VIKTIG Programkode kan være selvforklarende hvis det er enkle algoritmer og en bruker standard kodeteknikk. Men hvis algoritmen eller koden som lages, er mer infløkt er det viktig med forklaringer. Det kan hende at en har en idé som ville ha virket, men som er kodet feil eller mangelfullt. Hvis en da ikke har forklaringer, kan det være vanskelig eller umulig å forstå det som er laget. Dermed risikerer en å få færre poeng (eller 0 poeng) enn det en ellers ville ha fått.
I oppgaver der det f.eks. spørres etter en utskrift, er det spesielt viktig med forklaringer. Hvis det en har satt opp som utskrift er feil, kan en risikere å få 0 poeng hvis forklaringer mangler. Det kan jo hende at en har tenkt riktig, men kun gjort noen småfeil. Men uten forklaringer er det ikke mulig å vite om det er småfeil eller om feilen skyldes at en har bommet fullstendig.
OBS: I oppgaveteksten står det at «De 10 bokstavpunktene teller likt, men hvis et bokstavpunkt er delt opp, kan en krevende del telle mer enn en enkel del». Nedenfor står det mer om hvor mye de ulike delene teller.
Oppgave 1A
Denne oppgaven har to punkter: i) og ii). Hensikten med punkt i)
er å gi en indikasjon på hvordan man kan bytte om to verdier i en kø. Det får man bruk for når ii) skal
kodes. Punkt i) er enklere enn punkt ii) og teller derfor litt mindre.
i)
- Etter innlegging: [Per, Kari, Elin, Ali]
- Per tas ut og legges bakerst: [Kari, Elin, Ali, Per]
- Kari tas ut og legges tilside: [Elin, Ali, Per]
- Elin tas ut og legges bakerst: [Ali, Per, Elin]
- Kari legges inn bakerst: [Ali, Per, Elin, Kari]
- Ali tas ut og legges bakerst: [Per, Elin, Kari, Ali]
Resultatet er at verdiene på indeks 1 og 2 har byttet plass og de to utskriftssetningene gir dette:
[Per, Kari, Elin, Ali] [Per, Elin, Kari, Ali]
En utskrift (toString()-metoden) fra en datastruktur har som standard (det gjelder alle
Java-klassene og alle de som har blitt laget i undervisningen og i obliger) at den er «innrammet» med
hakeparenteser, dvs. [ og ] og at verdiene skilles med komma og mellomrom. Mange studenter glemmer det. Det
er også mange som lar være å begrunne svaret. Det skal man normalt gjøre. Ikke bare her, men generelt i
alle oppgaver.
ii)
Her kommer først en løsning som ligner på det som ganske mange studenter har laget. Men den inneholder imidlertid to feil og en svakhet:
public static <T> void byttPlass(Kø<T> kø, int indeks) { if (indeks < 0 || indeks >= kø.antall() - 1) throw new IllegalArgumentException("Ulovlig indeks!"); for (int i = 0; i < kø.antall(); i++) { if (i == indeks) { T temp = kø.taUt(); kø.leggInn(kø.taUt()); kø.leggInn(temp); } else kø.leggInn(kø.taUt()); } }
Den som står bakerst i køen har ingen bak seg og dermed ingen å bytte plass
med. Derfor må det isteden stå: indeks >= kø.antall() - 1. Det er også noen som sjekker om køen har minst to
verdier. Det er ikke galt å gjøre det, men det er unødvendig. Hvis køen er tom eller har kun ett element, vil det
bli kastet et unntak uansett hva slags verdi indeks måtte ha. Den andre feilen er at når tilfellet:
i == indeks inntreffer, vil det tas ut to verdier fra køen. Dermed kommer for-løkkens i-variabel
i utakt. Det kan repareres ved å sette inn en i++ i blokken eller bruke
i < kø.antall() - 1 i for-løkken.
