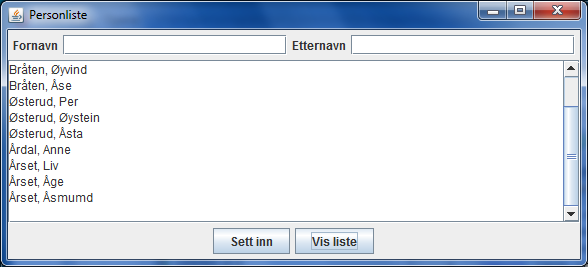
Fřlgende bilde viser programvinduet etter oppstart og etter at innlest navneliste er skrevet ut i sortert rekkefřlge ved at det er klikket pĺ knappen Vis liste.
Klassen Collections inneholder som nevnt en
del static-metoder som
opererer pĺ samlinger, de fleste av dem pĺ lister. Metoden
shuffle gjřr det motsatte av det
sort-metoden gjřr. Objektene i den lista
som brukes som aktuell parameter blir stokket om til en tilfeldig rekkefřlge,
tilsvarende det som skjer nĺr vi stokker kortene i en kortstokk.
Metoden kan vćre aktuell ĺ bruke nĺr man skal skrive programmer der noe skal
skje pĺ slump. Metoden ble brukt i programmet ovenfor for at navnene skulle komme i
en tilfeldig rekkefřlge i den fila som ble skrevet ut ved programslutt.
Hensikten var ĺ fĺ konstatert at sorteringsmetoden virket som den skulle.
Collections-klassen inneholder tre metoder
som utfřrer operasjoner som er av en enkel natur og som det er lett ĺ
programmere selv. Det gjelder:
reverse: Reverserer elementenes
rekkefřlge i en liste.fill: Overskriver alle elementene i en
liste med den spesifiserte verdien. Kan vćre nyttig ved (re)initialisering.copy: Kopierer elementene fra en liste
(kilde) over i en annen liste (mĺl) ved ĺ overskrive innholdet i denne,
som mĺ vćre minst like stor som kilde-lista.To andre metoder som er lette ĺ programmere selv, er metodene
min og max for
ĺ returnere minste eller střrste verdi blant en samling av elementer. De er
tatt med ut fra bekvemmelighetshensyn overfor programmereren. Metodene
min og max er blant
de fĺ metodene i Collections-klassen som kan
brukes med vilkĺrlige Collection-objekter som
parametre. De fleste andre metodene i Collections-klassen
opererer pĺ lister. Bĺde
min og max
finnes i to varianter: Den ene varianten har bare et
Collection-objekt som parameter. Den andre varianten
har i tillegg en parameter av type Comparator.
Det vil ved bruk av denne vćre compare-metoden
i dette Comparator-objektet som blir brukt for ĺ
finne ekstremverdi. En aktuell Comparator
ĺ bruke vil vćre en Collator.
For ĺ undersřke om et objekt finnes i en liste, kan vi bruke
List-metoden
contains(objekt) (som returnerer
true eller
false). List-metoden
indexOf(objekt) returnerer listeindeks for (fřrste forekomst
av) objektet. Begge metodene baserer seg pĺ equals-metoden for
sammenlikning av objekter. Dersom vi ogsĺ řnsker ĺ hente ut fra lista det
objektet vi sřker etter, kan vi etter ĺ ha funnet listeindeksen bruke
listemetoden get(listeindeks). Objektet blir da ikke fjernet
fra lista, vi bare henter det ut for inspeksjon eller endring. Dersom vi řnsker
ĺ fjerne objektet, kan vi bruke listemetoden remove(listeindeks),
som returnerer objektet i tillegg til ĺ fjerne det fra lista, eller
listemetoden remove(objekt) som fjerner fřrste forekomst av
vedkommende objekt (i tilfelle det finnes i lista). Denne metoden returnerer
true eller
false avhengig av om den fant objektet
eller ikke. Metoden set(indeks, element) erstatter elementet i den
spesifiserte indeksposisjon med det elementet som er aktuell parameter til metoden.
Det elementet som tidligere var i denne posisjon blir returnert fra metoden.
Fra tidligere kjenner vi algoritmen for binćr sřking. Den forutsetter at lista det sřkes i er sortert pĺ forhĺnd og at den er indeksert. Algoritmen gĺr ut pĺ at en fřrst ser pĺ elementet midt i lista. Ved sammenlikning av nřkkelverdier blir det avgjort om sřkingen skal fortsette i venstre eller hřyre halvdel. Ogsĺ i dellista bestĺende av denne halvdelen ser en fřrst midt i lista, og fortsetter sĺ videre etter samme framgangsmĺte. Dellista det sřkes i blir dermed halvert for hvert skritt. Selv om lista i utgangspunktet er lang, skal det ikke mange halveringer til fřr den skrumper inn til ett element.
Siden binćr sřking forutsetter aksess pĺ elementer pĺ grunnlag av
indeksering, er den bare implementert for listetypen
ArrayList. (Den forutsetter at listeklassen implementerer
interface RandomAccess.)
Metoden kan kalles opp ogsĺ for en
LinkedList, men det vil da bli foretatt sekvensiell sřking.
Metode for binćrsřking finnes ikke i listeklassene, men i klassen
Collections.
I likhet med andre metoder som har ĺ gjřre med sammenlikning for rekkefřlge,
finnes det ogsĺ to versjoner av Collections-klassens
metode binarySearch. Begge har som parameter den
lista det skal sřkes i og den verdien det skal sřkes etter. En av versjonene
av metoden har som ekstra parameter et
Comparator-objekt som definerer rekkefřlgen
for objektene. Den versjonen av metoden som er uten
Comparator-parameter, forutsetter at lista pĺ
forhĺnd er sortert i stigende rekkefřlge pĺ grunnlag av objektenes naturlige
ordning (det vil si som bestemt av metoden
compareTo). Den andre versjonen av metoden, som
har Comparator-objekt som tilleggsparameter,
forutsetter at lista er sortert i stigende rekkefřlge etter ordningen
definert av dette Comparator-objektet
(det vil si som bestemt av objektets compare-metode).
For ĺ sikre at kravet om sortering er oppfylt, kan en fřr kallet pĺ
binarySearch gjřre kall pĺ den av
sort-metodene som er aktuell ĺ bruke.
Returverdien er den samme for begge versjonene av
binarySearch-metoden. Dersom det sřkte
elementet finnes, blir dets indeks returnert. Dersom det ikke finnes,
er returverdien lik
(-innsettingspunkt - 1)
der innsettingspunkt er definert som det
sted der elementet skulle ha blitt satt inn i lista uten ĺ řdelegge sorteringen, det vil si indeksen til
det fřrste elementet som er střrre enn det sřkte elementet, eller
liste.size() dersom alle elementene i lista
er mindre enn det sřkte elementet. Den nevnte returverdien ble valgt for ĺ sikre
at returverdien bare vil vćre >= 0 nĺr det sřkte elementet blir funnet.
