VIKTIG Programkode kan være selvforklarende hvis det er enkle algoritmer og en bruker standard kodeteknikk. Men hvis algoritmen eller koden som lages, er mer infløkt, er det viktig med forklaringer. Det kan hende at en har en idé som ville ha virket, men som er kodet feil eller mangelfullt. Hvis en da ikke har forklaringer, kan det være vanskelig eller umulig å forstå det som er laget. Dermed risikerer en å få færre poeng (eller 0 poeng) enn de en ellers ville ha fått.
I oppgaver der det f.eks. spørres etter en utskrift, er det spesielt viktig med forklaringer. Hvis det en har satt opp som utskrift er feil, kan en risikere å få 0 poeng hvis forklaringer mangler. Det kan jo hende at en har tenkt riktig, men kun gjort noen småfeil. Men uten forklaringer er det ikke mulig å vite om det er småfeil eller om feilen skyldes at en har bommet fullstendig.
Oppgave 1A
Legg merke til at utskriftssetningen
System.out.println(Arrays.toString(a)) ligger inne i for-løkken
for (int i = 0; i < a.length - 1; i++). Det betyr at den
utføres 4 ganger når a.length
er 5. Det blir flg. utskrift:
[1, 4, 2, 5, 3] [1, 2, 4, 5, 3] [1, 2, 3, 5, 4] [1, 2, 3, 4, 5]
De som kun setter opp [1, 2, 3, 4, 5] som utskrift, vil få en del trekk.
Sammenligningen if (c.compare(a[j], mverdi) < 0) utføres inne i en for-løkke
som går fra i + 1 til a.length. I programkjøringen er
a.length lik 5. Første gang er i = 0 og dermed
i + 1 = 1. Dermed utføres
sammenligningen 4 ganger. Neste gang er i = 1. Da blir det 3 ganger. Osv.
Siste gang utføres den én gang. Tilsammen 4 + 3 + 2 + 1 = 10 ganger.
Hvis a har lengde n vil sammenligningen
bli utført (n - 1) + (n - 2) + · · · +
2 + 1 = n(n - 1)/2 ganger.
Den dominerende operasjonen er sammenligningen if (c.compare(a[j], mverdi) < 0).
Den utføres n(n - 1)/2 ganger uavhengig av hva slags verdier
a har. Det betyr at
algoritmen har kvadratisk orden eller orden n2 i det beste tilfellet, i det
verste tilfellet og gjennomsnittlig. Algoritmen kalles
utvalgssortering (eng: selection sort).
Oppgave 1B
1. Utskriften blir: [7, 4, 9, 1, 6, 0, 3, 8, 5, 2]. Dette er den lette delen av oppgaven. Derfor teller
den mindre enn neste del.
2. Obs: I oppgaveteksten står det ingenting om hvor lang parametertabellen c er
eller om hva slags verdier den kan inneholde. Den er ment å være en generell char-tabell og kan derfor
også inneholde like verdier. Men siden dette ikke står presisert i oppgaveteksten, vil det ikke bli noe
trekk for de som «glemmer» duplikat-problemet. Noen tar det som gitt
at c kun inneholder store bokstaver, men det er en for stor forenkling.
Det å finne en indeks-tabell for en vilkårlig tabell, er i prinsippet likeverdig med en sortering. Hvis vi har en slik indeks-tabell, kan vi få ut tabellens verdier sortert. Se på flg. eksempel:
char[] c = {'F','D','J','G','B','I','E','A','H','C'}; int[] indeks = {7, 4, 9, 1, 6, 0, 3, 8, 5, 2}; for (int i = 0; i < c.length; i++) { System.out.print(c[indeks[i]] + " "); } // Utskrift: A B C D E F G H I J
Det betyr at det generelt ikke er mulig å finne en algoritme med orden bedre enn
n log(n) for dette problemet.
a) En mulig teknikk er å lage en kopi d av parametertabellen
c og så sortere d. I tillegg trenger vi en «tom» int-tabell som er
like lang som c. Den kan f.eks. hete indeks.