En skal generelt tenke seg om hvis en ønsker å bruke datastrukturens antall()-metode
(metoden size() i Java-klassene) i styringen av en løkke. Flg. eksempel viser hvilken bommert
man da kan risikere. Flere studenter har løst oppgaven ved å bruke en hjelpestruktur. De ønsker å flytte alle verdiene
fra køen over i f.eks. en liste eller en tabell, gjøre ombyttingen i listen (eller tabellen) og så flytte verdiene
tilbake. Mange har brukt kode
av flg. type for å flytte verdiene fra køen til f.eks. en liste:
ArrayList<T> liste = new ArrayList<>(); for (int i = 0; i < kø.antall(); i++) liste.add(kø.taUt());
Det man lett glemmer er at metoden antall() til enhver tid returnerer antallet som er igjen i køen. Hvis f.eks.
køen hadde 10 verdier fra starten av, så vil bare de 5 første bli flyttet over siden i øker med 1 og
antall() returnerer et tall som er 1 mindre enn sist i hver iterasjon. Når de 5 første har blitt
tatt ut, har i blitt lik 5. Men da er det også 5 verdier igjen og metoden antall() gir også 5.
Dermed stopper for-løkken.
Svakheten i koden øverst er at sammenligningen: i == indeks utføres hver gang, men den
blir sann kun én gang. Det er derfor bedre å bruke to separate for-løkker. Den første går frem til indeks
og den andre tar seg av resten. Dvs. slik:
public static <T> void byttPlass(Kø<T> kø, int indeks) { int n = kø.antall(); if (indeks < 0 || indeks >= n - 1) throw new IndexOutOfBoundsException("Ulovlig indeks!"); // tar ut og legger inn inntil vi kommer til rett indeks for (int i = 0; i < indeks; i++) kø.leggInn(kø.taUt()); T verdi = kø.taUt(); // tar ut verdi = kø(indeks) kø.leggInn(kø.taUt()); // tar ut og legger inn kø(indeks + 1); kø.leggInn(verdi); // legger inn verdi // tar ut og legger inn resten av køen for (int i = indeks + 2; i < n; i++) kø.leggInn(kø.taUt()); }
Et mulig alternativ som mange studenter har valgt, er å flytte alle verdiene fra køen over i annen datastruktur og så
gjøre ombyttingen der. Det vil gi litt trekk siden det står i oppgaveteksten at en vil få best score hvis en kun
bruker hjelpevariabler (dvs. ingen hjelpestrukturer). Her er et forslag der en tabell brukes som hjelpestruktur. Legg
merke til at problemet med å bruke antall()-metoden kan unngås ved å bruke en hjelpevariabel eller
eventuelt å bruke en løkke av typen: while(!kø.tom()):
public static <T> void byttPlass(Kø<T> kø, int indeks) { int n = kø.antall(); if (indeks < 0 || indeks >= n - 1) throw new IndexOutOfBoundsException("Ulovlig indeks!"); // flytter verdiene fra køen til en tabell T[] a = (T[]) new Object[n]; for (int i = 0; i < n; i++) a[i] = kø.taUt(); // bytter om de aktuelle verdiene T tempverdi = a[indeks]; a[indeks] = a[indeks + 1]; a[indeks + 1] = tempverdi; // flytter verdiene fra tabellen til køen for (T verdi : a) kø.leggInn(verdi); }
Oppgave 1B
i)
Husk at preorden er node - venstre - høyre
og at inorden er venstre - node - høyre:
preorden: E, H, F, A, B, I, C, G, D inorden: F, H, A, E, C, I, G, B, D
ii)
A er første verdi i preorden og hører til rotnoden. Vi finner A et stykke ut i rekkefølgen i inorden. Det betyr at alle verdiene til venstre for A i inorden hører til venstre subtre til A og alle verdiene til høyre hører til høyre subtre til A. Osv.
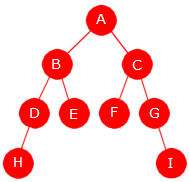 |
nivåorden: A, B, C, D, E, F, G, H, I
Det er forholdsvis enkelt å lage en rekursiv metode som bygger opp et binærtre ved hjelp av verdiene i preorden og inorden. Men det spørres det selvfølgelig ikke etter i oppgaven:
private static <T> Node<T> trePreorden(T[] preorden, int rot, T[] inorden, int v, int h) { if (v > h) return null; // tomt intervall -> tomt tre int k = v; T verdi = preorden[rot]; while (!verdi.equals(inorden[k])) k++; // finner verdi i inorden[v:h] Node<T> venstre = trePreorden(preorden, rot + 1, inorden, v, k - 1); Node<T> høyre = trePreorden(preorden, rot + 1 + k - v, inorden, k + 1, h); return new Node<>(verdi, venstre, høyre); } public static <T> BinTre<T> trePreorden(T[] preorden, T[] inorden) { BinTre<T> tre = new BinTre<>(); tre.rot = trePreorden(preorden, 0, inorden, 0, inorden.length - 1); tre.antall = preorden.length; return tre; }
Oppgave 2A
Her er det viktig å huske at første verdi i en liste har indeks 0, den neste indeks 1, osv. Dette er standard for
tabeller og alle andre sekvensielle datastrukturer (f.eks. lister). Det gjelder alle de ferdige Java-klassene og alle
de som har blitt laget i undervisningen (inklusiv DobbeltLenketListe som en skulle kode i Oblig 2).