Dessuten vil den vćre til hjelp dersom vi řnsker ĺ sette inn
pĺ sortert plass i lista det
sřkte elementet i tilfelle det ikke finnes. I sĺ fall kan vi skrive slik:
int pos = Collections.binarySearch(liste, element); //eventuelt ogsĺ Comparator-parameter if (pos < 0) liste.add(-pos - 1, element);
Begrepet mengde kjenner vi fra matematikk som en samling av elementer der
hvert element bare kan forekomme én gang. I java blir dette definert av
interface Set<E>
som er et subinterface
til Collection<E>. Set
inneholder ingen nye metoder i tillegg til dem som blir arvet fra
Collection. Men det pĺlegger restriksjoner om at
duplikater er forbudt. Dette fĺr konsekvenser for
add-metoden. Denne legger det nye objektet inn
i samlingen bare dersom det ikke finnes fra fřr. Den returnerer
true eller
false
som signal pĺ om objektet ble lagt inn eller ikke. To
Set-objekter skal regnes som like dersom
de inneholder nřyaktig de samme elementene. Metoden
equals mĺ derfor implementeres slik at dette
er oppfylt. De viktigste operasjonene pĺ Set-objekter
er som fřlger:
size():isEmpty():add(E elem):true eller
false indikerer om det ble satt inn.remove(Object elem):true eller
false indikerer om det fantes.iterator():Iterator<E>-objekt som kan
brukses til gjennomlřping av mengden.Disse operasjonene utfřrer standard algebraiske operasjoner svarende til dem som er definert for matematiske mengder. Fřlgende oversikt viser sammenhengen.
Anta at a og
b er
Set-objekter.
Set-metode |
Tilsvarende matematiske operasjon |
|---|---|
a.containsAll(b) |
Er b delmengde av
a? |
a.addAll(b) |
Union av a og b |
a.removeAll(b) |
a - b (differensmengde) |
a.retainAll(b) |
Snitt av a og
b |
a.clear() |
Setter a lik den tomme mengde. |
De fire fřrste metodene returnerer true
eller false, den siste er
void. Metodene
addAll, removeAll og
retainAll vil erstatte
a med den nevnte union, differensmengde eller
snittmengde. Returverdien indikerer om a ble
endret som fřlge av operasjonen.
Javas klassebibliotek inneholder tre forskjellige implementasjoner av
interface Set<E>. Klassen
HashSet<E>
lagrer elementene i en sĺkalt
hashtabell og gir den mest effektive implementasjonen, men den gir ingen
garantier for rekkefřlgen som elementene er lagret i. (Det vil si at ved
gjennomlřping av mengden kan en ikke vite noe om rekkefřlgen for besřk av
de enkelte elementene. Rekkefřlgen kan dessuten endre seg over tid.) Dersom
effektivitet ved gjennomlřping er av stor betydning, er det grunn til ĺ merke
seg at effektiviteten er avhengig bĺde av
HashSet-objektets kapasitet og oppfyllingsgrad.
I Java blir hashtabeller implementert som arrayer av sammenkjedete lister.
Hver liste blir pĺ engelsk kalt en bucket, altsĺ en "břtte".
For ĺ finne plassen til et element i hashtabellen, blir det pĺ grunnlag av objektet beregnet en sĺkalt
hashkode som sĺ blir redusert modulo antall plasser i arrayen. Denne verdien
bestemmer indeksen for hvilken "břtte" objektet skal puttes i.
Dersom vi ikke velger noen konkret verdi for startkapasitet for arrayen, vil den fĺ en
default-verdi pĺ 16. (Antallet settes alltid lik en potens av 2.) Dersom du
vet omtrent hvor mange elementer som vil bli satt inn i hashtabellen,
kan du sette startkapasitet for antall "břtter". Det anbefales ĺ sette den
mellom 75 % og 150 % av det forventede antall elementer.
Tidligere ble det anbefalt ĺ velge startkapasiteten lik et primtall.
Denne anbefalingen blir ikke lenger gitt. Uansett hvilken verdi vi selv velger,
vil den automatisk bli avrundet oppover til nćrmeste potens av 2.
For ĺ sette en startkapasitet pĺ
k (heltallsverdi), kan vi skrive
Set<Type> s = new HashSet<>( k );
Ved opprettelse av et HashSet vil det i
tillegg til kapasiteten bli bestemt en verdi for det vi kan kalle
lastefaktoren (engelsk: load factor). Default-verdien for denne er 0.75 og
det er sjelden grunn til ĺ endre den. Dersom forholdet mellom antall elementer
i mengden og dens kapasitet overstiger lastefaktoren, vil mengden automatisk
bli sĺkalt rehashet, det vil si at kapasiteten vil bli omtrent doblet.
Klassen
TreeSet<E>
implementerer Set-interface'et i form av et sĺkalt
rřd-svart-tre. Implementasjonen har den tilleggsegenskapen at elementene alltid er sortert.
Men til gjengjeld har den vesentlig dĺrligere effektivitet. Dette har imidlertid
liten betydning nĺr antall elementer er forholdsvis beskjedent.
Vi skal se nćrmere pĺ hvordan denne implementasjonen kan
brukes etter ĺ ha sett pĺ et par eksempler pĺ bruk av
HashSet-klassen.
Den tredje klassen som implenterer Set-interface'et,
LinkedHashSet<E>,
lagrer elementene i en hashtabell, pĺ samme mĺte som er tilfelle med
HashSet. Men i tillegg inneholder den en toveis sammenkjedet liste
som gĺr gjennom elementene i den rekkefřlge som de ble satt inn. Det er denne
som brukes ved gjennomlřping. Ved gjennomlřping av mengden vil vi derfor fĺ dem
i samme rekkefřlge som de ble satt inn. Denne rekkefřlgen vil heller ikke endre
seg dersom vi gjřr forsřk pĺ ĺ sette inn pĺ nytt et element som allerede
finnes i mengden. Den opprinnelige rekkefřlgen vil bli beholdt.
Effektiviteten til implementasjonen er bare litt dĺrligere
enn tilfelle er for HashSet, unntatt nĺr det gjelder gjennomlřping,
der den faktisk har bedre effektivitet, siden effektiviteten bare er avhengig av
hvor mange elementer som er satt inn. Den er ikke avhengig av oppfyllingsgraden,
slik det er tilfelle med HashSet.
Denne implementasjonen kan ogsĺ brukes
til ĺ produsere en kopi av en gitt mengde, der kopien gir samme rekkefřlge ved
gjennomlřping som ville vćre tilfelle ved originalen, uavhengig av hvilken
implementasjon originalen har:
void gjřrEtEllerAnnet(Set m) { Set<Type> kopi = new LinkedHashSet<>(m); ... }
Dette er spesielt nyttig dersom en modul mottar en mengde som input, kopierer den, og seinere returnerer resultater med en rekkefřlge som skal vćre bestemt av den rekkefřlgen som input-mengden har.
