Oppgave 1A
La m være indeksen til første element i den andre halvdelen. Hvis en bytter
om elementene på indeks 0 og indeks m, så bytter om de på indeks 1 og
indeks m + 1 osv, vil første og andre halvdel bli byttet om:
public static void halvbytt(int[] a) { if ((a.length & 1) != 0) // sjekker lengden throw new IllegalArgumentException("Ikke partallslengde!"); int m = a.length/2; // finner midten for (int i = 0; i < m; i++) { int temp = a[i]; a[i]= a[i + m]; a[i + m] = temp; } }
Hvis en bruker en bytt-metode i klassen Tabell fra hjelpeklasser, blir koden
litt kortere:
public static void halvbytt(int[] a) { if ((a.length & 1) != 0) // sjekker lengden throw new IllegalArgumentException("Ikke partallslengde!"); int m = a.length/2; // finner midten for (int i = 0; i < m; i++) Tabell.bytt(a, i, i + m); }
Oppgave 1B
Ali, Per, Kari, Knut, Anton, Anders, Jasmin, Hansine
public class StringKomparator implements Comparator<String> { public int compare(String s, String t) { int k = s.length() - t.length(); if (k != 0) return k; return s.compareTo(t); } } // class StringKomparator
Oppgave 1C
Flg. metode bruker en hjelpestakk C:
public static <T> void kopier(Stakk<T> A, Stakk<T> B) { Stakk<T> C = new TabellStakk<>(); // en hjelpestakk while (!A.tom()) C.leggInn(A.taUt()); // flytter fra A til C while (!C.tom()) // tar fra C og legger i både A og B { T t = C.taUt(); A.leggInn(t); B.leggInn(t); } }
OBS: Det er flere som har forsøkt å løse denne oppgaven ved hjelp av en tabell. Dvs. ved å flytte alle verdiene fra stakken A over i en tabell
og så hente verdiene fra tabellen i motsatt rekkefølge og legge dem inn A og B. Det de fleste da glemmer er
at kode av formen: T[] a = new T[A.antall()] ikke er tillatt i Java. Det er ikke tillatt å opprette generiske tabeller. Isteden må
det gjøres på denne måten: T[] a = (T[]) new Object[A.antall()];
Oppgave 2A
I denne oppgaven må en ha forklaringer på de svarene en setter opp! Selvfølgelig ikke nødvendigvis så omfattende som det nedenfor, men en del må det være.
Koden består av to løkker. I den innerste løkken sammenlignes temp = a[i] fortløpende med
verdiene til venstre for indeks i. Verdiene forskyves (a[j+1] = a[j]) inntil rett
sortert plass for temp er funnet. Der settes den inn. Tabellen a er med andre ord todelt
under algoritmen. Den første i den usorterte delen settes på rett sortert plass i den sorterte delen.
Innholdet i tabellen a endrer seg slik gjennom de fire iterasjonen i ytterste løkke:
Start: 5 3 4 1 2 1. runde: 3 5 4 1 2 2. runde: 3 4 5 1 2 3. runde: 1 3 4 5 2 4. runde: 1 2 3 4 5
Koden som er satt opp, er rett og slett «innmaten» i innsettingssortering (eng: insertion sort). Denne algoritmen er tatt opp flere ganger i pensum (og undervisningen) - første gang i Avsnitt 1.3.12.
Når det gjelder effektivitet eller orden for en algoritme ser en vanligvis på 1) det verste tilfellet, 2) det gjennomsnittlige tilfellet og 3) det beste tilfellet. Anta at tabellen har lengde n. Det verste tilfellet er når tabellen er sortert avtagende. Da vil det i runde nr i i ytterste løkke bli utført i sammenligninger i innerste løkke. Dermed 1 + 2 + . . . + n-1 = n(n - 1)/2 sammenligninger. Det betyr at algoritmen er av kvadratisk orden (orden n2 ). Det beste tilfellet er når tabellen er sortert stigende. Da blir det i hver runde kun utført én sammenligning. Tilsammen n - 1. I detter tilfellet er algoritmen av lineær orden (orden n). I gjennomsnitt, hvis tabellen er tilfeldig og alle verdiene er forskjellige, vil hver ny verdi i gjennomsnitt havne på midten av den sorterte delen. Det betyr ca. 1/2 + 2/2 + 3/2 + . . . + (n-1)/2 = n(n - 1)/4 sammenligninger. Med andre ord er algoritmen i gjennomsnitt av kvadratisk orden (orden n2 ).