Det er ingen unnskyldning for ikke å ha fått med seg dette. Metoden
public void leggInn(int indeks, T verdi) legger
verdi på plass indeks. Det betyr at den verdien som opprinnelige lå på
plass indeks, blir skjøvet (sammen med de som kommer etter)
en enhet mot høyre. Noen tror at verdi erstatter den på plass indeks.
Da har man misforstått (husk Oblig 2). Det er metoden oppdater() som erstatter. I Java-klassene
svarer dette til metodene add() og set().
- Innlegging av Erik og Kari: [Erik, Kari]
- Reidar på indeks 1: [Erik, Reidar, Kari]
- Jasmin på indeks 1: [Erik, Jasmin, Reidar, Kari]
- Verdi på indeks 2 (dvs. Reidar) fjernes: [Erik, Jasmin, Kari]
Listens innhold skrives ut:
[Erik, Jasmin, Kari] // første utskrift
Metodekallet liste.fjernHvis(navn -> navn.contains("i"));
fjerner alle forekomster som inneholder bokstaven i. Men siden alle navnene i listen inneholder en
i, blir listen tømt. Utskrift:
[] // andre utskrift
Også her gjelder kommentaren fra Oppgave 1A. Dvs. mange glemmer at utskriften fra en datstruktur er «innrammet» med hakeparenteser, dvs. [ og ] og at verdiene skilles med komma og mellomrom. Det er også mange som lar være å begrunne svaret. Det skal man normalt gjøre. Ikke bare her, men generelt i alle oppgaver. I denne oppgaven er det noen som får feil svar. Uten begrunnelse, er det umulig å finne ut hva feilen skyldes og dermed kan en risikere å få 0 poeng.
Oppgave 2B
I oppgaveteksten står det at «målet er å kode dette med så få ekstra ressurser som mulig». Det er mulig
og heller ikke vanskelig å lage kode uten hjelpestrukturer og likevel slik at metoden får orden n.
En løsning av denne typen kreves for å få full score:
public static int fjernDuplikater(int[] a) { if(a.length == 0) return 0; // ingen forskjellige verdier int j = 1; for (int i = 1; i < a.length; i++) { // hvis a[i - 1] == a[i], tas ikke a[i] med if (a[i - 1] != a[i]) a[j++] = a[i]; } // nuller resten av tabellen for (int i = j; i < a.length; i++) a[i] = 0; return j; // antall forskjellige verdier }
Det var kun få studenter som løste det slik som over. Når det i tabellen kommer to like verdier, hadde mange det som idé å fjerne den andre ved å forskyve resten av verdiene (de til høyre) en enhet mot venstre. Det er mulig, men da må en passe nøye på at indeksene ikke går utenfor tabellen, dvs. at det ikke kommer en ArrayIndexOutOfBoundsException. Det problemet dukket opp hos ganske mange. Det var også mange som fikk feil svar når det var tre like. Ulempen med idéen er at hvis tabellen har mange like verdier, vil metoden bli av kvadratisk orden og det er uheldig. Dette kan f.eks. kodes slik:
public static int fjernDuplikater(int[] a) { if(a.length == 0) return 0; // ingen forskjellige verdier int n = a.length; // n er foreløpig antall forskjellige for (int i = 1; i < n; ) { if (a[i - 1] == a[i]) // to like verdier { n--; // antall forskjellige reduseres // fjerner a[i] ved å forskyve mot venstre for (int j = i; j < n; j++) a[j] = a[j + 1]; a[n] = 0; // nuller på slutten } else i++; // fortsetter } return n; }
En annen løsningsteknikk som også mange forsøker seg på, har som første skritt å nulle alle duplikatene. Hvis
vi tar tabellen {1, 3, 5, 5, 6, 8, 8, 8, 9, 10, 10} som utgangspunkt, vil det f.eks. føre til tabellen
{1, 3, 0, 5, 6, 0, 0, 8, 9, 0, 10}. Deretter sorteres tabellen med f.eks. metoden sort
fra klassen Arrays: {0, 0, 0, 0, 1, 3, 5, 6, 8, 9, 10}. Men så er det mange som har problemer med