Enten det dreier seg om mengder eller andre strukturer, er det en god
regel ĺ tenke i retning av interface, som
beskriver den struktur det er snakk om, heller enn ĺ tenke pĺ en konkret
implementasjon. Valg av implementasjon har stort sett bare konsekvenser for
effektiviteten. Den foretrukne mĺten ĺ programmere pĺ er ĺ velge en
implementasjon nĺr en samling (eller en annen type objekt)
blir opprettet og tilordne denne til en
variabel av den tilsvarende interface-type.
Pĺ denne mĺten blir ikke programmet avhengig av noen eventuelle
tilleggsmetoder i en gitt implementasjon. Programmereren, eller eventuelt
den som skal vedlikeholde programmet, stĺr fritt i enkelt ĺ bytte ut
implementasjon, dersom dette ut fra effektivitetshensyn břr gjřres. Eneste
endringen som behřves vil vćre ĺ bytte konstruktřr.
Skriv
Set<Type> s = new HashSet<>();
istedenfor
HashSet<Type> s = new HashSet<>();
Programmet
SetTest
som er gjengitt nedenfor leser tekstfila
alice30.txt
ord for ord ved hjelp av en
Scanner.
(Se notatet Splitte opp tekst i enkeltkomponenter
angĺende bruk av Scanner.)
Enkeltordene blir lagt inn i en
mengde av type HashSet<String>.
Siden ordene blir lagt inn
i en mengde, vil det for hvert nytt ord bli testet om det finnes fra fřr av.
Mengden vil bare komme til ĺ inneholde forskjellige ord.
Det blir dessuten mĺlt hvor lang tid som brukes totalt pĺ ĺ legge inn
ordene i mengden, inkludert sjekke om de finnes fra fřr.
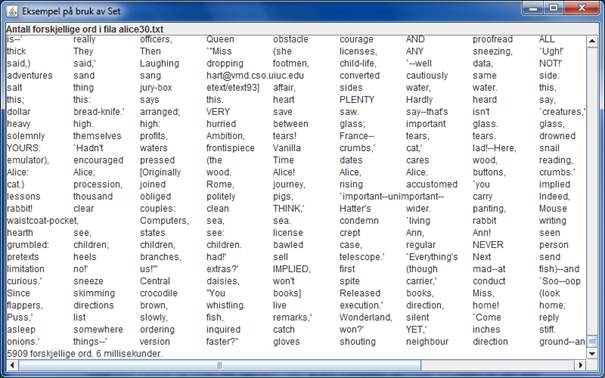
Nĺr alle ordene er lest og lagt inn i mengden, blir den gjennomlřpt ved hjelp av en iterator og ordene blir skrevet ut i et tekstomrĺde, 10 ord per linje. Dessuten blir totalt antall ord skrevet ut og total tid som ble brukt pĺ ĺ legge dem inn.
1 import javax.swing.*; 2 import java.awt.*; 3 import java.util.*; 4 import java.io.*; 5 6 public class SetTest extends JFrame 7 { 8 private JTextArea output; 9 10 public SetTest() 11 { 12 super( "Eksempel pĺ bruk av Set" ); 13 output = new JTextArea( 20, 50 ); 14 output.setEditable( false ); 15 Container c = getContentPane(); 16 JLabel overskrift = new JLabel( 17 "Antall forskjellige ord i fila alice30.txt" ); 18 c.add( overskrift, "North" ); 19 c.add( new JScrollPane( output ), "Center" ); 20 setSize( 800, 500 ); 21 setVisible( true ); 22 } 23 24 public void tellOppOrd() 25 { 26 Set<String> ord = new HashSet<>(59999);//bruk HashSet eller TreeSet 27 long totaltid = 0; 28 29 try (BufferedReader in = new BufferedReader( 30 new FileReader("src/alice30.txt")); 31 Scanner ordleser = new Scanner(in)) 32 { 33 while (ordleser.hasNext()) 34 { 35 String nesteord = ordleser.next(); 36 long kalltid = System.currentTimeMillis(); 37 ord.add( nesteord ); 38 kalltid = System.currentTimeMillis() - kalltid; 39 totaltid += kalltid; 40 } 41 } 42 catch (IOException e) 43 { 44 System.out.println("Feil " + e); 45 } 46 47 Iterator<String> iter = ord.iterator(); 48 int ant = 0; 49 while (iter.hasNext()) 50 { 51 output.append( iter.next() + "\t" ); 52 if ( ++ant % 10 == 0 ) 53 output.append( "\n" ); 54 } 55 output.append( "\n" + ord.size() 56 + " forskjellige ord. " + totaltid + " millisekunder." ); 57 } 58 59 public static void main(String[] args) 60 { 61 SetTest vindu = new SetTest(); 62 vindu.setDefaultCloseOperation( JFrame.EXIT_ON_CLOSE ); 63 vindu.tellOppOrd(); 64 } 65 }
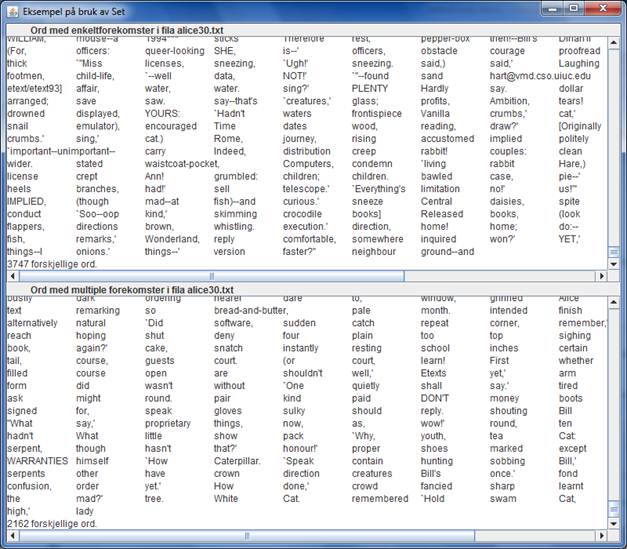
Fřlgende bilde viser et utsnitt av det tekstomrĺdet som blir vist i programvinduet ved kjřring av programmet. (Du mĺ sřrge for ĺ legge inn fila som programmet skal lese pĺ riktig sted i forhold til den filadressen som programmet bruker for ĺ ĺpne fila.)
Programmet
SetTest2 er en modifikasjon av
det foregĺende. I dette blir det brukt to mengder. Den ene skal inneholde alle ord
som det finnes bare én forekomst av i fila, mens den andre skal inneholde
alle ord som det er multiple forekomster av. En fĺr lagt inn riktige data
i mengdene pĺ den mĺten at hvert nytt leste ord forsřkes lagt inn i den fřrste
mengden. Dersom dette ikke lykkes, betyr det at det finnes fra fřr.
add-metoden vil da returnere
false og ordet blir lagt inn i den andre
mengden, selvsagt forutsatt at det ikke allerede finnes ogsĺ i denne.
