VIKTIG Programkode kan være selvforklarende hvis det er enkle algoritmer og en bruker standard kodeteknikk. Men hvis algoritmen eller koden som lages, er mer infløkt er det viktig med forklaringer. Det kan hende at en har en idé som ville ha virket, men som er kodet feil eller mangelfullt. Hvis en da ikke har forklaringer, kan det være vanskelig eller umulig å forstå det som er laget. Dermed risikerer en å få færre poeng (eller 0 poeng) enn det en ellers ville ha fått.
I oppgaver der det f.eks. spørres etter en utskrift, er det spesielt viktig med forklaringer. Hvis det en har satt opp som utskrift er feil, kan en risikere å få 0 poeng hvis forklaringer mangler. Det kan jo hende at en har tenkt riktig, men kun gjort noen småfeil. Men uten forklaringer er det ikke mulig å vite om det er småfeil eller om feilen skyldes at en har bommet fullstendig.
OBS: I oppgaveteksten står det at «De 10 bokstavpunktene teller likt, men hvis et bokstavpunkt er delt opp, kan en krevende del telle mer enn en enkel del». Nedenfor står det mer om hvor mye de ulike delene teller.
Oppgave 1A
1) En stakk «vokser oppover». Først legges bokstaven A på stakken, så B oppå A, osv. Til slutt legges G øverst.
Metoden toString() lager en tegnstreng som starter med verdien øverst og fortsetter så nedover.
Stakken B er tom. Dermed denne utskriften:
[G, F, E, D, C, B, A] []
2) Så flyttes alle verdiene fra stakk A til stakk B. Det betyr at verdiene får motsatt rekkefølge sammenlignet med den de hadde på A. Stakk A har blitt tom. Dermed denne utskriften:
[] [A, B, C, D, E, F, G]
Oppgave 1B
Det står ikke noe i oppgaveteksten om hvordan null-verdier skal behandles. I Java er det minst tre klasser
som kan brukes som en stakk (har metodene push, peek og pop).
Det er Stack, LinkedList og ArrayDeque.
I de to første (Stack og LinkedList) er det tillatt å legge inn null-verdier og dermed også
å søke etter en null-verdi. Men ArrayDeque tillater ikke innlegging av null-verdier. Begge
stakk-klassene (TabellStakk og LenketStakk) som er laget i undervisningen, tillater
null-verdier. Se på flg. eksempel der javaklassen Stack inngår:
Stack<String> stakk = new Stack<>(); String[] navn = {"Per", "Kari", null, "Ole"}; // tabellen inneholder null for (String n : navn) stakk.push(n); System.out.println(stakk); System.out.println("Per har indeks " + stakk.indexOf("Per")); System.out.println("null har indeks " + stakk.indexOf(null)); // Utskrift: // [Ole, null, Kari, Per] // Per har indeks 3 // null har indeks 1
Hvis det er snakk om en stakk der det ikke kan være null-verdier, burde metoden indeks() returnere
-1 hvis verdi er null. Det er egentlig ikke galt å lete etter noe som ikke kan være der. Derfor
er det å kaste en NullPointerException egentlig ikke riktig. Men det viktigste er at man har tenkt
på (og gjort noe med) det at verdi kan være null.
Men hva er korrekt kode hvis stakken tillater null-verdier? I så fall må det også være mulig å søke etter dem.
Problemet dukker opp når verdier skal sammenlignes ved hjelp av metoden equals().
Hvis verdi1 skal sammenlignes med verdi2, får vi
verdi1.equals(verdi2). Hvis verdi1 ikke er
null og verdi2 lik null, går det bra. Da blir det false. Men hvis
verdi1 er null, blir det NullPointerException uansett hva verdi2 er.