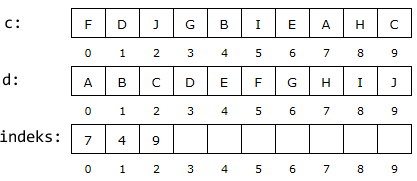 |
Den logisk sett enkleste idéen er å ta verdier fortløpende fra den sorterte tabellen d
og så finne ut hvilke posisjoner de har i den originale tabellen c. Den
første verdien (posisjon 0) i d er A. Vi ser at den ligger
i posisjon 7 i c. Dermed skal indeks[0] være lik 7. Den
neste verdien (posisjon 1) i d er B. Den ligger i
posisjon 4 i c. Det betyr at indeks[1] må være lik 4. Osv.
Se tabellene over. Obs: Denne idéen virker kun hvis verdiene i c er forskjellige.
For å få en mest mulig oversiktlig kode kan vi først lage en metode som finner posisjonen til en verdi i en char-tabell:
public static int finn(char[] c, char verdi) { for (int i = 0; i < c.length; i++) if (verdi == c[i]) return i; // verdi funnet return -1; // verdi ikke funnet }
Ved å bruke denne hjelpemetoden får vi flg. enkle kode for metoden indeksTabell:
public static int[] indeksTabell(char[] c) { char[] d = c.clone(); // d blir en kopi av c int[] indeks = new int[c.length]; // indekstabellen Arrays.sort(d); // sorterer d for (int i = 0; i < d.length; i++) indeks[i] = finn(c, d[i]); return indeks; }
Metoden over blir av orden n2 siden hjelpemetoden finn i gjennomsnitt må
lete gjennom halvparten av tabellen c.
b) Vi kan få en vesentlig mer effektiv metode ved å snu på
idéen over. Vi kan ta verdier fortløpende fra den originale (usorterte) tabellen c
og så finne ut hvilke posisjoner de har i den sorterte tabellen d. Se tabellene under:
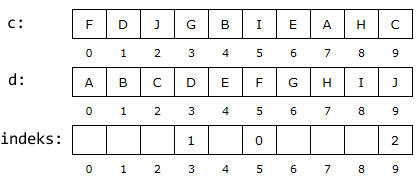 |
Den første verdien (posisjon 0) i c er F. Vi ser at den ligger
i posisjon 5 i d. Dermed skal indeks[5] være lik 0. Den
neste verdien (posisjon 1) i c er D. Den ligger i
posisjon 3 i d. Det betyr at indeks[3] må være lik 1. Osv.
Det fine med dette er at siden tabellen d er sortert, kan vi lete
ved hjelp av binærsøk. Bruker vi binærsøk fra klassen Arrays, får vi flg kode:
public static int[] indeksTabell(char[] c) { char[] d = c.clone(); // d blir en kopi av c int[] indeks = new int[c.length]; // indekstabellen Arrays.sort(d); // sorterer d for (int i = 0; i < c.length; i++) { indeks[Arrays.binarySearch(d, c[i])] = i; } return indeks; }
Metoden over virker heller ikke for en tabell med duplikater. Men den er vesentlig mer effektiv enn den første. Metoden
sort fra klassen Arrays bruker kvikksortering og er dermed av orden
n log(n). Letingen er også
av orden n log(n) siden det brukes binærsøk. Tilsammen
blir det en metode av orden n log(n).
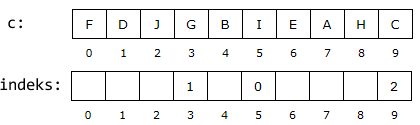
c) Det er mulig å lage indekstabellen uten å bruke en hjelpetabell. Vi kan for hver verdi c[i]
telle opp hvor mange verdier fra tabellen c som er mindre enn c[i].
La oss si at antallet er m. Det betyr at c[i] ville ha havnet i
posisjon m i en sortering av c. Dermed blir indeks[m] = i.
Ta f.eks. bokstaven F i tabellen under. Den ligger i posisjon 0. Vi ser at det er fem bokstaver i
c (dvs. A, B, C, D og E) som kommer foran F.
Dermed ville F ha fått posisjon 5 i en sortering. Dermed indeks[5] = 0.