Nĺr alt er lest, vil den fřrste mengden inneholde alle forskjellige ord fra
fila og den andre mengden vil inneholde alle ord som forekommer mer enn
én gang. Disse blir sĺ fjernet fra den fřrste mengden ved bruk av
removeAll-metoden til den fřrste mengden,
med den andre mengden som aktuell parameter.
Vi kan for řvrig legge merke til at det totalt er 3747 ord med bare én forekomst, 2162 ord med mer enn én forekomst. Summen av disse blir 5909 som er antall forskjellige ord som ble registrert av det fřrste programmet.
Metoden tellOppOrd som foretar innlesing fra fil og innsetting
av ordene i de to mengdene er gjengitt nedenfor.
31 public void tellOppOrd() 32 { 33 Set<String> singelforekomst = new HashSet<>(59999); 34 // bruk HashSet eller TreeSet 35 Set<String> duplikater = new HashSet<>(); 36 37 try (BufferedReader in = new BufferedReader( 38 new FileReader("src/alice30.txt")); 39 Scanner ordleser = new Scanner(in)) 40 { 41 while (ordleser.hasNext()) 42 { 43 String ord = ordleser.next(); 44 if ( !singelforekomst.add(ord) ) 45 duplikater.add(ord); 46 } 47 } 48 catch (IOException e) 49 { 50 System.out.println("Feil " + e); 51 } 52 53 //Fjerner fra mengden singelforekomst de ord som det 54 //er registrert flere forekomster av: 55 singelforekomst.removeAll(duplikater); 56 Iterator<String> singelIter = singelforekomst.iterator(); 57 int ant = 0; 58 while (singelIter.hasNext()) 59 { 60 singeloutput.append(singelIter.next() + "\t"); 61 if ( ++ant % 10 == 0 ) 62 singeloutput.append("\n"); 63 } 64 singeloutput.append("\n" + singelforekomst.size() + 65 " forskjellige ord. " ); 66 67 ant = 0; 68 Iterator<String> duploIterator = duplikater.iterator(); 69 while (duploIterator.hasNext()) 70 { 71 duplikatoutput.append(duploIterator.next() + "\t"); 72 if ( ++ant % 10 == 0 ) 73 duplikatoutput.append("\n"); 74 } 75 duplikatoutput.append("\n" + duplikater.size() + 76 " forskjellige ord. "); 77 }
Fřlgende bilde viser utsnitt av de to tekstomrĺdene som blir vist i programvinduet ved kjřring av programmet.
Klassen TreeSet implementerer, slik som
HashSet, mengdebegrepet. Men
TreeSet har den forbedringen at mengden alltid
er sortert. TreeSet implementerer
interface SortedSet<E>
som er subinterface til
Set<E>. De generelle mengdeoperasjonene som blir arvet
fra Set oppfřrer seg pĺ sorterte mengder som
pĺ usorterte mengder med unntak av fřlgende:
Iterator-objektet returnert av
iterator() foretar gjennomlřping av mengden
i sortert rekkefřlge (uavhengig av innsettingsrekkefřlge og uten
forutgĺende sortering).toArray()
inneholder mengdens elementer i sortert rekkefřlge.Nĺr det gjelder toString-metoden, blir det
av interface SortedSet ikke lagt noe krav pĺ
denne. Men TreeSet-klassens
toString-metode returnerer elementene i
sortert rekkefřlge.
SortedSet spesifiserer tre forskjellige
metoder pĺ delintervall. Det er metodene
subSet, headSet og
tailSet.
subSet mottar som parametre objekter
(ikke indekser!) for de to endepunktene. Disse mĺ kunne sammenliknes for
rekkefřlge med objektene som er i mengden.
subSet returnerer det vi kan tenke pĺ som et halvĺpent intervall, det
vil si en mengde (av type SortedSet) som
inkluderer objektet for nedre endepunkt, i tilfelle dette finnes i mengden,
men ikke objektet for řvre endepunkt.
TreeSet forutsetter som default at elementene
som blir satt inn i mengden er av en type som implementerer
interface Comparable, det vil si som det er
definert compareTo-metode for. Det er da denne
som vil bli brukt til ĺ avgjřre rekkefřlge. Vi mĺ derfor sřrge for at
klassene som definerer objektene vĺre implementerer
interface Comparable slik at den definerte
compareTo-metode gir den rekkefřlge vi řnsker
for objektene vĺre. Forsřk pĺ ĺ legge inn i mengden objekter som det ikke
er definert compareTo-metode for, vil
resultere i en ClassCastException.
Nĺr det gjelder String-objekter,
vet vi at compareTo-metoden ikke virker
riktig for rekkefřlgen av ć, ř, ĺ og heller ikke riktig for rekkefřlgen av
ord som begynner med stor eller liten forbokstav. For ĺ břte pĺ dette, kan vi,
som forklart i forbindelse med sortering av lister, bruke et
Comparator-objekt av type
Collator som konstruktřrparameter ved opprettelsen av
TreeSet-objektet. Det vil da vćre
compare-metoden til dette
Comparator-objektet som vil bli brukt til ĺ
avgjřre rekkefřlge i den sorterte mengden. Framgangsmĺten blir dermed som
fřlger:
Opprette Collator-objekt, enten ved instruksjonen
Comparator komp = Collator.getInstance();
eller definere vĺr egen rekkefřlge for komparatoren:
String rekkefřlge = "<\0<0<1< ..."; //mĺ her ta med alle bokstaver og tegn som //vi řnsker ĺ definere rekkefřlge for.
Oppretter komparator:
Comparator komp = new RuleBasedCollator(rekkefřlge);
Oppretter mengdeobjektet:
SortedSet<String> ordbok = new TreeSet<>(komp);
Pĺ tilsvarende mĺte kan vi gĺ fram dersom vi řnsker ĺ legge
objekter som ikke implementerer
interface Comparable inn i en
sortert mengde. (Vi mĺ da sřrge for at
compare-metoden til vedkommende
Comparator-objekt er definert pĺ en
meningsfull mĺte for objektene vĺre.)
Anta at SortedSet<String>-objektet
ordbok er opprettet som skissert ovenfor og at
det er lagt inn tekststrenger i dette.
Antall ord mellom "fřrst" og
"sist", inkludert
"fřrst", men ekskludert
"sist":
int antall = ordbok.subSet("fřrst", "sist").size();
Dersom de to argumentene i subSet har gal
rekkefřlge, blir det kastet ut en
IllegalArgumentException.
Fjerne alle ord som begynner pĺ "q" fra
samme mengde ordbok:
ordbok.subSet("q", "r").clear();
subSet-metoden erstatter ikke mengden den
brukes pĺ med vedkommende delmengde. Men dersom det blir gjort endringer pĺ den
delmengden som blir hentet ut, for eksempel ved ĺ bruke
clear(), sĺ vil de samme endringene
gjenspeile seg i den mengden som ligger under, det vil si som delmengden er
hentet ut fra.