Dette problemet kan takles slik:
public static <T> int indeks(Stakk<T> s, T verdi) { Stakk<T> hjelp = new TabellStakk<>(); // hjelpestakk int indeks = 0; // holder orden på rekkefølgen while (!s.tom()) { T stakkverdi = s.kikk(); // ser på den øverste if (stakkverdi == null) { if (verdi == null) break; // fant verdi (som er null) } else // stakkverdi != null { if (stakkverdi.equals(verdi)) break; // fant verdi } hjelp.leggInn(s.taUt()); // flytter til hjelpestakken indeks++; } while (!hjelp.tom()) s.leggInn(hjelp.taUt()); // legger tilbake return indeks == s.antall() ? -1 : indeks; // returnerer indeksen }
Hvis vi isteden tar som gitt at stakken ikke inneholder null-verdier, kan dette kodes litt kortere:
public static <T> int indeks(Stakk<T> s, T verdi) { if (verdi == null) return -1; // ingen nullverdier Stakk<T> hjelp = new TabellStakk<>(); // hjelpestakk int indeks = 0; // holder orden på rekkefølgen while (!s.tom()) { if (s.kikk().equals(verdi)) break; // fant verdi - avslutter hjelp.leggInn(s.taUt()); // flytter til hjelpestakken indeks++; } while (!hjelp.tom()) s.leggInn(hjelp.taUt()); // legger tilbake return indeks == s.antall() ? -1 : indeks; // returnerer indeksen }
Oppgave 1C
public static <T> void flytt(Kø<T> A, Kø<T> B) { int n = A.antall(); int m = Integer.min(n, B.antall()); for (int i = 0; i < m; i++) { A.leggInn(A.taUt()); // en fra A og A.leggInn(B.taUt()); // så en fra B } // må ta med det som måtte være igjen i A eller B for (int i = m; i < n; i++) A.leggInn(A.taUt()); while (!B.tom()) A.leggInn(B.taUt()); }
Oppgave 2A
I undervisningen (+ i Oblig 1) har flg. sorteringsalgoritmer blitt diskutert:
- Utvalgssortering (eng: selection sort), kvadratisk orden (orden n²)
- Innsettingssortering (eng: insertion sort), kvadratisk orden (orden n²)
- Boblesortering (eng: bubble sort), kvadratisk orden (orden n²)
- Kvikksortering (eng: quick sort), loglineær orden (orden n log(n))
- Flettesortering (eng: merge sort), loglineær orden (orden n log(n))
- Heapsortering (eng: heap sort), loglineær orden (orden n log(n))
Oppgaven gikk ut på å velge to av dem og i grove trekk forklare hvordan de virker. Her settes det opp kun én forklaring som eksempel på hvordan det kunne gjøres:
Utvalgssortering: La tabellen hete a og la
n være lengden. I første runde letes det etter den minste verdien
i a[0 , n >.
Den plasseres (ved en ombytting) først i tabellen (indeks 0).
I neste runde letes det etter den minste i a[1 , n >.
Den plasseres (ved en ombytting) nest først i tabellen (indeks 1). Så letes det etter
den minste verdien i a[2 , n >, osv. til tabellen er sortert.
Oppgave 2B
OBS: Det er dessverre en trykkfeil i oppgaveteksten. Den tredje bakerste verdien i tabellen skulle ha vært 25 og ikke 15 som det står. Slik som det nå står representerer ikke tabellen en minimumsheap. De som har sett feilen for bonus for det.