Videre har vi c[1] = D. Det er
tre bokstaver som kommer foran D. Dermed indeks[3] = 1. Osv.
 |
Idéen over er enkel å kode. Men den blir mindre effektiv enn de over siden vi må gjennom hele tabellen
c på nytt hver gang. Metoden er også avhengig av at c ikke har duplikater.
public static int[] indeksTabell(char[] c) { int[] indeks = new int[c.length]; for (int i = 0; i < c.length; i++) { char d = c[i]; int m = 0; // antallet verdier som er mindre enn d for (int j = 0; j < c.length; j++) { if (c[j] < d) m++; } indeks[m] = i; } return indeks; }
d) Vi kan løse dette ved å sortere indeks-tabellen. Da starter vi med en
indeks-tabell som innholder tallene 0, 1, 2, 3, . . .
Formelt sorterer vi c, men ombyttingene gjøres i indeks. For å få en løsning
som er minst så effektiv som den beste av de over,
må vi bruke en sorteringsteknikk av orden n log(n).
Men for å illustrere hvordan det virker, nøyer vi oss her med å bruke utvalgssortering siden den
er så enkel å kode.
Obs: Dette vil virke for alle tabeller (også for de med duplikater):
public static void bytt(int[] indeks, int i, int j) // hjelpemetode { int tmp = indeks[i]; indeks[i] = indeks[j]; indeks[j] = tmp; } public static int[] indeksTabell(char[] c) { int n = c.length; // tabellens lengde int[] indeks = new int[n]; // oppretter indeks-tabellen for (int i = 0; i < n; i++) indeks[i] = i; // fyller tabellen med verdier for (int i = 0; i < n - 1; i++) { int k = i; for (int j = i + 1; j < n; j++) { if(c[indeks[j]] < c[indeks[k]]) k = j; // sammenligner } bytt(indeks, i, k); // bytter om i indeks-tabellen } return indeks; }
Oppgave 1C
I oppgaveteksten står det: Husk at et turneringstre er et komplett binærtre med like mange bladnoder som det er «deltagere». Begrepet komplett binærtre er svært viktig i vårt fag og det er essensielt at en vet hva det er. Det blir derfor trukket mye hvis treet som tegnes i denne oppgaven er noe annet enn det.
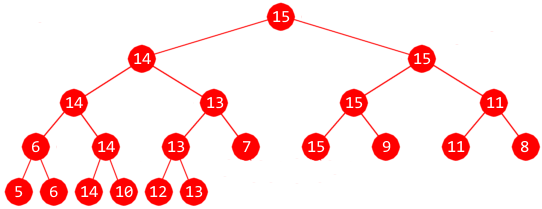 |
| Turneringstreet |
Det er ingen regel om hvordan «deltagerne» skal plasseres i treets bladnoder. Men hvis vi tenker på at treet også kan ses på som en tabell med indekser fra 1 til 21, er det kanskje mest naturlig å legge inn de gitte tallene 7, 15, 9, 11, 8, 5, 6, 14, 10, 12, 13 bakerst i «tabellen». Dermed blir det slik som tegningen over viser.
Det spørres ikke om det i oppgaven, men for sammenligningens skyld setter vi opp turneringestreet implementert som en tabell:
 |
| Turneringstreet som en tabell |
«Vinneren» 15 «slo ut» tallene 14, 11 og 9.
Et turneringstre med n deltagere vil få 2n − 1 noder.
Oppgave 2A
Bokstavene N, I, L og E
blir lagt inn i en kø. Bokstavene blir så tatt fra køen og flyttet
over til en stakk. Da vil N havne nederst, I nest nederst, osv. Så flyttes bokstavene fra
stakken tilbake til køen. Da tas E ut først siden den ligger på toppen av stakken. Den kommer da først
i køen. Deretter tas L, I og N ut fra stakken og
legges i køen. Da vil køene inneholde E, L, I og N.
Når så køen tømmes og bokstavene skrives ut, vil utskriften bli: E L I N.