Dersom řvre grense er String-objektet
s, trenger vi da ĺ vite hvilket
String-objekt som fřlger etter
s i den naturlige ordningen. Det er
s + "\0", det vil si s
tilfřyd et nulltegn. Antall ord mellom "fřrst"
og "sist" i mengden
ordbok, begge grenser inkludert, fĺr vi derfor
slik:
int antall = ordbok.subSet("fřrst", "sist" + "\0").size();
Tilsvarende for ĺ fĺ ĺpent intervall, det vil si intervall som ekskluderer begge endepunktene:
int antall = ordbok.subSet("fřrst" + "\0", "sist").size();
Metodene headSet og
tailSet tar begge en parameter av den typen
som mengden er definert til ĺ inneholde. Metoden headSet
returnerer delmengden fra starten og opp til, men ikke til og med det
spesifiserte objektet. Metoden tailSet returnerer
delmengden fra og med spesifisert objektet (dersom det finnes) og resten av
det SortedSet-objekt som metoden kalles for.
Ved bruk av disse to metodene kan vi derfor fĺ en to-deling av en gitt mengde.
Vi antar at SortedSet<String>-objektet
ordbok er opprettet og fylt med innhold som
tidligere skissert. Vi skal splitte ordbok i
delene: ord som begynner pĺ A til M,
og ord som begynner pĺ N til Ĺ:
SortedSet<String> fřrstedel = ordbok.headSet("N"); SortedSet<String> andredel = ordbok.tailSet("N");
SortedSet-metodene
first og last
returnerer, som navnene indikerer, henholdsvis fřrste og siste element i
mengden. Disse operasjonene muliggjřr dessuten ĺ utfřre en operasjon som ikke
er tatt med i SortedSet:
Gjennomlřping forover fra startelementet er lett ĺ fĺ til
(vi forutsetter som fřr at SortedSet<String>-objektet
ordbok er opprettet og fylt med data):
SortedSet<String> hale = ordbok.tailSet(startelement);
Iterator<String> iter = hale.iterator();
while (iter.hasNext())
{
String ord = iter.next();
.
.
}
Gjennomlřping i retning bakover fra startelementet er ikke sĺ lett ĺ fĺ til. Men vi kan fĺ tak i det foregĺende elementet ved ĺ skrive fřlgende:
String forlřper = ordbok.headSet(startelement).last();
Pĺ denne mĺten fĺr vi gĺtt ett skritt bakover fra et gitt utgangspunkt.
Operasjonen kan repeteres gjentatte ganger (med
forlřper som nytt startelement) for ĺ fĺ til
en gjennomlřping, men det vil vćre svćrt ineffektivt.
Vi skal ta for oss et program som kan lese inn en tekstfil og lagre de forskjellige ordene i en sortert mengde. Brukeren kan velge hvilken fil som skal behandles og dette kan foretas gjentatte ganger. Nĺr fil er lest inn og ordene lagret i programmets datastruktur, kan brukeren velge mellom to operasjoner:
Programmet bruker en kollator, slik at det ogsĺ virker riktig for ć, ř og ĺ. Programmet bestĺr av filene Ordopptelling.java, Bokstavinput.java og Inputdialog.java og Ordtester.java. Nedenfor gjengis de metodene som har med bruken av mengdene ĺ gjřre.
8 //Denne versjonen behandler sortering av ord med ć, ř og ĺ riktig. 9 public class Ordopptelling extends JFrame 10 { 11 private JButton velgFil, intervall, forbokstav; 12 private JTextArea utskrift; 13 private JTextField filvalg; 14 private SortedSet<String> ordbok; 15 private JDialog ordleser, bokstavleser; 16 private Knappelytter lytter; 17 private RuleBasedCollator kollator; 18 private String rekkefřlge; 19 private SortedSet<String> ćřĺ; 20 21 public Ordopptelling() 22 { . . 51 //Definerer sorteringsrekkefřlge: 52 rekkefřlge = "<\0<0<1<2<3<4<5<6<7<8<9" + 53 "<A,a<B,b<C,c<D,d<E,e<F,f<G,g<H,h<I,i<J,j" + 54 "<K,k<L,l<M,m<N,n<O,o<P,p<Q,q<R,r<S,s<T,t" + 55 "<U,u<V,v<W,w<X,x<Y,y<Z,z<Ć,ć<Ř,ř<Ĺ;AA,Aa,ĺ;aa"; 56 try 57 { 58 kollator = new RuleBasedCollator( rekkefřlge ); 59 //for riktig sortering av norske ord 60 } 61 catch ( ParseException pe ) { 62 JOptionPane.showMessageDialog( 63 null, "Feil i rekkefřlgestring for kollator!" ); 64 System.exit( 0 ); 65 } 66 lagĆřĺ(); . . 83 } 84 85 //Lagrer bokstavene ć, ř og ĺ i en mengde til internt bruk. 86 private void lagĆřĺ() 87 { 88 ćřĺ = new TreeSet<>( kollator ); 89 ćřĺ.add( "Ć" ); 90 ćřĺ.add( "ć" ); 91 ćřĺ.add( "Ř" ); 92 ćřĺ.add( "ř" ); 93 ćřĺ.add( "ĺ" ); 94 ćřĺ.add( "Ĺ" ); 95 } 96 97 //Lar brukeren velge fil vha. et JFileChooser-dialogvindu. 98 public File hentFil() 99 { . . 113 } 114 115 //Leser valgt fil og lagrer de forskjellige ordene 116 //i en sortert mengde. 117 public SortedSet<String> lagOrdbok( File fil ) 118 { 119 SortedSet<String> s = new TreeSet<>( kollator ); 120 if ( fil != null ) 121 { 122 try (Scanner leser = new Scanner( fil, "ISO-8859-1" )) 123 { 124 while ( leser.hasNext() ) 125 { 126 String ord = leser.next(); 127 s.add( ord ); 128 } 129 return s; 130 } 131 catch ( IOException ioe ) 132 { 133 JOptionPane.showMessageDialog( this, 134 "Fĺr ikke lest " + fil ); 135 return null; 136 } 137 } 138 else 139 { 140 JOptionPane.showMessageDialog( this, "Ingen fil valgt." ); 141 return null; 142 } 143 } 144 145 //Skriver ut og teller ordene mellom valgte grenser, 146 //grenseord inkludert. 147 public void visOrd( String nedre, String řvre ) 148 { 149 if ( ordbok != null ) 150 { 151 SortedSet<String> forekomster = null; 152 try 153 { 154 forekomster = ordbok.subSet( nedre, řvre + "\0" ); 155 } 156 catch ( IllegalArgumentException ie ) 157 { 158 JOptionPane.showMessageDialog( this, 159 "Gal rekkefřlge pĺ nedre og řvre grense!" ); 160 return; 161 } 162 int antall = forekomster.size(); 163 Iterator<String> iterator = forekomster.iterator(); 164 utskrift.setText( antall + " ord:\n" ); 165 while ( iterator.hasNext() ) 166 utskrift.append( iterator.next() + "\n" ); 167 } 168 else 169 utskrift.setText( "Ingen fil lest inn." ); 170 } 171 172 //Skriver ut og teller alle ord med valgt forbokstav. 