å få verdiene forrest og nullene bakerst. Der er det flere fantasifulle løsningsforslag der noen virker og noen
ikke virker. Men det som trengs er å rotere innholdet av tabellen mot venstre (en
av oppgavene i Oblig 1). I eksemplet vil det si 4 enheter mot venstre. Her kan det gjøres enkelt siden
det er nuller. Sammenlagt vil dette gi en metode av orden n log(n). Det er ikke fullt så bra som
orden n, men vesentlig bedre enn orden n2 :
public static int fjernDuplikater(int[] a) { if (a.length == 0) return 0; // ingen forskjellige verdier int duplikater = 0; for (int i = 0; i < a.length - 1; i++) { if (a[i] == a[i + 1]) // går bra siden i < a.length - 1 { a[i] = 0; // nuller duplikater duplikater++; // teller opp } } if (duplikater == 0) return a.length; // alle er forskjellige Arrays.sort(a); // sorterer for (int i = duplikater; i < a.length; i++) { a[i - duplikater] = a[i]; // forskyver mot venstre } for (int i = a.length - duplikater; i < a.length; i++) { a[i] = 0; // nullene bakerst } return a.length - duplikater; // antall forskjellige }
En annen løsningsteknikk som også mange har valgt, er å kopiere de unike verdiene over i en hjelpetabell. Det blir en
metode av orden n, men med ulempen at det brukes ekstra plass:
public static int fjernDuplikater(int[] a) { if(a.length == 0) return 0; // ingen forskjellige verdier int[] b = new int[a.length]; // hjelpetabell int j = 0; // indeks i hjelpetabellen b[j++] = a[0]; // den først må være med for (int i = 1; i < a.length; i++) { if (a[i - 1] != a[i]) b[j++] = a[i]; // kopierer inn i b og øker j } // Må kopiere tilbake. Det virker ikke med a = b og heller ikke med // a = Arrays.copyOf(b, b.length). Husk at a her er en lokal variabel! System.arraycopy(b, 0, a, 0, a.length); return j; }
Det er mange som tror at en setning som: a = b; eller: a = Arrays.copyOf(b, b.length) i metoden over, vil gjøre at a får innholdet til b.
Men det virker ikke! Variabelen a er en lokal variabel i metoden og en oppdatering av den har kun lokal effekt.
Men det som a peker til, ligger utenfor metoden og det kan endres fra metoden.
Oppgaven kan løses på mange ulike måter. En litt uortodoks måte som krever en del ekstra ressurser, er å kopiere
tabellverdiene
over i en datastruktur som ikke tillater duplikater, f.eks. en TreeSet:
public static int fjernDuplikater(int[] a) { if(a.length == 0) return 0; // ingen forskjellige verdier Set<Integer> set = new TreeSet<>(); // en TreeSet for (int k : a) set.add(k); // legger inn int i = 0; for (int k : set) a[i++] = k; // henter tilbake for (; i < a.length; i++) a[i] = 0; // nuller resten return set.size(); // antall forskjellige }
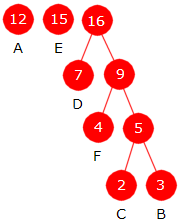
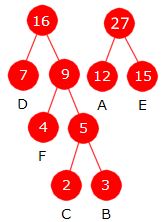
Oppgave 3A
i)
| Bokstav | A | B | C | D | E | F |
| Frekvens | 12 | 3 | 2 | 7 | 15 | 4 |
ii)
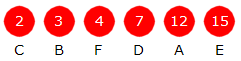 |
 |
 |
 |
 |
 |
| Huffmantreet |
iii)
| Bokstav | A | B | C | D | E | F |
| Bitkode | 10 | 0111 | 0110 | 00 | 11 | 010 |
Bitsum = 12·2 + 3·4 + 2·4 + 7·2 + 15·2 + 4·3 = 100
Dekomprimering: 011001111010 -> CBAA
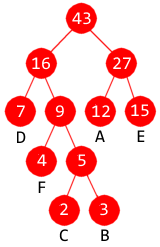
Oppgave 3B
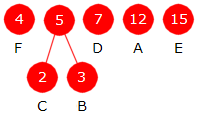
Oppgaven har to punkter: i) og ii). Hensikten med i)
er å gi en indikasjon på hvordan metoden i ii) skal kodes. Punkt
i) er mye enklere enn ii) og teller derfor en god del mindre.
i)
 |
| Huffmantre |
ii)
Det står i oppgavteksten at en kan ta som gitt at tabellen bitkoder kommer fra et Huffmantre.
