Vurderingskriterier De 10 bokstavpunktene (1A, 1B, 2A, osv) har samme vekt. På hvert gis det fra 0 til 10 poeng. Hvis det er svart riktig på det som det spørres etter, koden (i kodeoppgaver) virker som den skal, er effektiv og ikke bruker unødvendige hjelpestrukturer, er uten nevneverdige syntaksfeil og er brukbart forklart/dokumentert, så gis det 10 poeng. Hvis et bokstavpunkt er delt opp, vil vanskelighetsgraden normalt avgjøre delenes vekt.
Også ineffektiv og tungvint kode som er dårlig forklart/dokumentert, men som virker, vil kunne gi poeng, men ikke fullt hus. Ellers blir det fratrekk for alvorlige synstaksfeil, gal kode, mangler og logiske feil i koden, feil bruk av metoder og klasser og manglende forklaringer. Det gis 0 poeng hvis en oppgave er blank, misforstått eller er helt feil besvart.
Programkode kan være selvforklarende hvis det er enkle algoritmer med standard kodeteknikk. Men hvis algoritmen eller koden som lages er mer innfløkt, er det viktig med forklaringer. Det kan hende at en har en idé som ville ha virket, men som er kodet feil eller mangelfullt. Hvis en da ikke har forklaringer, kan det være vanskelig eller umulig å forstå det som er laget. Dermed risikerer en å få færre poeng (eller 0 poeng) enn det en ellers ville ha fått. Forklaringer kan være med ord og/eller tegninger.
I oppgaver der det ikke skal lages kode, må det være med begrunnelser for svarene - tekst og/eller tegninger. I oppgaver der det spørres etter en utskrift, er det spesielt viktig med forklaringer. Hvis det en har satt opp som utskrift er feil, kan en risikere å få 0 poeng hvis forklaringer mangler. Det kan jo hende at en har tenkt riktig, men kun gjort noen småfeil. Men uten forklaringer er det ikke mulig å vite om det er småfeil eller om en kun har gjettet.
Poengene på hvert av de 10 bokstavpunktene summeres. Maksimal poengsum er 100.
Følgende karakterskala brukes:
A: minst 90 poeng
B: minst 75 poeng
C: minst 60 poeng
D: minst 50 poeng
E: minst 40 poeng
F: færre enn 40 poeng
Oppgave 1A
Flg. metode snur tabellen ved hjelp av en serie ombyttinger. Den er av orden n og bruker ingen hjelpestrukturer:
public static void bytt(int[] a, int i, int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } public static void snu(int[] a) { for (int v = 0, h = a.length - 1; v < h;) bytt(a, v++, h--); }
Flg. metode som også er av orden n, bruker en hjelpetabell:
public static void snu(int[] a) { int[] b = a.clone(); for (int i = b.length - 1, j = 0; i >= 0; i--, j++) a[j] = b[i]; }
Oppgave 1B
Det enkleste er å starte i venstre ende og så se på én og én verdi inntil vi finner søkeverdien eller til vi
kommer for langt, dvs. vi finner den første av de som er større. Her må en passe spesielt på tilfellet
at søkeverdien er større enn den største av verdien i tabellen. En slik metode blir av orden n i gjennomsnitt.