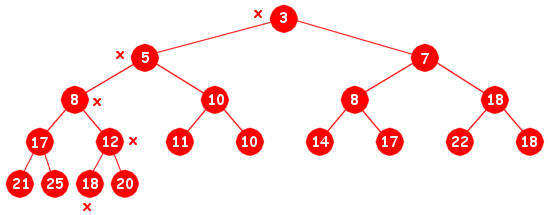 |
| Minimumsgrenen er markert med kryss |
Oppgave 3A
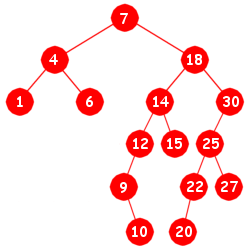 |
- Inorden: 1, 4, 6, 7, 9, 10, 12, 14, 15, 18, 20, 22, 25, 27, 30
- Preorden: 7, 4, 1, 6, 18, 14, 12, 9, 10, 15, 30, 25, 22, 20, 27
Oppgave 3B
Endringene er markert med rødt:
public boolean leggInn(T verdi) { Objects.requireNonNull(verdi, "Ikke tillatt med null-verdier!"); Node<T> p = rot, q = null; int cmp = 0; while (p != null) { q = p; // q blir forelder til p cmp = comp.compare(verdi, p.verdi); if (cmp < 0) p = p.venstre; else if (cmp > 0) p = p.høyre; else return false; // verdi finnes fra før } p = new Node<>(verdi); if (tom()) rot = p; else if (cmp < 0) q.venstre = p; else q.høyre = p; antall++; return true; // vellykket innlegging }
Oppgave 3C
Denne løsningen inneholder litt mer enn det bes om. Den private metoden
dybde() finner dybden til verdi i det
subtreet som har p som rot. Den metoden blir nyttig i
Oppgave 3D. Den offentlige metoden dybde() kaller den
private med treets rot som parameter:
// private hjelpemetode private int dybde(T verdi, Node<T> p) { int dybde = -1; while (p != null) { dybde++; int cmp = comp.compare(verdi, p.verdi); if (cmp < 0) p = p.venstre; else if (cmp > 0) p = p.høyre; else return dybde; } return -1; } // den offentlige metoden public int dybde(T verdi) { return dybde(verdi, rot); }
Oppgave 3D
i) Gitt to noder p og q. Hvis de to ikke ligger på samme gren, har
de en nærmeste felles forgjenger. Hvis vi sier at en node kan være sin egen forgjenger, så kan vi også si at
p og q har en nærmeste felles forgjenger selv
om de ligger på samme gren. Hvis p da er en forgjenger til q,
blir p nærmeste felles forgjenger for p og q.
Hvis isteden q er en forgjenger til p, blir q
nærmeste felles forgjenger for p og q.
Oppgaven kan løses på mange måter, men uansett teknikk må vi finne den nærmeste felles forgjengeren til
noden til verdi1 og noden til verdi2. En måte kunne være å
legge alle nodene på veien nedover (til verdi1 og til verdi2)
på en kø og så sammenligne de to køene. En annen måte er å søke og stoppe
der veien skiller seg. Vi velger den måten her:
public int avstand(T verdi1, T verdi2) { if (verdi1 == null || verdi2 == null) throw new NullPointerException("Treet har ikke nullverdier!"); // vi finner hvem som er minst og størst, og eventuelt // bytter om slik at verdi1 er mindre enn eller lik verdi2 if (comp.compare(verdi2, verdi1) < 0) { T tempverdi = verdi1; verdi1 = verdi2; verdi2 = tempverdi; } // vet nå at verdi1 <= verdi2 Node<T> p = rot; while (p != null) { if (comp.compare(verdi2, p.verdi) < 0) // verdi1 og verdi2 ligger til venstre p = p.venstre; else if (comp.compare(verdi1, p.verdi) > 0) // verdi1 og verdi2 ligger til høyre p = p.høyre; else break; // veien til de to deler seg i p } if (p == null) throw new NoSuchElementException("Verdiene ligger ikke i treet!"); int dybde1 = dybde(verdi1, p), dybde2 = dybde(verdi2, p); if (dybde1 == -1 || dybde2 == -1) throw new NoSuchElementException("Verdiene ligger ikke i treet!"); return dybde1 + dybde2; }
ii) Den største avstanden mellom to noder i treet i Oppgave 3A er den som er mellom 10-noden
og 20-noden og den er 8. Dvs. at treets diameter er 8. Hvis først 2 og så 3 legges inn, vil 2-noden bli høyre
barn til 1-noden og 3-noden høyre barn til 2-noden. Da vil 3-noden få en avstand opp til roten på 4 og avstanden fra
roten og ned til 10-noden (eller 20-noden) er 5. Dermed får vi to noder som har en avstand på 9.