Det betyr at den ikke kan være null eller tom. Hver tegnstreng representerer et tegn. Det betyr
at for en i kan
bitkoder[i] være null. Det betyr bare at tegnet (char)i ikke
inngår i «meldingen». Dette må en derfor sjekke.
Videre står det at hver tegnstreng i bitkoder
inneholder tegnene '0' eller '1'. Dermed er det ikke nødvendig å teste om tegnet er '1' hvis det ikke er '0'.
Det er mange som sjekker hvilket tegn det er med kode som dette:
if (bitkode.charAt(j) == 0). Det er syntaksmessig ok kode og programmet
blir kjørbart. Men resutatet blir helt galt. Det gir true kun hvis tegnet har 0 som ascii-verdi. Dvs.
det tegnet som ligger aller først. Men det er noe helt annet enn tegnet '0'. Det har ascii-verdi lik 48. Feilen ser
uskyldig ut, men er alvorlig. Koden er kjørbar, men gir feil resultat. Klassen
Huffman er ikke generisk. Derfor må det stå:
Node p = rot; og ikke
Node<T> p = rot;
public Huffman(String[] bitkoder) { rot = new Node(); // oppretter rotnoden for (int i = 0; i < bitkoder.length; i++) // går gjennom tabellen { String bitkode = bitkoder[i]; // hjelpevariabel if (bitkode != null) // eksisterer bitkode? { Node p = rot; // p starter i roten for (int j = 0; j < bitkode.length(); j++) { if (bitkode.charAt(j) == '0') // går til venstre { if (p.venstre == null) p.venstre = new Node(); p = p.venstre; } else // går til høyre { if (p.høyre == null) p.høyre = new Node(); p = p.høyre; } } p.tegn = (char)i; // legger inn tegnet } } }
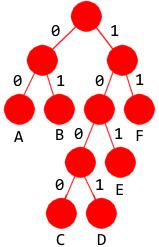
Oppgave 4A
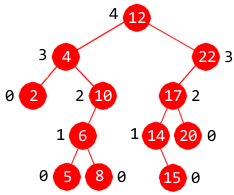 |
| Figur 1: Binært søketre |
Oppgave 4B
Dette kan løses på mange måter, men den enkleste og mest effektive er
å starte med å finne den første noden p i inorden og på veien dit bruke en
hjelpepeker som ligger ett nivå høyere. Deretter behandles de
to tilfellene 1) at p har et ikke-tomt høyre subtre og 2) at p har et tomt høyre subtre:
public T nestMinst() { if (antall() < 2) throw new NoSuchElementException("Må ha minst to verdier!"); Node<T> p = rot, q = null; // starter med å flytte p til den første noden i inorden // der q er forelderen til p while (p.venstre != null) { q = p; // oppdaterer q p = p.venstre; // flytter p } if (p.høyre != null) // har p et høyre subtre? { p = p.høyre; // går til høyre og while (p.venstre != null) p = p.venstre; // så videre mot venstre return p.verdi; // p er den andre i inorden } else // hvis p ikke har et høyre { // subtre, så er forelderen return q.verdi; // q den andre i inorden } }
En liten «advarsel»: De fleste har som idé at de skal finne den første i inorden og blant dem er det mange som lager kode av flg. type:
while (p != null) { if (p.venstre != null) { q = p; p = p.venstre; } }
Men koden over gir «evig løkke». Når p har kommet til den første i inorden,
vil p.venstre være null. Men p er ikke null.
Dermed er det ikke mulig å komme ut av while-løkken.
Hvis man ikke klarer å få det til som det øverst, kan en som nødløsning traversere treet i inorden, legge verdiene
over i en datastrukur og så hente ut den andre verdien. En vil kunne få noen poeng for det selv om hele treet traverseres.
