Oppgave 1A
Tabellen har lengde 9. Midtverdien 7 ligger i posisjon/indeks 4.
Binærsøk returnerer posisjonen til den søkte verdien. Siden 13 ligger i posisjon/indeks 6,
vil i bli 6. Hvis den søkte verdien ikke ligger i tabellen, vil binærsøk
returnere -(k + 1) der k er innsettingspunktet til verdien.
Det betyr at j blir -8 siden innsettingspunktet til 14 er 7.
Utskriften blir derfor: 6 -8 (Verdiene til
i og j kan en også finne ved å følge gangen i algoritmen.)
Oppgave 1B
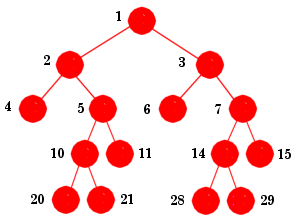 |
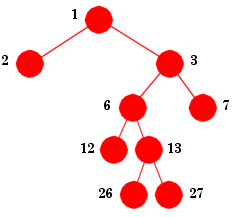 |
| Oppgave 1B - 1 | Oppgave 1B - 2 |
1. Posisjonstallmengden = {1,2,3,4,5,6,7,10,11,14,15,20,21,28,29}
Bladnodeposisjonstallmengden = {4,6,11,15,20,21,28,29}
2. Bladnodeposisjonstallmengden = {2,7,12,26,27}
Oppgave 1C
Hver verdi k i tabellen pos er en nodeposisjon. Eventuelle barn til k
vil ha 2k og 2k + 1 som nodeposisjoner. Hvis ingen av dem finnes i pos,
vil k representere en bladnode. I flg. metode brukes binærsøk til å lete etter
2k og 2k + 1. Det vil fungere siden pos er sortert og siden binærsøk
returnerer et negativt tall hvis den søkte verdien ikke finnes.
public static int[] bladnodeposisjoner(int[] pos) { int[] a = new int[pos.length/2 + 1]; // hjelpetabell int antall = 0; // antall bladnoder for (int i = 0; i < pos.length; i++) // går gjennom pos-tabellen { int k = pos[i]; // en nodeposisjon // sjekker om k har barn if (binærsøk(pos,2*k) < 0 && binærsøk(pos,2*k + 1) < 0) { a[antall++] = k; // k er posisjonen til en bladnode } } return Arrays.copyOf(a,antall); }
La pos ha lengde n. For hver k i pos brukes to kall
på binærsøk og hvert av dem er av orden log(n). Dermed blir hele
metoden over av orden n log(n).
Metoden over kan optimaliseres en del, men vil imidlertid fortsatt være n log(n).
La halvparten av den siste (og største) verdien i tabellen pos hete m.
Da vil alle nodeposisjoner k som er større enn m være
bladnodeposisjoner siden 2k (og 2k + 1) da vil være større enn den
største i tabellen. Videre hvis binærsøk sier at 2k ikke er i tabellen,
så vil den samtidig gi oss innsettningspunktet. Der må da 2k + 1 ligge hvis den er der.
Dette gir flg. optimalsering:
public static int[] bladnodeposisjoner(int[] pos) { int[] a = new int[pos.length/2 + 1]; // hjelpetabell int antall = 0; // antall bladnoder int m = pos[pos.length - 1]/2; // halvparten av den største int i = 0; for (; ; i++) // går gjennom pos-tabellen { int k = pos[i]; // en nodeposisjon if (k > m) break; // denne og resten er bladnodeposisjoner // sjekker om k har barn int j = binærsøk(pos,2*k); if (j < 0) { j = -(j + 1); // innsettingspunktet if (pos[j] != 2*k + 1) a[antall++] = k; // bladnodeposisjon } } for (; i < pos.length; i++) a[antall++] = pos[i]; // tar med resten return Arrays.copyOf(a,antall); }
Vi kan lage en løsning som har orden n ved å gå gjennom pos-tabellen en gang og halvere
alle posisjonene i tabellen. Hvis f.eks.