Oppgave 2B
public T kikk() { if (tom()) throw new NoSuchElementException("Køen er tom!"); return fra.verdi; // returnerer verdien } public T taUt() { if (tom()) throw new NoSuchElementException("Køen er tom!"); T tempverdi = fra.verdi; // tar vare på verdien i fra fra.verdi = null; // nuller innholdet i fra fra = fra.neste; // flytter fra antall--; // reduserer antallet return tempverdi; // returnerer verdien } public String toString() { StringJoiner s = new StringJoiner(", ", "[", "]"); for (Node<T> p = fra; p != til; p = p.neste) { s.add(p.verdi.toString()); } return s.toString(); }
Oppgave 2C
public LenketKø() // konstruktør { til = fra = new Node<>(null); // lager den første noden Node<T> p = fra; for (int i = 1; i < 8; i++) p = new Node<>(p); // lager en kjede av noder fra.neste = p; // for å få en sirkel antall = 0; // ingen verdier foreløpig } public void leggInn(T verdi) { til.verdi = verdi; // legger inn bakerst if (til.neste == fra) // køen vil bli full - må utvides { til.neste = new Node<>(fra); // ny node mellom til og fra } til = til.neste; // flytter til antall++; // en ny verdi i køen }
Oppgave 3A
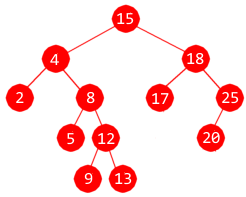 |
Preorden: 15, 4, 2, 8, 5, 12, 9, 13, 18, 17, 25, 20
Inorden: 2, 4, 5, 8, 9, 12, 13, 15, 17, 18, 20, 25
Postorden: 2, 5, 9, 13, 12, 8, 4, 17, 20, 25, 18, 15
Oppgave 3B
Hensikten med et binært søketre er at søking skal kunne gjøres på en effektiv måte. Trestrukturen er laget for det formålet og i et gjennomsnittlig binært søketre vil standardalgoritmen for søking være av logaritmisk orden. Noen velger å søke ved å traversere treet i en eller annen rekkefølge. Men det vil bli en algoritme av orden n og blir helt unødvendig ineffektivt her. De som likevel har gjort det i sin besvarelse, vil få en del trekk.
public boolean inneholder(T verdi) { if (verdi == null) return false; Node<T> p = rot; while (p != null) { int cmp = comp.compare(verdi, p.verdi); if (cmp > 0) p = p.høyre; else if (cmp < 0) p = p.venstre; else return true; } return false; }
Oppgave 3C
Klassen SBinTre i vedlegget har metoden
public void preorden(Oppgave<? super T> oppgave).
Den traverserer treet i preorden. Da er det bare å snu de verdiene den gir oss. Det kan vi gjøre ved å bruke en stakk og et lambda-uttrykk:
public String omvendtPreString() { Stakk<T> s = new TabellStakk<>(); preorden(x -> s.leggInn(x)); return s.toString(); }
Obs: Omvendt preorden er ikke det samme som «node - høyre - venstre». Den første i omvendt preorden er
(som også eksemplet i oppgavteksten viser) lik den siste i preorden. Den andre i omvendt preorden
er lik den nest siste i preorden, osv. Med andre ord motsatt rekkefølge av preorden.
Rekkefølgen «node - høyre - venstre» heter
speilvendt preorden, dvs. preorden i det speilvendte treet. For å få omvendt preorden må vi gå fra
«node - venstre - høyre» til det omvendte, dvs. til «høyre - venstre - node». Dette kalles også
speilvendt postorden. Dermed kan omvendtPreString
kodes slik:
private static <T> void omvendtPreorden(Node<T> p, StringJoiner s) { if (p.høyre != null) omvendtPreorden(p.høyre, s); if (p.venstre != null) omvendtPreorden(p.venstre, s); s.add(p.verdi.toString()); } public String omvendtPreString() { StringJoiner s = new StringJoiner(", ", "[", "]"); if (!tom()) omvendtPreorden(rot, s); return s.toString(); }
Oppgave 3D
Lengden på en gren er antall noder i grenen. Den korteste grenen er den med færrest antall noder. Hvis det er flere av dem, skal den som ligger lengst til venstre velges. Den lengste grenen er den med størst antall noder. Hvis det er flere av dem, skal den lengst til høyre velges.