Men hvis en avskjærer den rekursive traverseringen når det er lagt inn to verdier, så er det nesten som fullgodt. Svakheten
er imidlertid at en bruker ekstra plass og hvis treet er svær stort og svært skjevt (lang vei ned til de to nodene), vil programstakken bli stor og i verste
fall gi StackOverflowError. Dette kan f.eks. kodes slik:
private static <T> void inorden(Node<T> p, Stakk<T> stakk) { if (p.venstre != null) inorden(p.venstre, stakk); if (stakk.antall() < 2) stakk.leggInn(p.verdi); else return; if (p.høyre != null) inorden(p.høyre, stakk); } public T nestMinst() { if (antall() < 2) throw new NoSuchElementException("Må ha minst to verdier!"); Stakk<T> stakk = new TabellStakk<>(); inorden(rot, stakk); return stakk.kikk(); // den andre i inorden }
Oppgave 4C
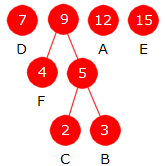
Denne oppgaven har to punkter: i) og ii). Hensikten med punkt i)
er å gi en indikasjon på hvordan høydeoppdateringsdelen av metoden i punkt ii) skal kodes. Punkt
i) er ganske enkel sammenlignet med punkt ii) og teller derfor kun et par poeng.
i)
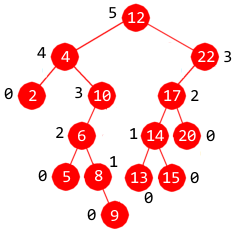 |
| Figur 2: Binært søketre |
ii)
Kodingen kan deles i to. Første del går ut på å legge verdi inn på rett sortert plass
i treet og så oppdatere antallet. Dette er en standardalgoritme. Den er grundig forklart i undervisningen og
var også tema i Oblig 3. Den er fundamental når det gjelder binære søketrær. Den kan kodes på
flere måter. Mange glemmer å ta hensyn til at treet kan være tomt før en innlegging og at variabelen
antall alltid må oppdateres. Hvis ikke, vil ikke metodene antall()
og tom() virke.
Mange glemmer også at det er en T er en generisk type. Derfor må sammenligningene utføres ved
hjelp av komparatoren.
Den andre delen av kodingen handler om nye ting. Det er mange som velger å oppdatere høyden i hver node
på veien nedover til der den nye noden skal inn. I punkt i) skulle man sette inn
9 på rett sortert plass og så oppdatere høyden i de nodene som får endret sin høyde. Da stemmer det at
alle nodene i den tilhørende grenen får økt sin høyde. Men det stemmer ikke i tilfellet der 13 skal
legges inn. Da er det ingen endring i nodenes høyde. Det betyr at det generelt blir helt galt alltid å oppdatere
høydene på veien nedover. Faktisk er det generelt svært sjelden at alle nodene i grenen (og dermed rotnoden)
får ny høyde. Det skjer
kun når den nye noden legges inn som barn til en node som ligger på nederste nivå i treet. Det betyr at
i treet i Figur 2 ovenfor er det kun når noden med verdi 9 får et barn at alle nodene i grenen
(og dermed hele treet) får ny høyde.
Noen tenker seg at de to tilfellene i punkt i) (innlegging av 9 og 13) er de eneste
mulige. Med andre ord at enten vil alle nodene i grenen få ny høyde eller ingen av nodene. Men så enkelt
er det ikke. De to tilfellene er ytterpunkter. Det ene ytterpunktet vil som nevnt over, generelt inntreffe
svært sjelden. Det andre ytterpunktet (ingen høydeoppdateringer) inntreffer i gjennomsnitt for hver tredje
innlegging. Det betyr at det ved to av tre innlegginger blir høydeendringer. Men hvor mange noder som i
så fall påvirkes, vil variere. Ta som eksempel at 1 skal legges inn i treet fra Figur 2. Noden blir
da venstre barn til noden med verdi 2. Den noden får økt sin høyde, men ikke dens forelder (noden med verdi 4).
Det enkleste er å starte en eventuell høydeoppdatering fra bunnen av:
La p være den nye noden. Da
sammenlignes høyden til p med høyden til p sin forelder.
Hvis de er like, økes høyden til forelderen. Så flytter vi p oppover og gjentar
sammenligningen. Dette stopper når høydene er ulike (eller at vi har nådd roten).
