VIKTIG Programkode kan være selvforklarende hvis det er enkle algoritmer og en bruker standard kodeteknikk. Men hvis algoritmen eller koden som lages, er mer infløkt, er det viktig med forklaringer. Det kan hende at en har en idé som ville ha virket, men som er kodet feil eller mangelfullt. Hvis en da ikke har forklaringer, kan det være vanskelig eller umulig å forstå det som er laget. Dermed risikerer en å få færre poeng (eller 0 poeng) enn de en ellers ville ha fått.
I oppgaver der det f.eks. spørres etter en utskrift, er det spesielt viktig med forklaringer. Hvis det en har satt opp som utskrift er feil, kan en risikere å få 0 poeng hvis forklaringer mangler. Det kan jo hende at en har tenkt riktig, men kun gjort noen småfeil. Men uten forklaringer er det ikke mulig å vite om det er småfeil eller om feilen skyldes at en har bommet fullstendig.
Oppgave 1A
1) Ali, Ole, Per, Azra, Jens, Anders, Jasmin
2)
Comparator<String> c = (x,y) ->
{
if (x.length() < y.length()) return -1;
else if (x.length() > y.length()) return 1;
else return x.compareTo(y);
};
Oppgave 1B
 |
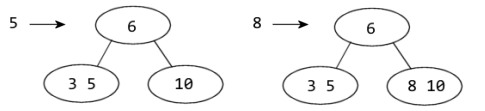 |
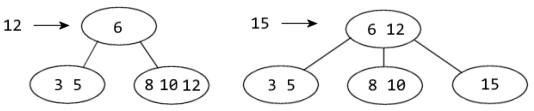 |
Oppgave 1C
 |
| Innlegging av 5 |
 |
| Innlegging av 2 |
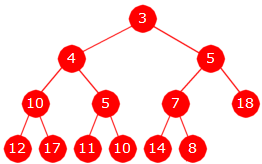
Minimumsgrenen starter i roten. For hver node går den så ned til det av de to barna som har minst verdi. For treet i Figur 1 har minimumsgrenen verdiene 3, 4, 5, 10.
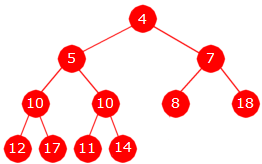 |
| Den minste i treet i Figur 1 er fjernet |
Oppgave 2A
Her får en kortest kode hvis en bruker en StringJoiner. Da må en imidlertid ha korrekt syntaks. I den konstruktøren
som krever «mellomrom», «start» og «slutt» som argumenter, er argumenttypen en CharSequence.
Hvis en bruker tegnstrenger, går det bra siden en String er en CharSequence.
Metoden add i StringJoiner har også
CharSequence som argumenttype. Et heltall kan da ikke brukes som argument.
Heltallet må «konverteres» til
en String. Feil syntaks vil gi poengtrekk i denne oppgaven.
public static String toString(int[] a) // en int-tabell { StringJoiner sj = new StringJoiner(", ", "[", "]"); // en StringJoiner for (int k : a) sj.add(Integer.toString(k)); // legger inn return sj.toString(); // returnerer }
Det er også mulig å bruke en StringBuilder. Det blir faktisk litt mer effektivt. Hvis en ser på
implementasjonen av en StringJoiner, vil en se at den bruker en StringBuilder internt:
public static String toString(int[] a) // en int-tabell { StringBuilder sb = new StringBuilder("["); // en StringBilder if (a.length > 0) { sb.append(a[0]); // den første for (int i = 1; i < a.length; i++) // resten sb.append(',').append(' ').append(a[i]); // ok med append } return sb.append(']').toString(); // returnerer }
Det er også mulig å bruke «konkatenering». Det betyr at en tegnstreng bygges opp ved at det fortløpende skjøtes på verdier. Hvis det er snakk om mange verdier, er dette imidlertid en ekstremt ineffektiv teknikk. I undervisningen har det også tydelig blitt sagt ifra at dette er en teknikk som man skal unngå. De som likevel velger en slik løsning, vil få poengtrekk:
public static String toString(int[] a) { String s = "["; if (a.length > 0) { s += a[0]; for (int i = 1; i < a.length; i++) { s += ", " + a[i]; } } s += ']'; return s; }
Oppgave 2B
En enkel (men ikke effektiv) teknikk er ta hver verdi i den ene tabellen og så sjekke om den ligger i den
andre tabellen. Hvis ja, legges verdien i en hjelpetabell. Hvis den ene tabellen har m
verdier og den andre n verdier, vil flg. metode i gjennomsnitt få orden m·n.