173 public void visOrd( char forbokstav ) 174 { 175 if ( ordbok != null ) 176 { 177 char neste = nesteBokstav( forbokstav ); 178 char[] nedre = { forbokstav }; 179 String fřrste = (new String( nedre )).toUpperCase(); 180 String siste = null; 181 if ( neste != '@' ) 182 { 183 char[] řvre = { neste }; 184 siste = (new String( řvre )).toUpperCase(); 185 } 186 else 187 siste = "ĺĺĺ"; //kommer etter alle tenkelige ord 188 SortedSet<String> forekomster = null; 189 try 190 { 191 forekomster = ordbok.subSet( fřrste, siste ); 192 } 193 catch ( IllegalArgumentException ie ) 194 { 195 JOptionPane.showMessageDialog( this, 196 "Klarer ikke behandle denne bokstaven!" ); 197 return; 198 } 199 int antall = forekomster.size(); 200 Iterator<String> iterator = forekomster.iterator(); 201 utskrift.setText( antall + " ord:\n" ); 202 while ( iterator.hasNext() ) 203 utskrift.append( iterator.next() + "\n" ); 204 } 205 else 206 utskrift.setText( "Ingen fil lest inn." ); 207 } 208 209 //Hjelpemetode som returnerer etterfřlgeren til 210 //den valgte bokstaven, '@' etter ĺ. 211 public char nesteBokstav( char bokstav ) 212 { 213 char[] b = { bokstav }; 214 String s = new String( b ); 215 if ( !ćřĺ.contains( s ) && bokstav < 'z' ) 216 return (char) (bokstav + 1); 217 else 218 { 219 switch ( bokstav ) 220 { 221 case 'z': 222 case 'Z': return 'Ć'; 223 case 'Ć': 224 case 'ć': return 'Ř'; 225 case 'Ř': 226 case 'ř': return 'Ĺ'; 227 default: return '@'; //signaliserer at bokstav var ĺ eller Ĺ 228 } 229 } 230 } 231 . . 258 }
Interface
Map<K,V>
definerer det som svarer til
det vi i matematikk kjenner som en avbildning:
en tilordning som til hver nřkkelverdi (argument) tilordner nřyaktig én verdi ("funksjonsverdi").
Duplikater av
nřkkelverdier er ikke tillatt. Til hver nřkkelverdi kan det bare tilordnes
én verdi. Men pĺ den andre side kan én og samme verdi ("funksjonsverdi")
ha blitt tilordnet som verdi av mange forskjellige nřkkelverdier.
(Vi har altsĺ en mange-til-én-relasjon.)
Datatypene for nřkkelverdiene og de tilordnede verdiene kan angis som typeparametre
K og V.
Alt i alt kan vi altsĺ se pĺ en avbildning (Map)
som en samling av (nřkkel, verdi)-par. Men merk at en
Map ikke er en
Collection. Vi kan derimot pĺ tre forskjellige
mĺter hente ut en Collection fra en
Map. Fřlgende
Map-metoder returnerer en
Collection:
Set<Map.Entry<K,V>> entrySet():Collection<V> values():Set<K> keySet():Metoden
put(K nřkkel, V verdi)
tilfřyer det spesifiserte (nřkkel, verdi)-paret til avbildningen.
Dersom det i samlingen allerde finnes et (nřkkel, verdi)-par med samme
nřkkelverdi, sĺ vil den verdien som vedkommende nřkkelverdi er tilordnet bli oppdatert med den
nye verdien, og den gamle verdien vil bli returnert. (Returverdi
null
dersom nřkkelverdien ikke finnes fra fřr av.)
Metoden
get(Object nřkkel)
returner verdien
som er tilordnet den spesifiserte nřkkel. Returverdien er av type
V, lik null
dersom nřkkelen ikke finnes.
Pakken java.util inneholder tre klasser som
implementerer interface Map:
HashMap<K,V>,
TreeMap<K,V>, og
LinkedHashMap<K,V>.
Disse har funksjonalitet og effektivitet som svarer nřyaktig til de analoge klassene
HashSet, TreeSet, og LinkedHashSet
som ble beskrevet i avsnittet om mengder.
HashMap versus HashtableKlassen
Hashtable<K,V>
forholder seg til klassen HashMap pĺ tilsvarende mĺte som klassen
Vector forholder seg til klassen ArrayList, se
kommentar foran om forholdet mellom disse.
Klassene Hashtable og Vector var begge med i den
opprinnelige java-versjonen. Da Collections-rammeverket ble introdusert i
javaversjon 1.2, ble bĺde Hashtable og Vector
tilpasset dette rammeverket: Vector ved at den implementerer
interface List; Hashtable ved at den implementerer
interface Map. Fra javaversjon 1.5 er klassene i tillegg tilpasset
bruken av generiske datatyper.
Tilsvarende som for Vector, sĺ er
alle metodene i Hashtable synkroniserte, med alt det innebćrer av
ekstra utfřrelse av kode som er unřdvendig i de fleste tilfeller. Pĺ grunn av
dette anbefales det ĺ bruke et HashMap-objekt
istedenfor et Hashtable-objekt i alle tilfeller der
objektet ikke skal vćre fellesressurs for flere programtrĺder.
Eneste mĺten ĺ fĺ gjennomlřpt en avbildning pĺ, er ĺ hente ut en av de tre mulige samlingene som er nevnt foran og gjennomlřpe denne ved hjelp av en iterator.
Gjennomlřping av nřkkelverdier:
Map<Nřkkeltype,Verditype> m = ...;
Set<Nřkkeltype> nřkler = m.keySet();
Iterator<Nřkkeltype> iter = nřkler.iterator();
while (iter.hasNext())
{
Nřkkeltype nřkkel = iter.next();
.
.
}
Gjennomlřping av (nřkkel, verdi)-par:
Gjennomlřping av (nřkkel, verdi)-parene til en avbildning er litt spesielt.
Disse er av type Map.Entry<K,V> som er definert som
et indre static interface i
interface Map<K,V>.
Klasser som implementerer
interface Map vil ha
Map.Entry som en static
indre klasse. (At en indre klasse er static
betyr bare at et objekt av den typen den definerer ikke har noen referanse til objektet av den
ytre klassen som den
tilhřrer, slik at det ikke er noen tilgang til datafeltene og metodene i denne.)