pos = {1,2,3,4,5,6,7,10,11,14,15,20,21,28,29}, vil en halvering
gi flg. resultat: {1,1,1,2,2,3,3,5,5,7,7,10,10,14,14}. Men vi koder det slik at vi
kun tar med de som er forskjellige, dvs. {1,2,3,5,7,10,14}. Dermed har vi fått
posisjonene til de indre nodene i treet. Da vil mengdedifferensen mellom disse gi oss
bladnodeposisjonene:
{1,2,3,4,5,6,7,10,11,14,15,20,21,28,29} − {1,2,3,5,7,10,14} = {4,6,11,15,20,21,28,29}
Løsningen blir orden n fordi vi går gjennom tabellen kun én gang i halveringsrunden. Mengdedifferensen finner vi ved å bruke en fletteteknikk som også er av orden n. Dermed blir hele metoden av orden n. Se løsningen under:
public static int[] bladnodeposisjoner(int[] pos) { int[] a = new int[pos.length/2 + 1]; // hjelpetabell a[0] = pos[0]; int m = 1; // en tellevariabel for (int i = 2; i < pos.length; i++) { int k = pos[i]/2; // en indre node if (k != a[m-1]) a[m++] = k; // har ikke hatt k før } int[] c = new int[pos.length - m]; // finner differensen mellom pos og a int i = 0, j = 0, k = 0; while (i < pos.length && j < m) { if (pos[i] < a[j]) c[k++] = pos[i++]; else if (pos[i] == a[j]) {i++; j++;} else j++; } while (i < pos.length) c[k++] = pos[i++]; return c; }
Oppgave 2A
Per, Kari, Ole og Elin legges på den første stakken. Der er Elin øverst og havner derfor på bunnen når verdiene flyttes fra den første til den andre stakken. På toppen av den andre stakken kommer Per. Når verdiene til slutt hentes fra den andre stakken og skrives ut, blir utskriften lik: Per Kari Ole og Elin
Oppgave 2B
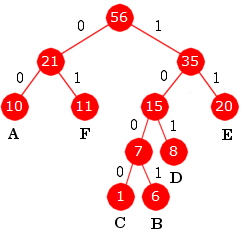 |
A = 00 B = 1001 C = 1000 D = 101 E = 11 F = 01 10010010111 = BADE |
Oppgave 3A
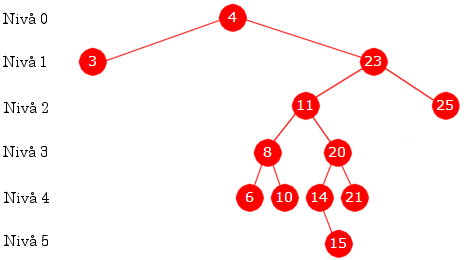 |
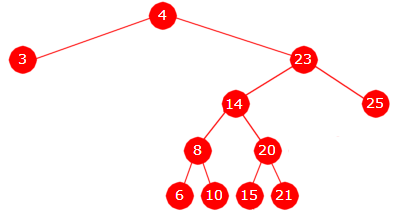
| Innsetting av 4, 23, 11, 3, 25, 8, 10, 20, 14, 6, 15, 21 |
Treet har 6 nivåer:
Nivå 0: 1 node Nivå 1: 2 noder Nivå 2: 2 noder Nivå 3: 2 noder Nivå 4: 4 noder Nivå 5: 1 node
Verdien 11 ligger i en node p som har to barn. Da sier algoritmen at verdien i p skal erstattes med verdien i den noden q som kommer rett etter p i inorden, dvs. erstattes med 14. Noden q (som inneholder 14) skal isteden fjernes. Det er enkelt siden den kun har ett barn. Det gjøres ved at pekeren ned til q isteden settes til å peke på det høyre barnet til q.
 |
| Treet etter at 11 er fjernet |
Oppgave 3B
Klassen har en variabel med navn høyde som inneholder treets høyde. Klassens
konstruktør setter den til -1 slik at den da har verdi -1 i et tomt tre. Det er en del som
i sin løsning bruker rot.høyde. Men det er åpenbart avskrift fra en tidligere
eksamensoppgave. I den oppgaven hadde hver node en variabel med navn høyde og
den hadde som verdi høyden til subtreet med denne noden som rotnode. Men det er
meningsløst å bruke rot.høyde i årets oppgave siden nodene (og dermed rotnoden)
ikke har noen høyde-variabel.
public int høyde() { return høyde; // returnerer treets høyde }
Oppgave 3C
Den ekstra koden er markert med rødt:
public void leggInn(T verdi) { if (verdi == null) throw new NullPointerException("Nullverdier er ulovlig!"); Node<T> p = rot, q = null; int cmp = 0, nivå = 0; while (p != null) { q = p; cmp = comp.compare(verdi, p.verdi); if (cmp < 0) p = p.venstre; else p = p.høyre; nivå++; } p = new Node<>(verdi); if (q == null) rot = p; else if (cmp < 0) q.venstre = p; else q.høyre = p; antall++; if (nivå > høyde) høyde = nivå; }
Oppgave 3D
Den søkte verdien er den siste/største av de verdiene som er mindre enn verdi.