Problemet med å gjøre høydeoppdateringene fra bunnen av er at en da må kunne gå oppover i treet. Den enkleste måten å løse det på er å legge alle nodene som passeres på veien nedover, på en stakk. Dermed kan en gå oppover ved å ta noder fra stakken:
public boolean leggInn(T verdi) { Objects.requireNonNull(verdi,"Ikke tillatt med null-verdier!"); Stakk<Node<T>> stakk = new TabellStakk<>(); Node<T> p = rot; int cmp = 0; // legger de nodene som vi passerer på veien nedover, på stakken while (p != null) { stakk.leggInn(p); cmp = comp.compare(verdi, p.verdi); p = cmp < 0 ? p.venstre : p.høyre; } p = new Node<>(verdi); // oppretter en ny node if (tom()) rot = p; // p blir rotnode else { Node<T> q = stakk.taUt(); // q er den siste noden vi passerte if (cmp < 0) q.venstre = p; // venstre barn til q else q.høyre = p; // høyre barn til q // Nå er q forelder til p. Hvis de har lik høyde, må høyden // til q økes siden høyden til en forelder alltid er større // en høyden til et barn. Dette gjentas oppover i grenen mot // roten. Det stopper hvis p og dens forelder q har ulik høyde. while (q.høyde == p.høyde) // stopper når de har ulik høyde { q.høyde++; // øker med 1 p = q; // setter p lik sin forelder if (stakk.tom()) break; // ferdig else q = stakk.taUt(); // går oppover } } antall++; // en ny verdi i treet return true; // vellykket innlegging }
Det er også mulig å gjøre eventuelle høydeoppdateringer fra roten og nedover hvis vi vet avstanden fra roten ned til den nye noden. Hvis den avstanden er større enn rotens høyde, må rotens høyde økes. Deretter går vi et hakk ned. Da vil avstanden mellom den noden og den nye være en mindre. Da sammenligner vi igjen og øker høyden om nødvendig. Vi finner avstanden fra roten ned til den nye noden når vi går nedover første gang:
public boolean leggInn(T verdi) { Objects.requireNonNull(verdi,"Ikke tillatt med null-verdier!"); Node<T> p = rot, q = null; // hjelpepekere int cmp = 0; // for sammenligninger int avstand = 0; // avstand opp til roten while (p != null) { q = p; // q blir forelder til p avstand++; // øker avstanden cmp = comp.compare(verdi, p.verdi); // sammenligner p = cmp < 0 ? p.venstre : p.høyre; // flytter p } p = new Node<>(verdi); // en ny node if (tom()) // er treet tomt? { rot = p; // roten opprettes } else { if (cmp < 0) q.venstre = p; // p blir venstre barn til q else q.høyre = p; // p blir høyre barn til q if (q.høyde == 0) // høydeoppdateringer trengs { Node<T> r = rot; // starter på nytt i roten while (r != p) // fortsetter ned til p { if (r.høyde < avstand) r.høyde++; // høyden til r økes avstand--; // reduserer avstanden if (comp.compare(verdi,r.verdi) < 0) r = r.venstre; // går til venstre else r = r.høyre; // går til høyre } // while } // if } // else antall++; // en ny verdi i treet return true; // vellykket innlegging }
Det er også mulig å løse dette rekursivt. Det gir kortest kode. Da vil vi gå oppover i treet når rekursjonen
«trekker seg tilbake». Vi lager en privat metode som gjør rekursjonen. Den har
to nodepekere p oq q (q er
forelder til p) som argumenter.
private void leggInn(Node<T> p, Node<T> q, T verdi) { if (p == null) { if (comp.compare(verdi, q.verdi) < 0) p = q.venstre = new Node<>(verdi); else p = q.høyre = new Node<>(verdi); } else if (comp.compare(verdi, p.verdi) < 0) leggInn(p.venstre, p, verdi); else leggInn(p.høyre, p, verdi); if (p != rot && p.høyde == q.høyde) q.høyde++; } public boolean leggInn(T verdi) { Objects.requireNonNull(verdi,"Ikke tillatt med null-verdier!"); if (tom()) rot = new Node<>(verdi); else leggInn(rot, null, verdi); antall++; return true; }
Oppgave 4D
Kodingen kan deles i to. Første del går ut på å finne noden p som inneholder
verdi. Det er en standardalgoritme for det og den er fundamental for binære søketrær.
Den finner verdien eller eventuelt avgjør at den ikke finnes.
Men her er det nødvendig å lete videre siden oppgaven sier at hvis verdi finnes flere ganger,
skal metoden returnere null. Hvis p er den første (fra roten)
noden som inneholder verdi, så må eventuelle duplikater ligge i p
sitt høyre subtre. Da holder det å gå til den som følger etter p i inorden. Hvis den
ikke inneholder verdi, så er det ingen duplikater. Dette blir derfor delvis det samme
som i 4B.