Oppgave 2B
Et komplett binærtre er et binærtre der alle nivåene bortsett fra det nederste har så mange noder det er plass til. På nederste nivå kan det være færre enn det er plass til, men det må være fylt opp med noder fre venstre.
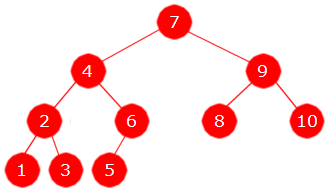 |
Oppgave 2C
Algoritmen for innsetting i et 2-3-4 tre står i vedlegget til eksamensoppgaven.
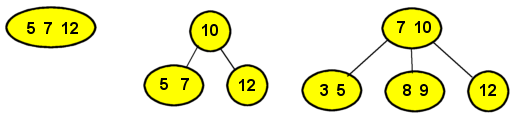 |
Oppgave 3A
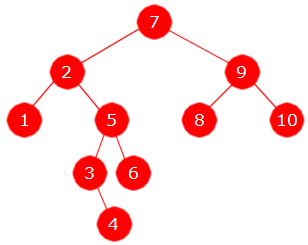 |
| Innsetting av 7, 2, 9, 1, 5, 8, 10, 3, 6, 4 |
Nivåorden: 7 2 9 1 5 8 10 3 6 4
Preorden: 7 2 1 5 3 4 6 9 8 10
Oppgave 3B
I Oppgave 3 handler det om et binært søketre. Hovedpoenget med denne datastrukturen er at
innsetting, søking og fjerning i gjennomsnitt er av logaritmisk orden. Spesielt er det
viktig at søking er logaritmisk. Noen har valgt å kode metoden inneholder på samme måte
som i et generelt binærtre, dvs. ved en rekursiv (eller iterativ) traversering av hele treet inntil
en eventuelt finner verdien. Dette vil en kunne få noe for, men her er poenget å vise at en
har forstått den spesielle strukturen i et binært søketre. Idéen en skal bruke
er forøvrig den samme som i innleggingsalgoritmen. Den står i vedlegget.
public boolean inneholder(T verdi) { if (verdi == null) return false; // treet har ikke null-verdier Node<T> p = rot; // starter i roten while (p != null) // sjekker p { int cmp = comp.compare(verdi,p.verdi); // sammenligner if (cmp < 0) p = p.venstre; // går til venstre else if (cmp > 0) p = p.høyre; // går til høyre else return true; // cmp == 0, funnet } return false; // ikke funnet }
Oppgave 3C
Den første verdien i postorden er den som ligger i første bladnode p fra venstre, dvs. verdien 1. Når forelder til p har et høyre barn, er den neste i postorden den første bladnoden i subtreet med dette høyre barnet som rotnode. Dvs. den andre verdien i postorden er 4.
Generelt gjelder at hvis p er den første i postorden og q er dens forelder, så er q den neste til p i postorden hvis q kun har p som barn. Hvis q har to barn, må nødvendigvis p være det venstre barnet. Da er den neste til p i postorden den første bladnoden i det treet som har søskennoden til p som rotnode. Flg. tegninger viser de tre mulighetene:
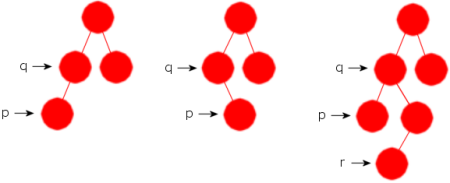 |
| 1) q er den neste til p 2) q er den neste til p 3) r er den neste til p |
Poenget her er å kode metoden andrePostorden så effektivt som mulig.
Hvis en ikke klarer å finne andre teknikker, kan en nødløsning
være å traversere treet i postorden. Hvis en da tar vare på alle verdiene, vil den andre verdien være den aktuelle.