public static int finn(int[] a, int verdi) { int i = 0; while (i < a.length && a[i] < verdi) i++; if (i < a.length && a[i] == verdi) return i; else return -(i + 1); }
Det optimale er å bruke binærsøk. Den er av logaritmisk orden i gjennomsnitt:
public static int finn(int[] a, int verdi) { int v = 0, h = a.length - 1; // hver sin ende av tabellen while (v <= h) // fortsetter så lenge som a[v:h] ikke er tom { int m = (v + h)/2; // heltallsdivisjon - finner midten int midtverdi = a[m]; // hjelpevariabel for midtverdien if (verdi > midtverdi) v = m + 1; // verdi i a[m+1:h] else if (verdi < midtverdi) h = m - 1; // verdi i a[v:m-1] else break; // funnet } if (v > h) return -(v + 1); // v er innsettingspunktet // må finne den første hvis det er flere forekomster av verdi while (v > 0 && a[v - 1] == verdi) v--; return v; }
Oppgave 2A
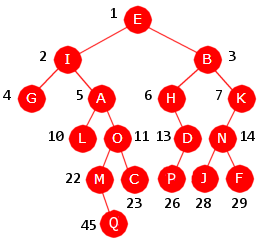 |
Nivåorden: E, I, B, G, A, H, K, L, O, D, N, M, C, P, J, F, Q
Inorden: G, I, L, A, M. Q, O, C, E, H, P, D, B, J, N, F, K
Oppgave 2B
i) Speilvendt nivåorden: 51, 31, 20, 16, 15, 11, 9, 8, 7, 6, 5, 4, 3, 2, 1
Et binærtre er fullt hvis hver node enten har ingen barn eller to barn.
ii)
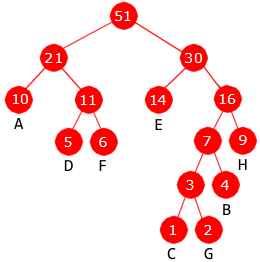 |
Oppgave 3A
public static <T> int fjernBakerst(Kø<T> kø, int antall) { if (antall < 0) throw new IllegalArgumentException("Negativt antall!"); int n = kø.antall(); if (antall >= n) { kø.nullstill(); return n; } for (int i = n - antall; i > 0; i--) kø.leggInn(kø.taUt()); for (int i = 0; i < antall; i++) kø.taUt(); return antall; }
Oppgave 3B
Det starter med at bokstavene E, D, C, B og A forløpende legges på stakken stakk. Det fører
til at E havner på bunnen og A på toppen av stakken. Dvs. slik:
| A B C D F |
| stakk |
Deretter skrives innholdet (et implisitt kall på stakkens toString-metode) ut.
Da kommer toppen (se grensesnittet Stakk i vedlegget) først, osv. Dermed blir
utskriften (slik som det også står i oppgaveteksten): [A, B, C, D, E].
Deretter flyttes alle verdiene fra stakk, bortsett fra den siste (nederste),
over på stakken hjelp. Det betyr at den som lå øverst på stakk nå kommer
nederst på hjelp, osv.
| E |
D C B A |
|
| stakk | hjelp |
Så flyttes den som er igjen på stakk (dvs. E) over i hjelpevariabelen
temp. Deretter flyttes alle verdiene fra hjelp tilbake
til stakk. Det betyr at den som lå øverst på hjelp nå havner
på bunnen av stakk, osv. Til slutt legges verdien i temp (dvs. E) over på stakk
og den kommer da på toppen. Dvs. slik:
| E A B C D |
||
| stakk | hjelp |
Til slutt skrives innholdet (et implisitt kall på stakkens toString-metode) ut.
Dermed blir utskriften: [E, A, B, C, D].
Oppgave 4A
Innlegging av 10, 5, 9, 1, 15, 13, 4, 6, 8, 2, 14, 11, 12, 3. Høyden blir 5.
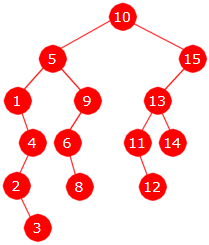 |
Fjerning av 1: Siden 1-noden har kun ett barn, fjernes noden (og verdien) ved å endre en referanse slik at 4-noden blir venstre barn til 5-noden.
Fjerning av 10: Noden med verdi 10 har to barn. Da sier algoritmen at noden beholdes, men verdien erstattes med med verdien i den noden som kommer rett etter i inorden (dvs. 11). Den noden fjernes ved å endre en referanse siden den har kun ett barn. Dvs. at 12-noden blir venstre barn til 13-noden.
Etter fjerningen av 1 og 10 får treet høyde 4.