public static int[] snitt(int[] a, int[] b) { int m = Math.min(a.length, b.length); // den minste lengden int[] c = new int[m]; // hjelpetabell int antall = 0; // antall i snittet for (int i = 0; i < a.length; i++) // går gjennom a { int verdi = a[i]; int j = 0; for (; j < b.length; j++) // går gjennom b { if (b[j] >= verdi) break; // kan stoppe her } if (j < b.length && verdi == b[j]) // sjekke b[j] { c[antall++] = verdi; // hører med i snittet } } return Arrays.copyOf(c, antall); // returnerer resultatet }
Vi kan forbedre metoden over hvis vi bruker binærsøk til å avgjøre om verdi ligger i
tabellen b. Hvis a har m verdier og
b har n verdier, vil metoden i gjennomsnitt få orden m log(n).
public static int[] snitt(int[] a, int[] b) { int m = Math.min(a.length, b.length); // den minste lengden int[] c = new int[m]; // hjelpetabell int antall = 0; // antall i snittet for (int i = 0; i < a.length; i++) // går gjennom a { if (Arrays.binarySearch(b, a[i]) >= 0) // binærsøk i b { c[antall++] = a[i]; } } return Arrays.copyOf(c, antall); // returnerer resultatet }
Det mest effektive er å bruke en «fletteteknikk». Hvis a har m verdier og
b har n verdier, vil den i gjennomsnitt få orden m + n.
public static int[] snitt(int[] a, int[] b) { int m = Math.min(a.length, b.length); // den minste lengden int[] c = new int[m]; // hjelpetabell int antall = 0; // antall i snittet int i = 0, j = 0; while (i < a.length && j < b.length) { if (a[i] < b[j]) i++; // hopper over a[i] else if (a[i] == b[j]) // samme verdi i a og b { c[antall++] = a[i]; // legger inn a[i] i++; j++; // går videre } else j++; // hopper over b[j] } return Arrays.copyOf(c, antall); // returnerer resultatet }
Oppgave 2C
public static <T> T maks(Kø<T> kø, Comparator<? super T> c) { if (kø.tom()) throw new NoSuchElementException("Køen er tom!"); int antall = kø.antall(); // antall i køen T maksverdi = kø.taUt(); // tar ut den første kø.leggInn(maksverdi); // legger den bakerst for (int i = 1; i < antall; i++) // går gjennom resten av køen { T verdi = kø.taUt(); // tar ut den første if (c.compare(verdi, maksverdi) > 0) // sammenligner { maksverdi = verdi; // ny maksverdi } kø.leggInn(verdi); // legger inn bakerst } return maksverdi; // returnerer største verdi }
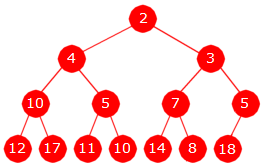
Oppgave 3A
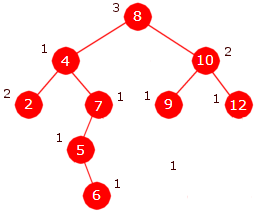 |
| Et tre med nodeduplikater |
Oppgave 3B
public int inneholder(T verdi) { if (verdi == null) return 0; // ingen null-er i treet Node<T> p = rot; while (p != null) { int cmp = comp.compare(verdi, p.verdi); if (cmp < 0) p = p.venstre; else if (cmp > 0) p = p.høyre; else return p.forekomster; } return 0; }
Oppgave 3C
public boolean leggInn(T verdi) { if (verdi == null) throw new NullPointerException("En null-verdi er ulovlig!"); Node<T> p = rot, q = null; // p starter i roten int cmp = 0; // hjelpevariabel while (p != null) { q = p; // q skal være forelder til p cmp = comp.compare(verdi, p.verdi); // bruker komparatoren if (cmp < 0) p = p.venstre; else if (cmp > 0) p = p.høyre; else break; // verdi ligger i p } if (p == null) // har ikke hatt verdi tidligere { p = new Node<>(verdi); if (q == null) rot = p; else if (cmp < 0) q.venstre = p; else q.høyre = p; } else // p inneholder verdi { if (p.forekomster == 0) tommeNoder--; // fra tom til ikke-tom node p.forekomster++; // en mer av p sin verdi } antall++; // én verdi mer i treet return true; }
Oppgave 3D
En iterator i et binærtre skal «bevege seg» gjennom treet - fra node til node. Her skal
det foregå i inorden. Hvis vi står på en node og den har et ikke-tomt høyre subtre, finner vi
dens neste i inorden ved å gå lengst ned til venstre i subtreet. Hvis det høyre subtreet er tomt, så står vi enten på
siste node eller vi må oppover mot roten for å finne den neste.
Hvis nodene (slik som i Oblig 3 og i klassen TreeSet i java.util)
har en forelderpeker, er det enkelt å gå oppover. Men slik er det ikke i denne oppgaven. Istedenfor å gå oppover, er det
mulig å starte i roten og gå nedover. Det er det ikke vanskelig å kode, men det blir normalt ineffektivt.
Løsningen er derfor å bruke en stakk. Dette ble tatt opp og diskutert ved flere anledninger i undervisningen - både i forbindelse med
iterativ traversering i et binærtre
og i forbindelse med iterator-teknikker i et binærtre.