1. Kortest gren: 15, 4, 2 Lengst gren: 15, 4, 8, 12, 13.
Her vil kanskje noen tenke at hvis en lager én tegnstreng for hver gren (f.eks. slik som i Oblig 3), så vil den korteste tegnstrengen representere den korteste grenen og den lengste tegnstrengen den lengste grenen. Men det vil ikke virke. Det kunne ha virket hvis hver nodeverdi f.eks. var en bokstav. Men datatypen T er generisk og dermed kan vi ikke vite hva nodeverdiene er. En nodeverdi gjøres om til en tegnsteng ved hjelp av verdiens toString-metode. Lengden på den kan vi ikke vite noe om. Hvis T f.eks. er klassen Person, vil nodeverdiens tegnstreng bli fornavn + etternavn.
Her er det nyttig å ha en hjelpemetode som lager en tegnstreng av grenen til en bladnode:
private String gren(T bladnodeverdi) { Node<T> p = rot; StringJoiner s = new StringJoiner(", ", "[", "]"); while (p != null) // søker etter bladnodeverdi som ligger i en bladnode { s.add(p.verdi.toString()); p = comp.compare(bladnodeverdi, p.verdi) < 0 ? p.venstre : p.høyre; } return s.toString(); }
2. Traverserer vi treet i nivåorden vil den første bladnoden vi kommer til være den som hører
til den korteste grenen:
public String kortestGren() { if (tom()) return "[]"; Kø<Node<T>> kø = new TabellKø<>(); Node<T> p = rot; kø.leggInn(p); while (true) // et ikke-tomt tre har alltid en bladnode { p = kø.taUt(); if (p.venstre == null && p.høyre == null) break; // den første bladnoden if (p.venstre != null) kø.leggInn(p.venstre); if (p.høyre != null) kø.leggInn(p.høyre); } return gren(p.verdi); }
3. Traverserer vi treet i nivåorden vil den siste noden vi kommer til være bladnoden som hører
til den lengste grenen:
public String lengstGren() { if (tom()) return "[]"; Kø<Node<T>> kø = new TabellKø<>(); Node<T> p = rot; kø.leggInn(p); while (!kø.tom()) { p = kø.taUt(); if (p.venstre != null) kø.leggInn(p.venstre); if (p.høyre != null) kø.leggInn(p.høyre); } return gren(p.verdi); }
Hvis en ikke har observert at den korteste grenen hører til den første og den lengste til den siste bladnoden i nivåorden, så kan oppgaven likevel løses. Det kan gjøres på mange måter. Det enkleste er nok å traversere rekursivt. Da er det lett (ved hjelp av en parameter) å holde styr på nivåene som bladnodene befinner seg på. Hvis en kommer til en bladnode som ligger lenger ned enn den tidligere nederste, er det bare å notere nivået og nodeverdien.
Til dette formålet kan vi f.eks. lage en liten hjelpeklasse med navn BladNode:
private static class BladNode<T> { private int nivå = 0; private T verdi = null; }
Flg. rekursive hjelpemtode gjør som beskrevet over:
private static <T> void lengstGren(Node<T> p, int nivå, BladNode<T> blad) { if (p.venstre == null && p.høyre == null) // p er en bladnode { if (nivå >= blad.nivå) // større nivå enn før? { blad.nivå = nivå; // oppdaterer nivået blad.verdi = p.verdi; // oppdaterer verdien } } if (p.venstre != null) lengstGren(p.venstre, nivå + 1, blad); if (p.høyre != null) lengstGren(p.høyre, nivå + 1, blad); }
Metoden lengstGren kan da kodes slik:
public String lengstGren() { if (tom()) return "[]"; BladNode<T> blad = new BladNode(); lengstGren(rot, 0, blad); return gren(blad.verdi); // hjelpemetode som er laget tidligere
I metoden kortestGren snur vi ulikheten:
private static <T> void kortestGren(Node<T> p, int nivå, BladNode<T> blad) { if (p.venstre == null && p.høyre == null) // p er en bladnode { if (nivå < blad.nivå) // mindre nivå enn før? { blad.nivå = nivå; // oppdaterer nivået blad.verdi = p.verdi; // oppdaterer verdien } } if (p.venstre != null) kortestGren(p.venstre, nivå + 1, blad); if (p.høyre != null) kortestGren(p.høyre, nivå + 1, blad); } public String kortestGren() { if (tom()) return "[]"; BladNode<T> blad = new BladNode(); blad.nivå = Integer.MAX_VALUE; kortestGren(rot, 0, blad); return gren(blad.verdi); }