Klassen Map.Entry har
metoder getKey og
getValue som returnerer henholdsvis nřkkel
og verdi for (nřkkel, verdi)-paret. En gjennomlřping av (nřkkel, verdi)-parene
kan vi derfor skrive slik:
Map<Nřkkeltype,Verditype> m = ...;
Set<Map.Entry<Nřkkeltype,Verditype>> verdipar = m.entrySet();
Iterator<Map.Entry<Nřkkeltype,Verditype>> iter = verdipar.iterator();
while (iter.hasNext())
{
Map.Entry<Nřkkeltype,Verditype> par = iter.next();
Nřkkeltype nřkkel = par.getKey();
Verditype verdi = par.getValue();
.
.
}
SortedMap
SortedMap<K,V>
er Map-analogien til
SortedSet. Som dette, har det operasjoner for
ĺ behandle delomrĺder av hele samlingen. De aktuelle metodene er
public SortedMap<K,V> subMap(K fraNřkkel, K tilNřkkel)SortedSet blir det returnert
et "halvĺpent" intervall.public SortedMap<K,V> headMap(K tilNřkkel)tilNřkkel
(som ikke er inkludert).public SortedMap<K,V> tailMap(K fraNřkkel)fraNřkkel.Som i tilfelle SortedSet, kan vi ved bruk
av headMap og tailMap
fĺ til en todeling av en gitt avbildning.
Programmet HashMapDemo ĺpner en tekstfil
etter brukers valg. Fila leses ord for ord. Programmet skal registrere
frekvensene for forekomstene av de forskjellige ordene. Det gjřres ved ĺ legge
(ord, frekvens)-par inn i en avbildning av type HashMap<String, Integer>.
For hvert lest ord hentes frekvensen for dette ordet ut av avbildningen. Dersom
ordet ikke finnes, legges det inn med frekvens 1. Nĺr det finnes, řkes frekvensen
med 1. I avbildningen blir frekvensene lagret som
Integer-objekter, men pĺ grunn av
mekanismen med autoboksing, se foran, kan vi legge
dem inn og oppdatere dem som om det var
int-verdier.
Nĺr alt er
lest og registrert, blir resultatet skrevet ut i et tekstomrĺde. Det skjer ved
at mengden av (ord, frekvens)-par blir hentet ut av avbildningen og gjennomlřpt ved
hjelp av en iterator. For hvert par, av type Map.Entry<String, Integer>,
blir ord (nřkkel) og frekvens (verdi) hentet ut hver for seg.
Programmet bestĺr av vindusklassen
HashMapDemo og driverklassen
HashMapTest.
Nedenfor er vindusklassen gjengitt.
1 import javax.swing.*; 2 import java.awt.*; 3 import java.awt.event.*; 4 import java.util.*; 5 import java.io.*; 6 7 //Teller opp frekvenser for de forskjellige ord i valgt fil. 8 public class HashMapDemo extends JFrame 9 { 10 private JButton velgFil; 11 private JTextArea utskrift; 12 private JTextField filvalg; 13 private Knappelytter lytter; 14 15 public HashMapDemo() 16 { 17 super( "Opptelling av frekvenser ord" ); 18 velgFil = new JButton( "Velg fil" ); 19 utskrift = new JTextArea( 30, 30 ); 20 utskrift.setEditable( false ); 21 filvalg = new JTextField( 40 ); 22 filvalg.setEditable( false ); 23 JPanel knappepanel = new JPanel(); 24 knappepanel.add( velgFil ); 25 JPanel filpanel = new JPanel(); 26 filpanel.add( new JLabel( "Valgt fil" ) ); 27 filpanel.add( filvalg ); 28 JPanel senterpanel = new JPanel(); 29 senterpanel.setLayout( 30 new BoxLayout(senterpanel, BoxLayout.PAGE_AXIS)); 31 senterpanel.add( filpanel ); 32 senterpanel.add( new JScrollPane( utskrift ) ); 33 Container c = getContentPane(); 34 c.add( knappepanel, BorderLayout.NORTH ); 35 c.add( senterpanel, BorderLayout.CENTER ); 36 lytter = new Knappelytter(); 37 velgFil.addActionListener( lytter ); 38 pack(); 39 setVisible( true ); 40 } 41 42 //Lar brukeren velg fil vha. et JFileChooser-dialogvindu. 43 public File hentFil() 44 { 45 JFileChooser filvelger = new JFileChooser(); 46 filvelger.setCurrentDirectory( new File( "." ) ); 47 int resultat = filvelger.showOpenDialog( this ); 48 if ( resultat == JFileChooser.APPROVE_OPTION ) 49 { 50 File f = filvelger.getSelectedFile(); 51 String fil = f.getPath(); 52 filvalg.setText( fil ); 53 return f; 54 } 55 else 56 return null; 57 } 58 59 //Leser valgt fil og registrerer frekvenser. 60 public Map<String, Integer> frekvenser(File fil) 61 { 62 Map<String, Integer> forekomster = null; 63 if ( fil != null ) 64 { 65 forekomster = new HashMap<>(); 66 try (Scanner ordleser = new Scanner(fil)) 67 { 68 ordleser.useDelimiter("[.,!;:*?`$\"\'/<>=\\(){}\\s]+"); 69 while (ordleser.hasNext()) 70 { 71 String ord = ordleser.next(); 72 Integer frekvens = forekomster.get(ord); 73 if (frekvens == null) //fřrste forekomst 74 forekomster.put(ord, 1); 75 else //oppdaterer frekvens 76 forekomster.put(ord, frekvens + 1); 77 } 78 } 79 catch (IOException e) 80 { 81 JOptionPane.showMessageDialog( this, 82 "Problem med lesing av fil." ); 83 } 84 } 85 else 86 JOptionPane.showMessageDialog( this, "Ingen fil valgt." ); 87 return forekomster; 88 } 89 90 //Skriver ut ord og frekvenser for valgt fil. 91 public void visFrekvenser( Map<String, Integer> frekvenser ) 92 { 93 if ( frekvenser != null ) 94 { 95 Iterator<Map.Entry<String,Integer>> iterator = 96 frekvenser.entrySet().iterator(); 97 utskrift.setText( "Ord og frekvenser\n" ); 98 while ( iterator.hasNext() ) 99 { 100 Map.Entry<String,Integer> e = iterator.next(); 101 utskrift.append( e.getKey() + ": " + e.getValue() + "\n" ); 102 } 103 utskrift.setCaretPosition( 0 ); 104 } 105 else 106 utskrift.setText( "Ingen fil lest inn." ); 107 } 108 109 private class Knappelytter implements ActionListener 110 { 111 public void actionPerformed( ActionEvent e ) 112 { 113 if ( e.getSource() == velgFil ) 114 { 115 File fil = hentFil(); 116 Map<String,Integer> forekomster = frekvenser(fil); 117 visFrekvenser( forekomster ); 118 } 119 } 120 } 121 }
Bildet under viser en del av utskriften som vi fĺr ved ĺ bruke programmet pĺ kildefila som definerer programvinduet.