Dvs. treets diameter nå blir 9.
iii)
Diameter er den største avstanden mellom to noder. En enkel, men ineffektiv teknikk, er å finne den ved
å finne avstanden mellom samtlige par av noder. Metoden avstand() er
i gjennomsnitt logaritmisk. I flg. metode inngår to løkker. Hvis treet har n noder, vil
metoden bli av orden n² log(n):
public int diameter() { int diameter = -1; // For-alle-løkkene virker fordi SBinTre er iterable for (T verdi1 : this) { for (T verdi2 : this) { int avstand = avstand(verdi1, verdi2); if (avstand > diameter) diameter = avstand; } } return diameter; }
Det er mulig å finne treets diameter med en algoritme av orden n. La
p og q være to noder som har størst avstand og la
f være nodenes nærmeste forgjenger. La sum være summen av
høydene til de to subtrærne til f. Da må avstanden mellom
p og q være lik sum + 2.
Det betyr at hvis vi under en traversering av treet for hver node vet hvilke høyder nodens to
subtrær har, så kan vi finne største sum. Dermed får vi diameter
ved å legge til 2.
Vi kan bruke samme type rekursive algoritme som den som finner treets høyde:
private static <T> int høyde(Node<T> p, int[] d) { if (p == null) return -1; int vHøyde = høyde(p.venstre, d); // høyden til venstre subtre int hHøyde = høyde(p.høyre, d); // høyden til høyre subtre if (vHøyde + hHøyde > d[0]) d[0] = vHøyde + hHøyde; // oppdaterer return Math.max(vHøyde, hHøyde) + 1; // returnerer høyden } public int diameter() { if (antall < 2) return antall - 1; // tomt eller kun en node int[] d = {-1}; høyde(rot, d); // traverserer return d[0] + 2; // returnerer diameter }
Oppgave 3E
1. forslag:
- Opprett en T-tabell like stor som antall verdier i parametertreet.
- Hent verdiene fra parametertreet og legg dem over i tabellen ved hjelp iteratoren.
- Sorter tabellen med hensyn på dybdeordningen av verdiene.
- Opprett et tomt tre med samme komparator som parametertreet.
- Ta verdiene fra den sorterte tabellen over i det nye treet.
public static <T> SBinTre<T> kopi(SBinTre<T> tre) { T[] a = (T[]) new Object[tre.antall()]; // hjelpetabell int i = 0; for (T x : tre) a[i++] = x; // fra tre til tabell Arrays.sort(a, (x,y) -> tre.dybde(x) - tre.dybde(y)); // et lambda-uttrykk SBinTre<T> kopi = new SBinTre<T>(tre.comparator()); // kopitreet for (T x : a) kopi.leggInn(x); // fra tabell til tre return kopi; }
2. forslag:
- Opprett en prioritetskø med dybdeordningen som ordning.
- Hent verdiene fra parametertreet og legg dem over i køen.
- Opprett et tomt tre med samme komparator som parametertreet.
- Ta verdiene fra køen over i det nye treet.
public static <T> SBinTre<T> kopi(SBinTre<T> tre) { HeapPrioritetsKø<T> kø = // en prioritetskø new HeapPrioritetsKø<>((x,y) -> tre.dybde(x) - tre.dybde(y)); for (T x : tre) kø.leggInn(x); // fra tre til kø SBinTre<T> kopi = new SBinTre<T>(tre.comparator()); // kopitreet while (!kø.tom()) kopi.leggInn(kø.taUt()); // fra kø til tre return kopi; }