Her kan vi bruke flg. idé: Hvis verdi er mindre enn eller lik verdien i en node p,
så må den søkte verdien ligge til venstre for p. Hvis verdi er større enn
verdien i en node p, kan verdien i p være en kandidat for den søkte verdien.
Flg. metode blir av orden log2(n) i gjennomsnitt:
public T mindre(T verdi) { Node<T> p = rot, q = null; while (p != null) { if (comp.compare(verdi, p.verdi) <= 0) p = p.venstre; else { q = p; p = p.høyre; } } return q == null ? null : q.verdi; }
Det er mulig å løse dette på en noe mer «primitiv» (og ineffektiv) måte ved
å traversere treet i inorden og så stoppe når vi har kommet til den første noden
som inneholder verdi eller når vi eventuelt har kommet for langt (verdi
ligger ikke i treet). Flg. metode er av orden n i gjennomsnitt:
public T mindre(T verdi) { if (tom()) return null; Node<T> p = rot; Stakk<Node<T>> s = new TabellStakk<>(); while (p.venstre != null) { s.leggInn(p); p = p.venstre; } // p er nå den første i inorden if (comp.compare(verdi,p.verdi) <= 0) return null; while (true) { Node<T> q = p; if (p.høyre != null) { p = p.høyre; while (p.venstre != null) { s.leggInn(p); p = p.venstre; } } else if (s.tom()) { return p.verdi; } else p = s.taUt(); if (comp.compare(verdi,p.verdi) <= 0) return q.verdi; } }
Oppgave 3E
En mulig løsning er å traversere treet og så registere verdien i hver node som ligger på nivået nivå.
Bruker vi en rekursiv traversering i pre-, in- eller postorden, får vi tak i en nodes nivå ved hjelp av
en parameter som øker med 1 når vi går til venste og høyre barn. Det spiller ingen rolle om vi bruker
pre-, in- eller postorden siden noder på samme nivå kommer i samme rekkefølge i alle tre tilfellene.
En svakhet med denne løsningen er at hele treet må traverseres selv om det er en av de øverste nivåene vi er
interessert i. Metoden får orden n der n er antallet noder i treet.
public String nivåVerdier(int nivå) { if (nivå < 0 || nivå > høyde) throw new NoSuchElementException("Nivå " + nivå + " finnes ikke!"); Liste<T> liste = new TabellListe<>(); nivåVerdier(rot, liste, 0, nivå); return liste.toString(); } //ker aktuelt nivå, mensnivåer nivået vi skal til // verdiene pånivålegges inn i en liste private void nivåVerdier(Node<T> p, Liste<T> liste, int k, int nivå) { if (p.venstre != null) nivåVerdier(p.venstre, liste, k + 1, nivå); if (k == nivå) liste.leggInn(p.verdi); if (p.høyre != null) nivåVerdier(p.høyre, liste, k + 1, nivå); }
I gjennomsnitt vil det bli mer effektivt å traversere i nivåorden. Da kan vi stoppe når vi er ferdig med det nivået som det spørres etter. Et problem med en iterativ traversering i nivåorden ved hjelp av en kø er at vi ikke på samme måte som over kan få tak i det nivået vi til enhver tid er på. Det kan vi imidlertid løse ved å bruke en ekstra kø som holder orden på nivåene. Metoden vil få orden n:
public String nivåVerdier(int nivå) { if (nivå < 0 || nivå > høyde) throw new NoSuchElementException("Nivå " + nivå + " finnes ikke!"); Kø<Node<T>> nodekø = new TabellKø<>(); Kø<Integer> nivåkø = new TabellKø<>(); Liste<T> liste = new TabellListe<>(); nodekø.leggInn(rot); // legger inn roten nivåkø.leggInn(0); // roten er på nivå 0 while (!nodekø.tom()) { Node<T> p = nodekø.taUt(); // en node int nodenivå = nivåkø.taUt(); // nodens nivå if (nodenivå > nivå) break; if (nodenivå == nivå) liste.leggInn(p.verdi); if (p.venstre != null) { nodekø.leggInn(p.venstre); nivåkø.leggInn(nodenivå + 1); } if (p.høyre != null) { nodekø.leggInn(p.høyre); nivåkø.leggInn(nodenivå + 1); } } return liste.toString(); }