Klassen InordenIterator ble da laget
slik:
////////////////// class InordenIterator ////////////////////////////// private class InordenIterator implements Iterator<T> { private Stakk<Node<T>> s = new TabellStakk<>(); private Node<T> p = null; private Node<T> først(Node<T> q) // en hjelpemetode { while (q.venstre != null) // starter i q { s.leggInn(q); // legger q på stakken q = q.venstre; // går videre mot venstre } return q; // q er lengst ned til venstre } private InordenIterator() // konstruktør { if (tom()) return; // treet er tomt p = først(rot); // bruker hjelpemetoden } public T next() { if (!hasNext()) throw new NoSuchElementException("Ingen verdier!"); T verdi = p.verdi; // tar vare på verdien if (p.høyre != null) p = først(p.høyre); // p har høyre subtre else if (s.tom()) p = null; // stakken er tom else p = s.taUt(); // tar fra stakken return verdi; // returnerer verdien } public boolean hasNext() { return p != null; } } // InordenIterator
Men denne oppskriften vil ikke virke på riktig måte i vår eksamensoppgave. For det første må iteratoren hoppe over
de «tomme» nodene. Videre må metoden next() returnere samme verdi like
mange ganger som forekomster i noden sier. Poenget er at alle duplikatene av en verdi ligger i samme
node. Det er forekomster som forteller hvor mange det er.
Vi kan løse dette ved å lage en metode nesteNode() som hopper over «tomme» noder. I tilegg
innfører vi en instansvariabel forekomster i iteratorklassen. Den økes med 1 for hver gang
next() returnerer samme verdi. Den stilles tilbake til 1 når vi flytter til neste ikke-tomme node:
private class InordenIterator implements Iterator<T> { private Stakk<Node<T>> s = new TabellStakk<>(); private Node<T> p = null; private int forekomster = 1; // En metode som finner den første i inorden i treet med q som rot private Node<T> først(Node<T> q) // en hjelpemetode { while (q.venstre != null) // starter i q { s.leggInn(q); // legger q på stakken q = q.venstre; // går videre mot venstre } return q; // q er lengst ned til venstre } // En metode som finner neste ikke-tomme node private Node<T> nesteNode(Node<T> p) { while (true) { if (p.høyre != null) p = først(p.høyre); else if (!s.tom()) p = s.taUt(); else return null; // p var siste node i inordne if (p.forekomster > 0) return p; // p er en ikke-tom node } } private InordenIterator() // konstruktør { if (tom()) return; // treet er tomt p = først(rot); // hjelpemetoden if (p.forekomster == 0) p = nesteNode(p); // hjelpemetoden } public T next() { if (!hasNext()) throw new NoSuchElementException("Ingen verdier!"); T verdi = p.verdi; // tar vare på verdien if (forekomster >= p.forekomster) // ferdig med denne noden? { forekomster = 1; // setter til 1 p = nesteNode(p); // neste ikke-tomme node } else forekomster++; // flere igjen i noden return verdi; // returnerer nodeverdien } public boolean hasNext() { return p != null; } } // InordenIterator
Det er noen som tenker seg at dette kan løses ved å traversere hele treet på forhånd og så legge alle verdiene over i en annen
struktur - en struktur som det er lett å hente fra. I så fall kan metoden next() kodes ved at én og én verdi hentes fra denne
strukturen. Den store ulempen med det er den ekstra plassen (av samme størrelsesorden som selve treet) som trengs. Det blir også
svært ineffektivt i
de tilfellene vi ønsker å bruke iteratoren til å finne f.eks. den minste verdien (første kall på next) eller verdier i første del av treet.
Andre problemer vil dukke opp f.eks. med en eventuell koding av iteratorens remove-metode.
En slik løsning (gitt at den behandler «tomme» noder og noder der forekomster er større enn 1 på rett måte)
vil kunne gi poeng, men et godt stykke fra fullt hus. En liten fordel med denne ideen er at koden blir litt kortere. Her er
et eksempel på hvordan det kunne gjøres:
private class InordenIterator implements Iterator<T> { private Stakk<T> s = new TabellStakk<>(); // obs: T-verdier i stakken private Node<T> p = null; // traverserer rekursivt i omvendt inorden og // legger alle verdiene over i en stakk private void traverser(Node<T> p, Stakk<T> s) { if (p.høyre != null) traverser(p.høyre, s); for (int i = 0; i < p.forekomster; i++) s.leggInn(p.verdi); if (p.venstre != null) traverser(p.venstre, s); } private InordenIterator() { if (tom()) return; p = rot; traverser(p, s); // traverserer og fyller opp stakken } public boolean hasNext() { return p != null; } public T next() { if (!hasNext()) throw new NoSuchElementException("Ingen verdier!"); T verdi = s.taUt(); // tar ut en verdi fra stakken if (s.tom()) p = null; // ikke flere igjen return verdi; } } // InordenIterator