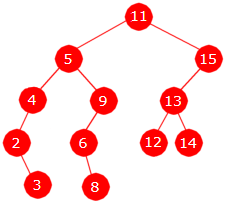 |
Oppgave 4B
Den minste verdien i et binært søketre er den som kommer først i inorden, dvs. den som ligger nederst på treets venstre «ryggrad». Dit kommer vi ved å starte i roten og så gå til venstre så langt vi kommer.
public T min() { if (tom()) return null; Node<T> p = rot; while (p.venstre != null) p = p.venstre; return p.verdi; }
Oppgave 4C
i)
public void leggInn(T verdi) { Node<T> p = rot, q = null; int cmp = 0; int nivå = 0; // ny hjelpevariabel while (p != null) { q = p; nivå++; // ny programsetning cmp = comp.compare(verdi,p.verdi); p = cmp < 0 ? p.venstre : p.høyre; } p = new Node<>(verdi); if (q == null) rot = p; else if (cmp < 0) q.venstre = p; else q.høyre = p; if (nivå > høyde) høyde = nivå; // ny programsetning antall++; }
ii)
private int dybde(Node<T> p) { T verdi = p.verdi; Node<T> q = rot; int dybde = 0; while (q != p) { dybde++; q = comp.compare(verdi, q.verdi) < 0 ? q.venstre : q.høyre; } return dybde; }
Oppgave 4D
1. versjon bruker rekursjon:
@SuppressWarnings("unchecked") public T[] nedersteNivå() { List<T> liste = new ArrayList<>(); if (!tom()) nederstNivå(rot, liste, 0, høyde); return (T[]) liste.toArray(); } private static <T> void nederstNivå(Node<T> p, List<T> liste, int nivå, int høyde) { if (nivå == høyde) liste.add(p.verdi); if (p.venstre != null) nederstNivå(p.venstre, liste, nivå + 1, høyde); if (p.høyre != null) nederstNivå(p.høyre, liste, nivå + 1, høyde); }
Metoden er av orden n siden vi går gjennom treet én gang og siden vi for hver node gjør en oppgave av konstant orden.
2. versjon bruker en kø. Vi traverserer i nivåorden og det er først når vi kommer til nederste nivå at vi tar vare på verdiene (og legger dem i en T-tabell). Metoden får dermed orden n.
@SuppressWarnings("unchecked") public T[] nedersteNivå() { if (tom()) return (T[]) new Object[0]; int nivå = 0, høyde = høyde(), nivåAntall = 0; Kø<Node<T>> kø = new TabellKø<>(); kø.leggInn(rot); while (!kø.tom()) // så lenge som køen ikke er tom { nivåAntall = kø.antall(); // antallet på neste nivå // er neste nivå det nederste? if (nivå == høyde) break; for (int i = 0; i < nivåAntall; i++) // alle på nivået { Node<T> p = kø.taUt(); if (p.venstre != null) kø.leggInn(p.venstre); if (p.høyre != null) kø.leggInn(p.høyre); } nivå++; // fortsetter på neste nivå } T[] a = (T[]) new Object[nivåAntall]; int i = 0; while (!kø.tom()) a[i++] = kø.taUt().verdi; return a; }
3. versjon bruker også rekursjon, dvs. vi traverserer treet og for hver node kalles dybde-metoden. Det spiller ingen rolle om vi bruker preorden, inorden eller postorden. Nodene på nederste nivå (som alle er bladnoder) kommer i samme rekkefølge for hver av dem. Her velger vi preorden. Vi tar vare på de nodverdiene som ligger i noder på nederste nivå (dvs. dybde lik treets høyde). Siden dybde-metoden i gjennomsnitt er av logaritmisk orden, vil algoritmen som helhet bli av orden nlog(n).
private void nederstNivå(Node<T> p, int høyde, List<T> liste) { if (dybde(p) == høyde) liste.add(p.verdi); if (p.venstre != null) nederstNivå(p.venstre, høyde, liste); if (p.høyre != null) nederstNivå(p.høyre, høyde, liste); } @SuppressWarnings("unchecked") public T[] nedersteNivå() { List<T> liste = new ArrayList<>(); if (!tom()) nederstNivå(rot, høyde, liste); return (T[]) liste.toArray(); }