Dette blir ineffektivt, men en vil likevel kunne få noe for en slik løsning. Dette kan lages slik:
public T andrePostorden() { if (antall() < 2) throw new NoSuchElementException("For få verdier!"); Liste<T> liste = new TabellListe<>(); andrePostorden(rot, liste); return liste.hent(1); } // rekursiv hjelpemetode som traverserer i postorden private static <T> void andrePostorden(Node<T> p, Liste<T> liste) { if (p.venstre != null) andrePostorden(p.venstre, liste); if (p.høyre != null) andrePostorden(p.høyre, liste); liste.leggInn(p.verdi); }
Dette kan imdlertid forbedres vesentlig. Vi kan stoppe traverseringen når listen har fått to verdier. Det får vi til ved kun én setning ekstra i den rekursive hjelpemetoden. I tillegg kan det lages slik at listen får kun to verdier. Dette vil gi en algoritme av logaritmisk orden:
// rekursiv hjelpemetode som traverserer i postorden private static <T> void andrePostorden(Node<T> p, Liste<T> liste) { if (liste.antall() > 1) return; // stopper traverseringen if (p.venstre != null) andrePostorden(p.venstre, liste); if (p.høyre != null) andrePostorden(p.høyre, liste); if (liste.antall() < 2) liste.leggInn(p.verdi); }
Det er ikke mulig å lage en metode som er mer effektiv enn logaritmisk orden, men det er mulig å lage en som er mer direkte og dermed litt bedre:
public T andrePostorden() { if (antall() < 2) throw new NoSuchElementException(); Node<T> p = rot, q = null; // q skal være forelder til p while (true) { if (p.venstre != null) { q = p; p = p.venstre; } else if (p.høyre != null) { q = p; p = p.høyre; } else break; } // p er nå den første i postorden og q er forelder til p // Hvis q har kun ett barn, er q den som kommer etter p i postorden. // Hvis q har to barn, må vi lete etter den neste. if (q.venstre != null && q.høyre != null) // q har to barn { q = q.høyre; while (true) // finner første bladnode { if (q.venstre != null) q = q.venstre; else if (q.høyre != null) q = q.høyre; else break; } } return q.verdi; // andre verdi i postorden }
Oppgave 3D
Vi kan lage en kopi hvis vi har verdiene fra det opprinnelige treet i en rekkefølge som er slik at vi får et maken tre hvis det bygges opp (ved hjelp av leggInn-metoden) i den rekkefølgen. Da er spørsmålet: Hvilken rekkefølge av verdier vil gi det samme treet. Da kan vi f.eks. bruke preorden eller nivåorden (men ikke inorden og postorden). Da får vi en metode som er av orden nlog(n). Men det er mulig å få det til med en metode av orden n. Se lenger ned.
OBS: Metoden public static <T> SBinTre<T> kopi(SBinTre<T> tre)
er i oppgaveteksten satt opp i klassen SBinTre. Dette fremkommer også av kodeeksemplet siden
det der står SBinTre.kopi(tre). Det betyr at de private delene av en instans av klassen kan aksesseres direkte.
Hjelpemetoden nedenfor skal også
ligge i klassen SBinTre.
// En rekursiv metode som traverserer det originale treet i // preorden og bygger opp kopitreet i samme rekkefølge private static <T> void kopi(Node<T> p, SBinTre<T> kopi) { kopi.leggInn(p.verdi); if (p.venstre != null) kopi(p.venstre, kopi); if (p.høyre != null) kopi(p.høyre, kopi); } public static <T> SBinTre<T> kopi(SBinTre<T> tre) { if (tre == null) return null; SBinTre<T> kopi = new SBinTre<>(tre.comp); // et tomt tre if (!tre.tom()) kopi(tre.rot,kopi); // kaller metoden over return kopi; }
Hvis vi ønsker å bruke nivåorden, må vi bruke en kø:
public static <T> SBinTre<T> kopi(SBinTre<T> tre) { if (tre == null) return null; SBinTre<T> kopi = new SBinTre<>(tre.comp); // et tomt tre if (tre.tom()) return kopi; Kø<Node<T>> kø = new TabellKø<>(); kø.leggInn(tre.rot); while (!kø.tom()) { Node<T> p = kø.taUt(); kopi.leggInn(p.verdi); if (p.venstre != null) kø.leggInn(p.venstre); if (p.høyre != null) kø.leggInn(p.høyre); } return kopi; }
Kopieringen kan også gjøres ved hjelp av flg. «splitt og hersk»-idé: Kopier først høyre
subtre, så venstre subtre og til slutt noden. Da får vi en metode av orden n. Skal flg. metode
virke må det være en ekstra konstruktør i nodeklassen, dvs. en konstruktør som har en verdi
og to nodepekere som paramtere. Obs: Den rekursive metoden oppdaterer ikke variabelen antall:
private static <T> Node<T> kopi(Node<T> p) { if (p == null) return null; // ingenting å kopiere return new Node<>(p.verdi,kopi(p.venstre),kopi(p.høyre)); } public static <T> SBinTre<T> kopi(SBinTre<T> tre) { if (tre == null) return null; SBinTre<T> kopi = new SBinTre<>(tre.comp); // et tomt tre kopi.rot = kopi(tre.rot); kopi.antall = tre.antall; return kopi; }