Andre del inneholder nye ting. La p være noden som inneholder
verdi. Oppgaven går ut på å finne en node i subtreet (subtreet med p
som rotnode) som har avstand d opp til p. Hvis
det skal være mulig, må subtreet være høyt nok. Dvs. at p.høyde må være minst
så stor som d. Hvis det er oppfylt, må vi
gå videre til et av subtrærne til p. Hvis høyre subtre eksisterer og er høyt nok, går vi dit.
Ellers (dvs. høyre subtre er tomt eller er ikke høyt nok) går vi til venstre subtre. Det betyr
spesielt at hvis begge subtrærne til p eksisterer og er høye nok, vil vi gå til høyre.
Det blir riktig selv om det i det tilfellet er noder i begge subtrærne som oppfyller kravet. Men oppgaven
sier at den som har størst verdi skal velges. Verdier i høyre subtre er alltid større enn verdier i venstre subtre.
public T avstand(T verdi, int d) { Objects.requireNonNull(verdi,"Ingen null-verdier!"); if (d < 0) throw new IllegalArgumentException("Negativ avstand!"); Node<T> p = rot; // starter i roten while (p != null) { int cmp = comp.compare(verdi, p.verdi); // sammenligner if (cmp < 0) p = p.venstre; // går til venstre else if (cmp > 0) p = p.høyre; // går til høyre else break; // verdi ligger i p } if (p == null) return null; // verdi ligger ikke i treet // verdi ligger i p, eventuelle duplikater må ligge til høyre if (p.høyre != null) { Node<T> q = p.høyre; while (q.venstre != null) q = q.venstre; if (comp.compare(verdi, q.verdi) == 0) return null; // et duplikat } // Det er nå kun en forekomst av verdi og den ligger i p. // Hvis høyden til p er mindre enn d, kan vi gi opp if (p.høyde < d) return null; // Subtreet med p som rotnode har nå minst en node med avstand d // opp til p. Hvis det høyre subtreet er høyt nok, går vi dit. // Hvis ikke, går vi til det venstre subtreet. Osv. while (d-- > 0) { p = p.høyre != null && d <= p.høyre.høyde ? p.høyre : p.venstre; } return p.verdi; }
En annen, men mer ineffektiv teknikk er å ta utgangspunkt i noden p som inneholder verdi
og så gjøre en traversering i subtreet med p som rotnode. Hvis vi under traverseringen hele tiden
vet hvor langt ned i treet vi er, så vil det fungere.
Vi kan bruke en dybde-først traversering.
Da spiller det ingen rolle om det er pre-, in- eller postorden. Hvis vi har to noder p og
q på samme nivå og p ligger til venstre
for q, så kommer vi uansett til p før vi kommer til q.
Vi tar vare på hver nodeverdi på nivå d. Den siste av dem er den vi
leter etter. Den rekursive metoden nedenfor går ikke lenger ned i treet enn nødvendig:
// rekursiv hjelpemetode private static <T> void traverser(Node<T> p, int d, Stakk<T> stakk) { if (d == 0) stakk.leggInn(p.verdi); else if (d > 0) { if (p.venstre != null) traverser(p.venstre, d - 1, stakk); if (p.høyre != null) traverser(p.høyre, d - 1, stakk); } } public T avstand(T verdi, int d) { Objects.requireNonNull(verdi,"Ingen null-verdier!"); if (d < 0) throw new IllegalArgumentException("Negativ avstand!"); Node<T> p = rot; // starter i roten while (p != null) { int cmp = comp.compare(verdi, p.verdi); // sammenligner if (cmp < 0) p = p.venstre; // går til venstre else if (cmp > 0) p = p.høyre; // går til høyre else break; // verdi ligger i p } if (p == null) return null; // verdi ligger ikke i treet // verdi ligger i p, eventuelle duplikater må ligge til høyre if (p.høyre != null) { Node<T> q = p.høyre; while (q.venstre != null) q = q.venstre; if (comp.compare(verdi, q.verdi) == 0) return null; // et duplikat } // Det er nå kun en forekomst av verdi og den ligger i p. // Hvis høyden til p er mindre enn d, kan vi gi opp if (p.høyde < d) return null; Stakk<T> stakk = new TabellStakk<>(); // en hjelpestakk traverser(p, d, stakk); // traverserer return stakk.kikk(); // returnerer toppen av stakken }