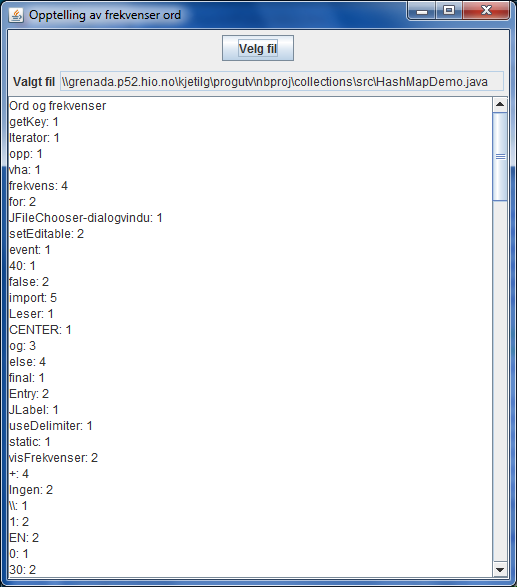
Programmet TreeMapDemo gjřr det samme som
programmet HashMapDemo med den forskjell at
ordene blir registrert og skrevet ut i alfabetisk rekkefřlge. De nřdvendige
endringer er som fřlger:
Det mĺ opprettes et Collator-objekt som gir
riktig rekkefřlge for ordene. Dette objektet blir brukt som konstruktřrparameter
nĺr det blir opprettet et TreeMap<String, Integer>-objekt. Dette
brukes istedenfor HashMap<String, Integer>-objektet i
forrige program. Vindusklasse for programmet finnes i fila
TreeMapDemo.java.
Driverklasse ligger i fila
TreeMapTest.java.
Den del av programmet som har med avbildningen ĺ gjřre er gjengitt nedenfor.
1 import javax.swing.*; 2 import java.awt.*; 3 import java.awt.event.*; 4 import java.util.*; 5 import java.io.*; 6 import java.text.*; 7 8 //Teller opp frekvenser for de forskjellige ord i valgt fil. 9 //Utskrift i alfabetisk rekkefřlge. 10 public class TreeMapDemo extends JFrame 11 { 12 private JButton velgFil; 13 private JTextArea utskrift; 14 private JTextField filvalg; 15 private Knappelytter lytter; 16 private String rekkefřlge; 17 private Collator kollator; 18 19 public TreeMapDemo() 20 { . . 42 rekkefřlge = "<\0<0<1<2<3<4<5<6<7<8<9" + 43 "<A,a<B,b<C,c<D,d<E,e<F,f<G,g<H,h<I,i<J,j" + 44 "<K,k<L,l<M,m<N,n<O,o<P,p<Q,q<R,r<S,s<T,t" + 45 "<U,u<V,v<W,w<X,x<Y,y<Z,z<Ć,ć<Ř,ř<Ĺ=AA,ĺ=aa;AA,aa"; 46 try 47 { 48 kollator = new RuleBasedCollator( rekkefřlge ); 49 //for riktig sortering av norske ord 50 } 51 catch ( ParseException pe ) 52 { 53 JOptionPane.showMessageDialog( null, 54 "Feil i rekkefřlgestring for kollator!" ); 55 System.exit( 0 ); 56 } 57 pack(); 58 setVisible( true ); 59 } 60 61 //Lar brukeren velg fil vha. et JFileChooser-dialogvindu. 62 public File hentFil() 63 { . . 76 } 77 78 //Leser valgt fil og registrerer frekvenser. 79 public Map<String,Integer> frekvenser( File fil ) 80 { 81 Map<String,Integer> forekomster = null; 82 if ( fil != null ) 83 { 84 forekomster = new TreeMap<>( kollator ); 85 try (Scanner ordleser = new Scanner( fil )) 86 { 87 ordleser.useDelimiter("[.,!;:*?`$\"\'/<>=\\(){}\\s]+"); 88 while ( ordleser.hasNext() ) 89 { 90 String ord = ordleser.next(); 91 Integer frekvens = forekomster.get( ord ); 92 if ( frekvens == null ) //fřrste forekomst 93 forekomster.put(ord, 1); 94 else //oppdaterer frekvens 95 forekomster.put( ord, frekvens + 1); 96 } 97 } 98 catch (IOException e) 99 { 100 JOptionPane.showMessageDialog( this, 101 "Problem med lesing fra fil." ); 102 } 103 } 104 else 105 JOptionPane.showMessageDialog( this, "Ingen fil valgt." ); 106 return forekomster; 107 } 108 109 //Skriver ut ord og frekvenser for valgt fil. 110 public void visFrekvenser( Map<String,Integer> frekvenser ) 111 { 112 if ( frekvenser != null ) 113 { 114 Iterator<Map.Entry<String,Integer>> iterator = 115 frekvenser.entrySet().iterator(); 116 utskrift.setText( "Ord og frekvenser\n" ); 117 while ( iterator.hasNext() ) 118 { 119 Map.Entry<String,Integer> e = iterator.next(); 120 utskrift.append( e.getKey() + ": " + e.getValue() + "\n" ); 121 } 122 utskrift.setCaretPosition( 0 ); 123 } 124 else 125 utskrift.setText( "Ingen fil lest inn." ); 126 } 127 128 private class Knappelytter implements ActionListener 129 { 130 public void actionPerformed( ActionEvent e ) 131 { 132 if ( e.getSource() == velgFil ) 133 { 134 File fil = hentFil(); 135 Map<String,Integer> forekomster = frekvenser( fil ); 136 visFrekvenser( forekomster ); 137 } 138 } 139 } 140 }
Bildet under viser en del av utskriften som programmet gir nĺr det blir brukt pĺ samme fil som foregĺende program ble brukt pĺ, se bildet ovenfor.
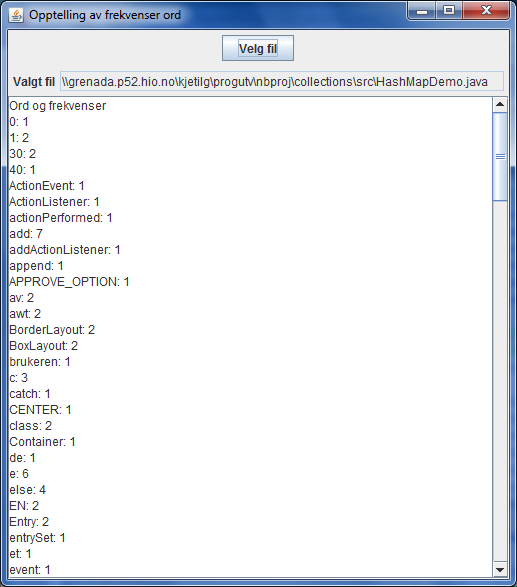
Innholdsoversikt for programutvikling
Copyright © Kjetil Grřnning og Eva Hadler Vihovde, revidert 2015